-
-
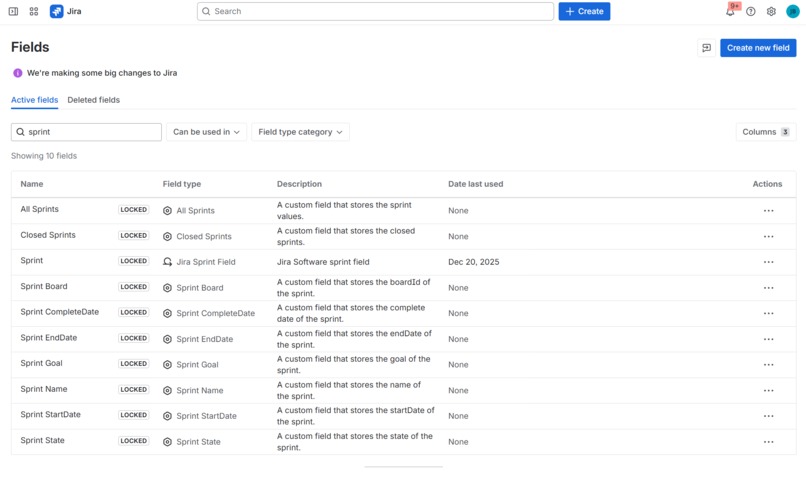
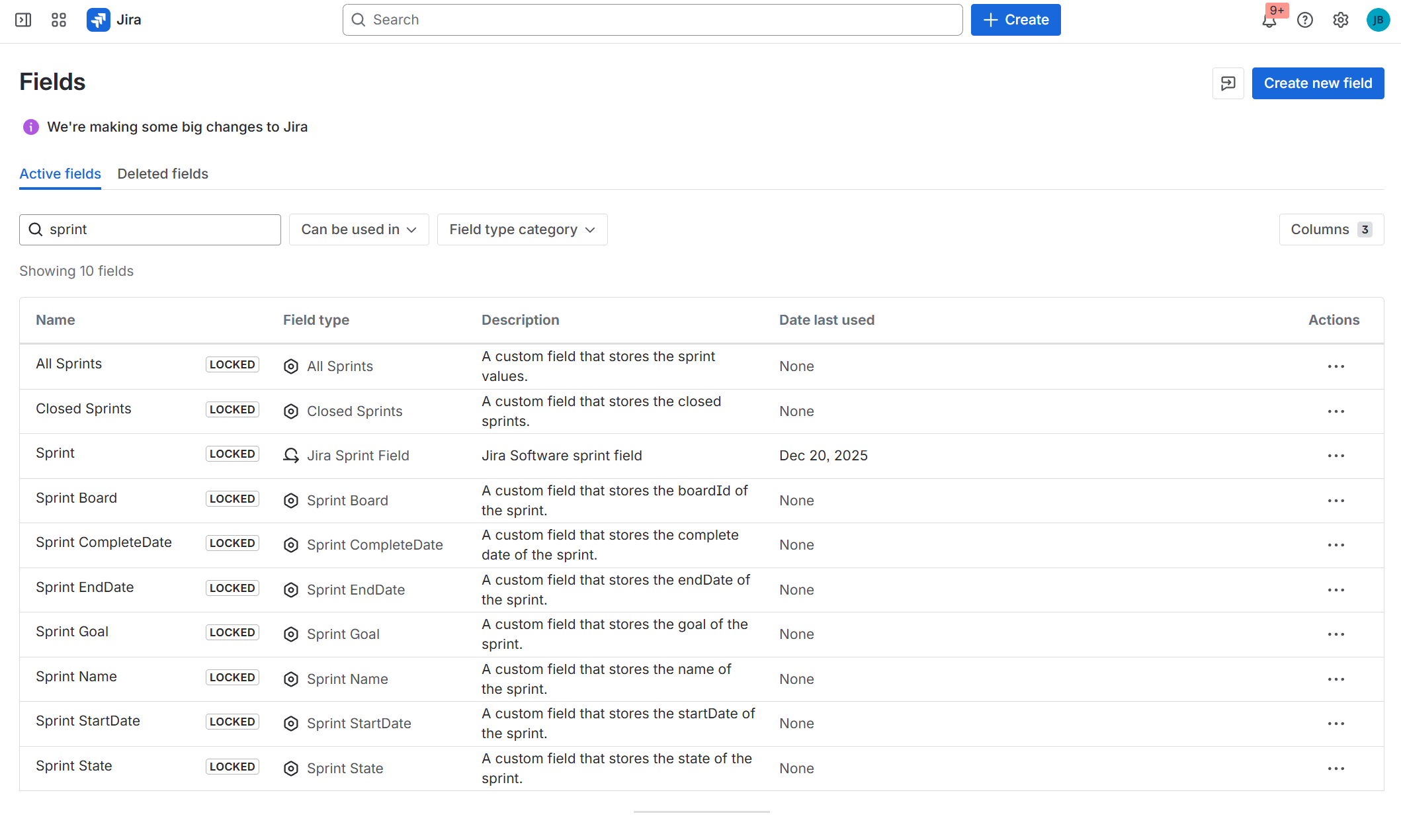
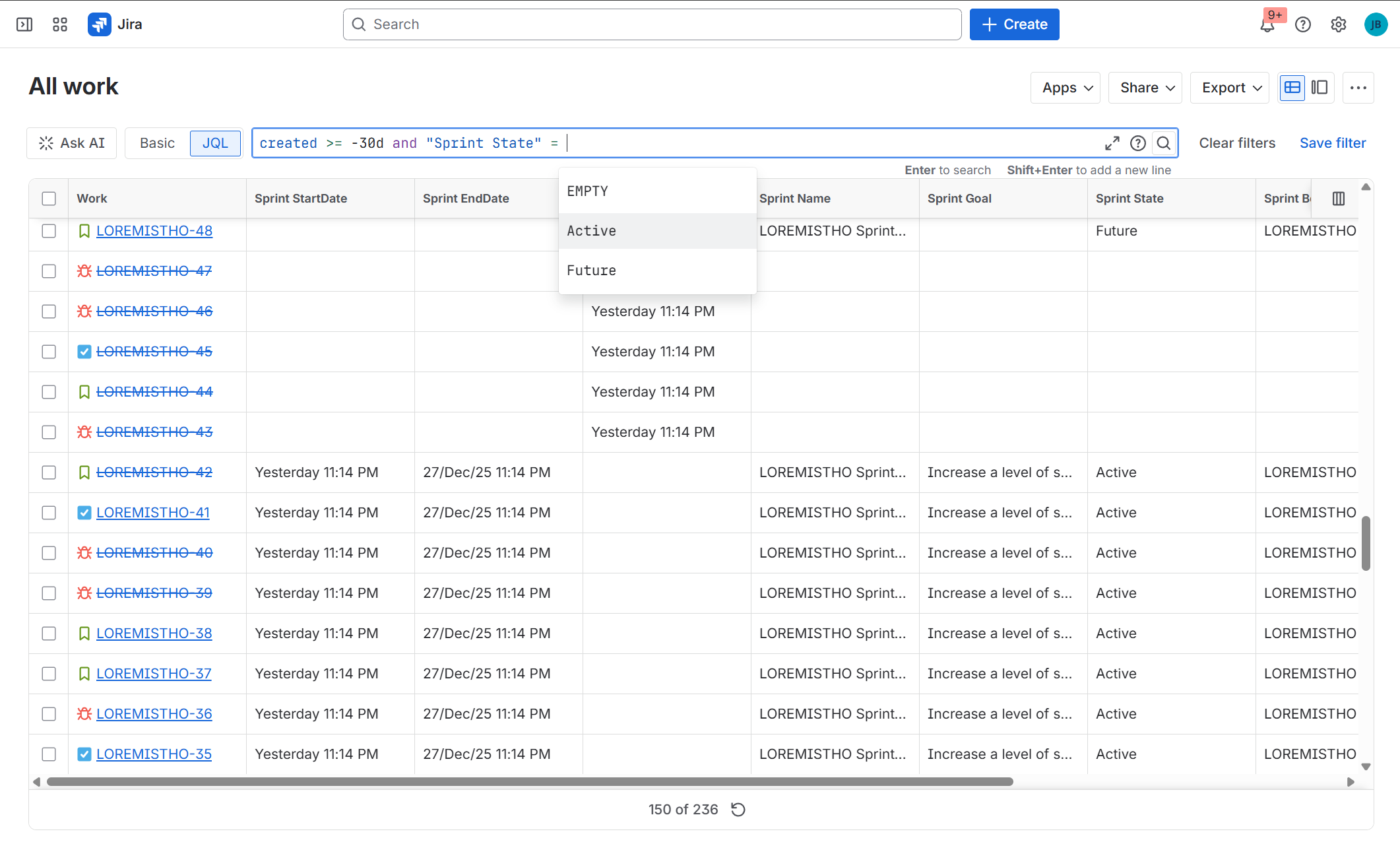
9 custom fields with information about sprints
-
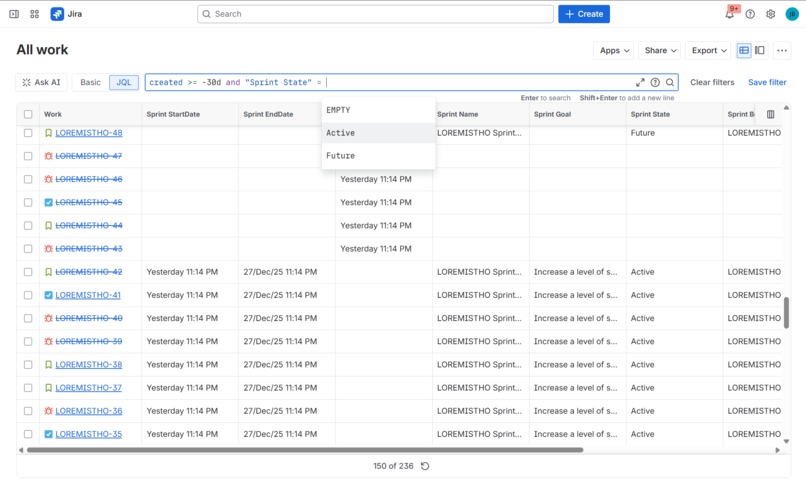
All custom field are available for search in filters
-
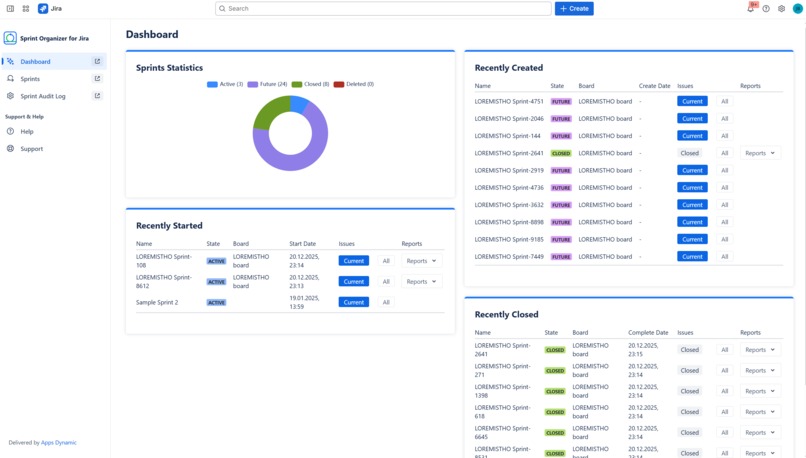
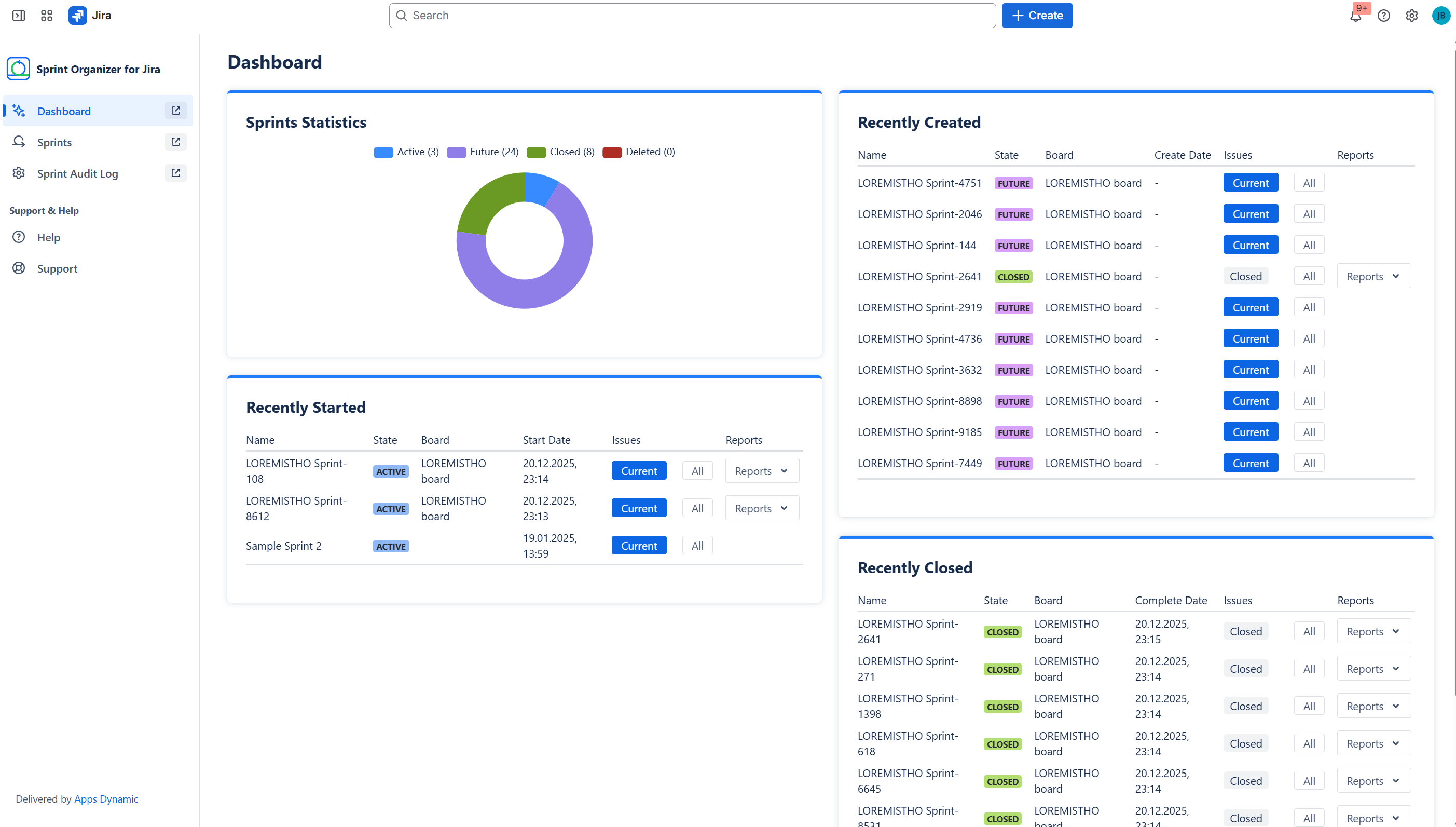
Admin Dashboard agregating data about all Sprints in Jira
-
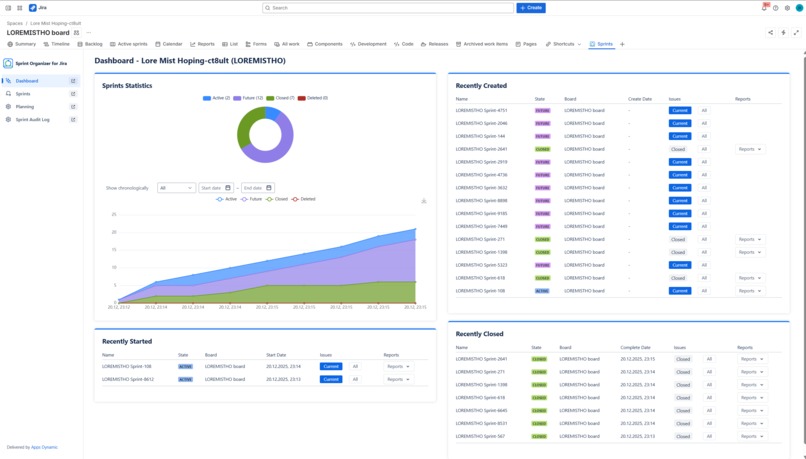
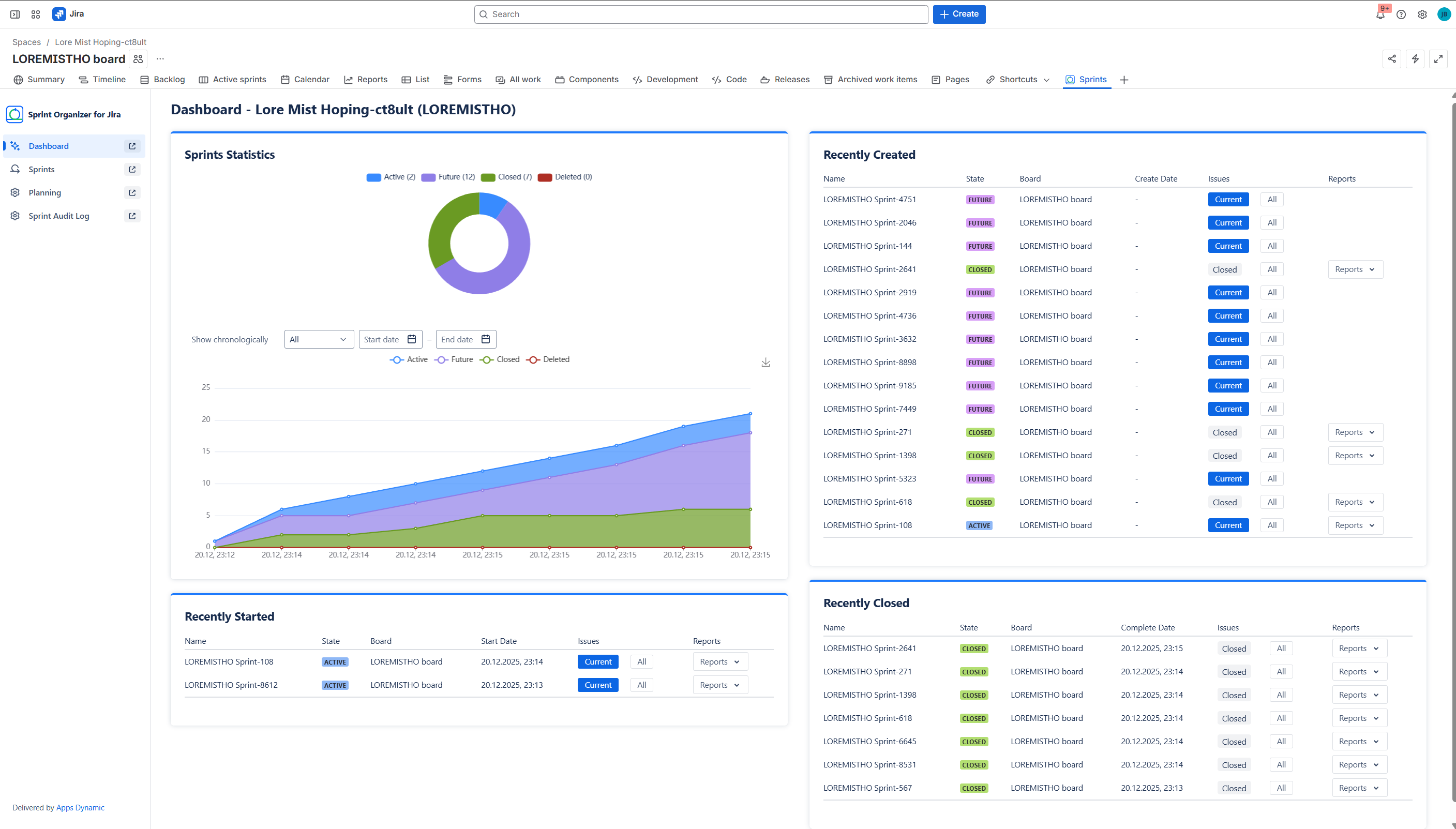
Project Dashboard agregating data about all Sprints in Jira
-
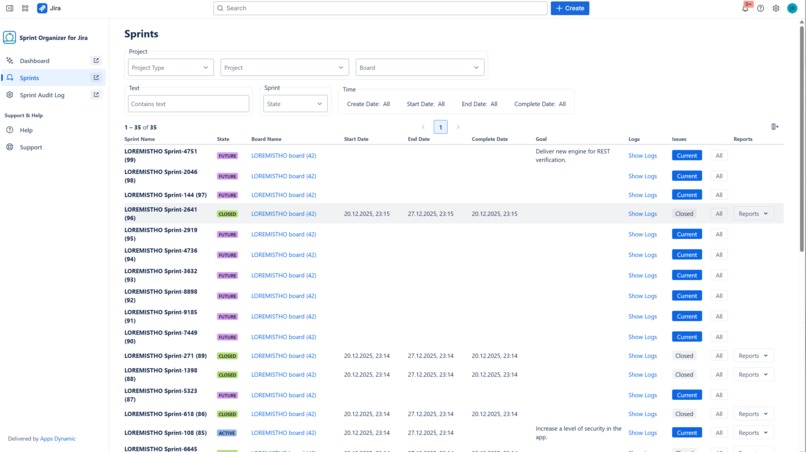
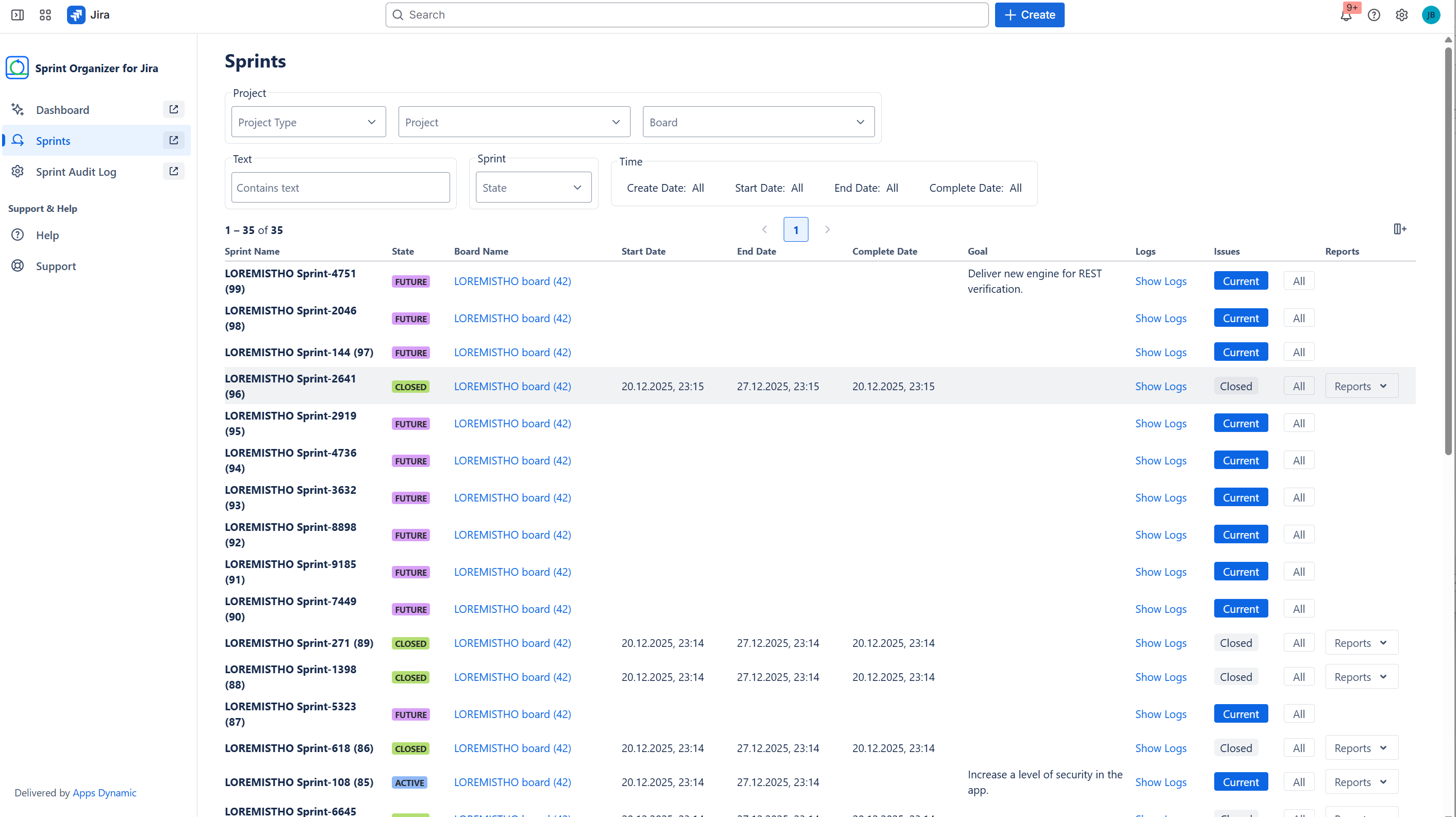
Browse all sprints with powerful filters
-
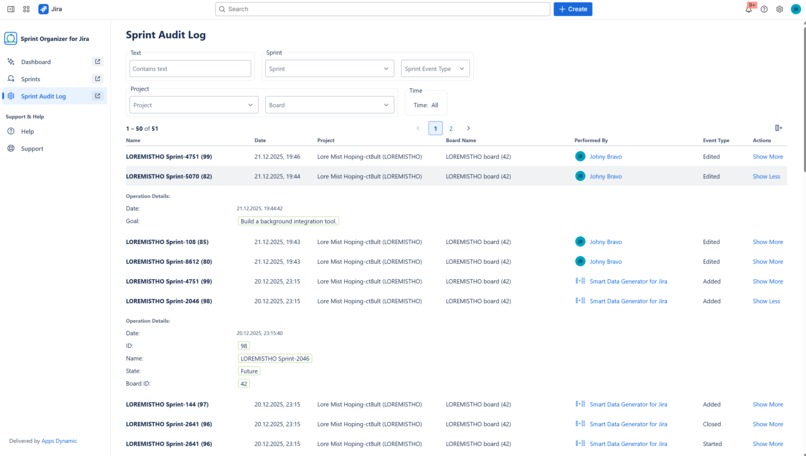
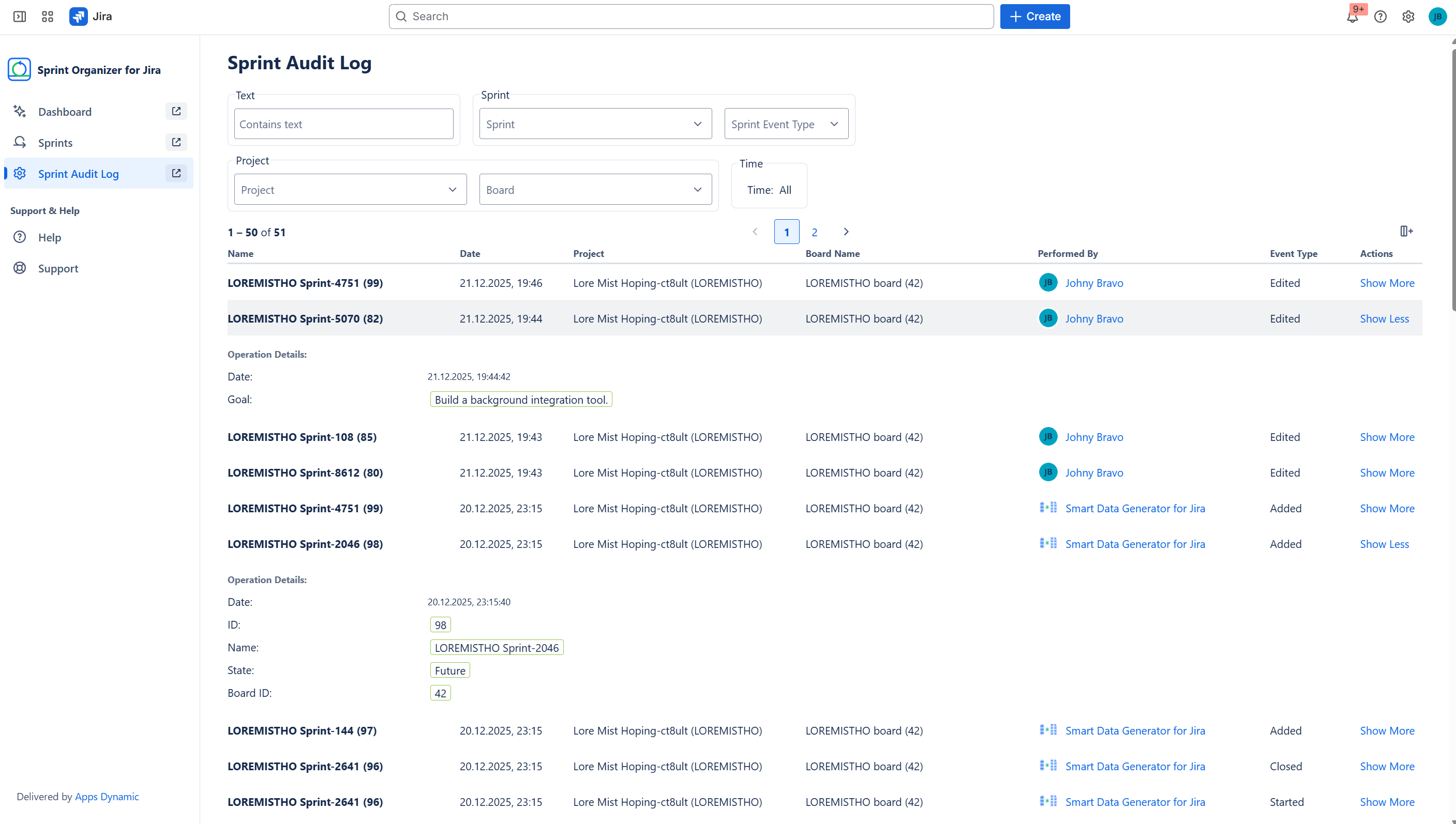
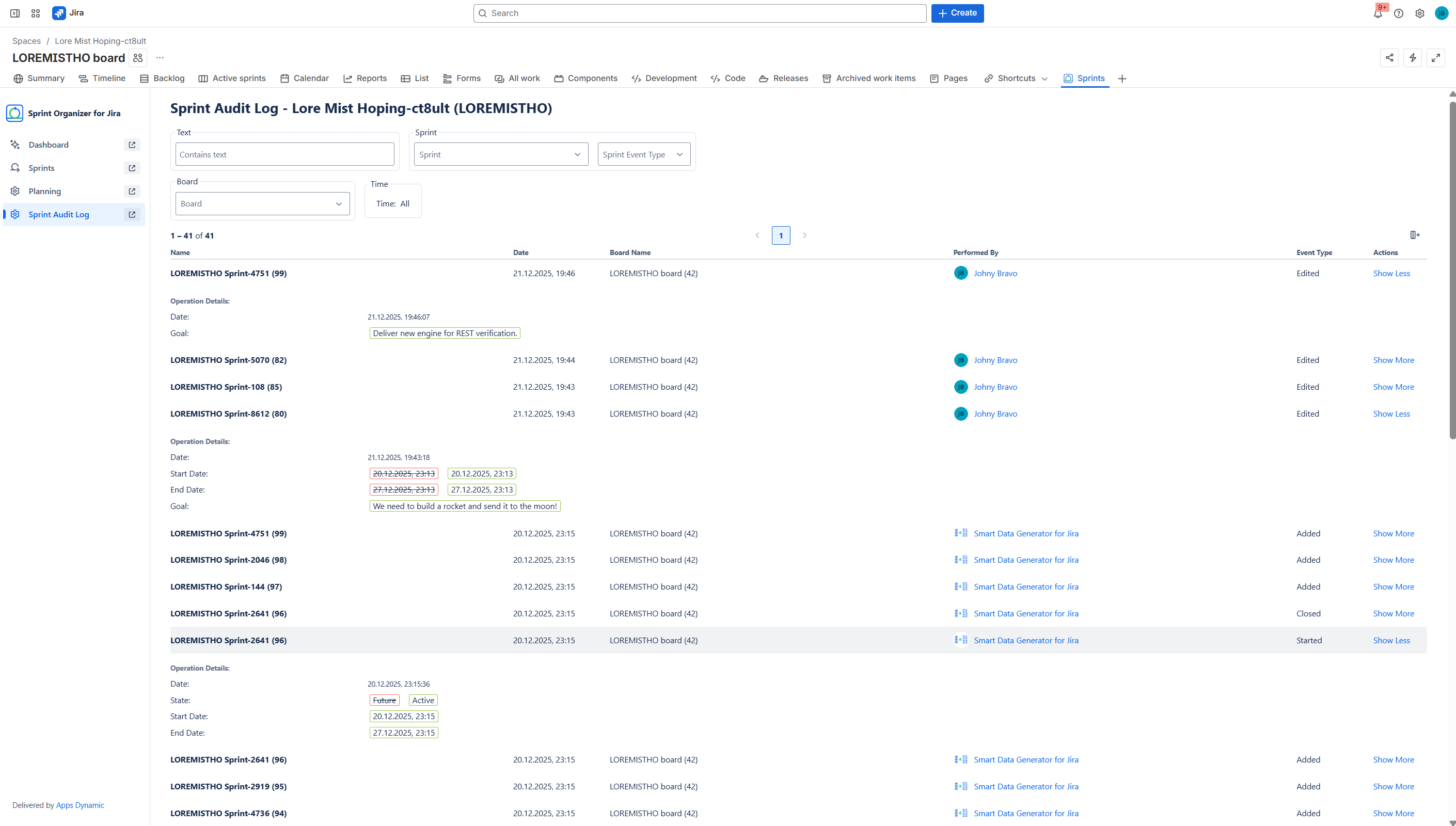
Audit every sprint change
-
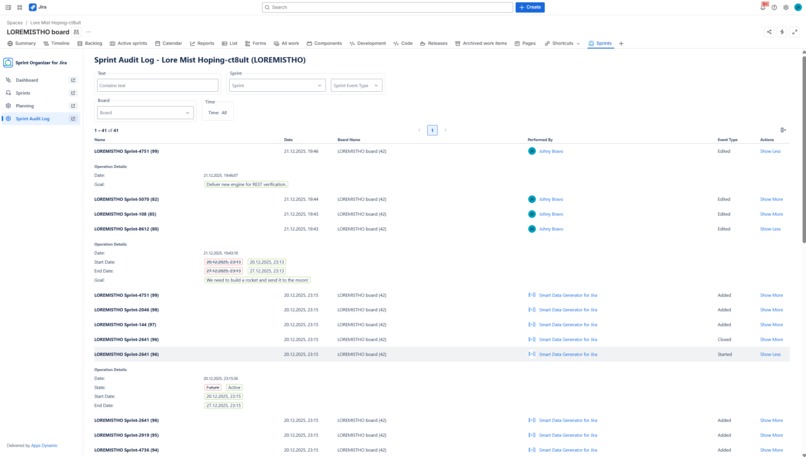
Audit log details
-
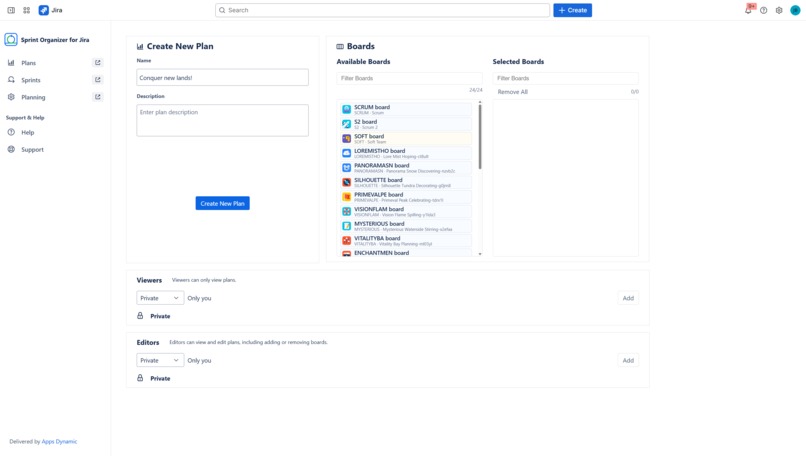
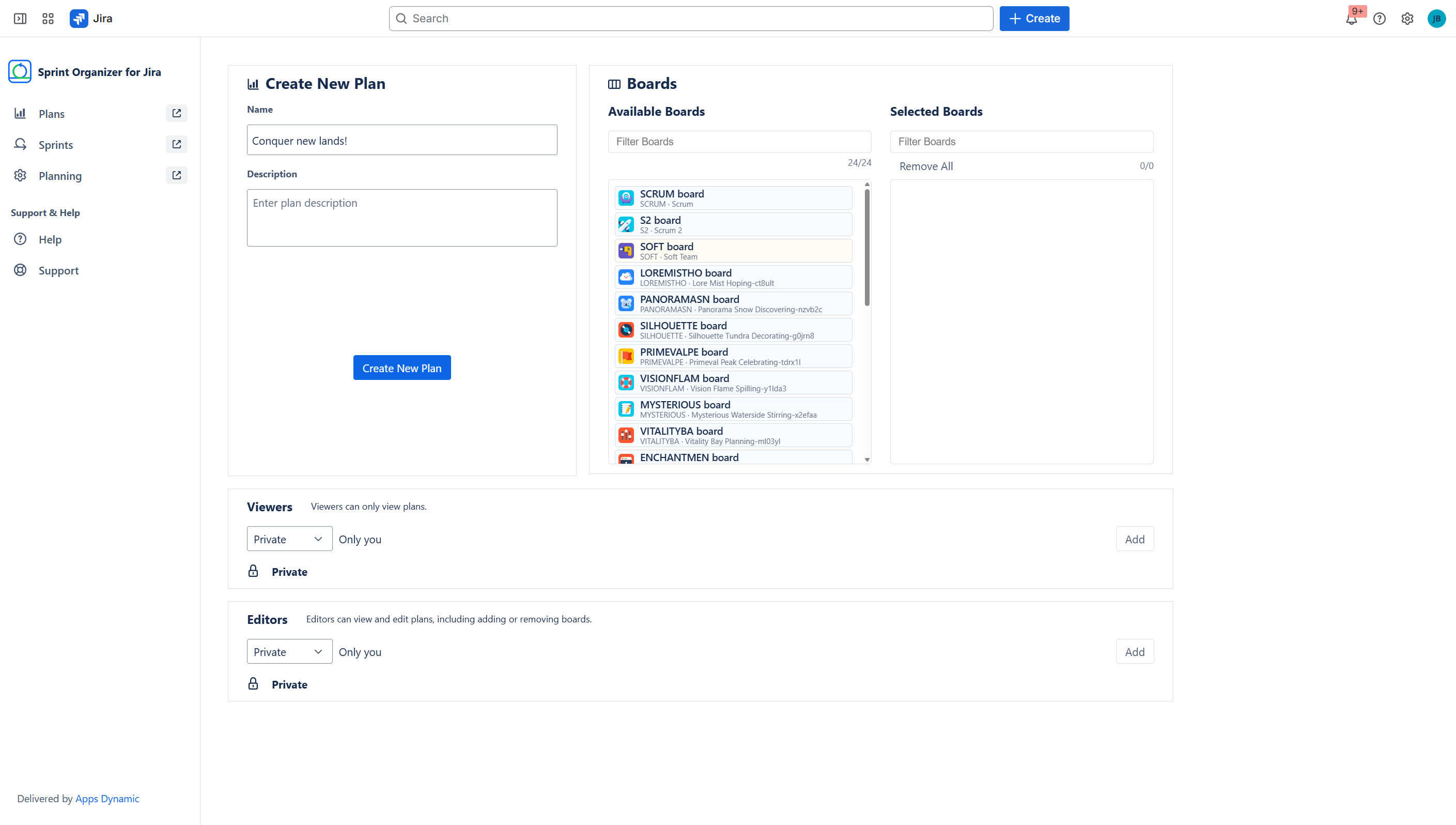
Create a plan with context of cross-projects boards
-
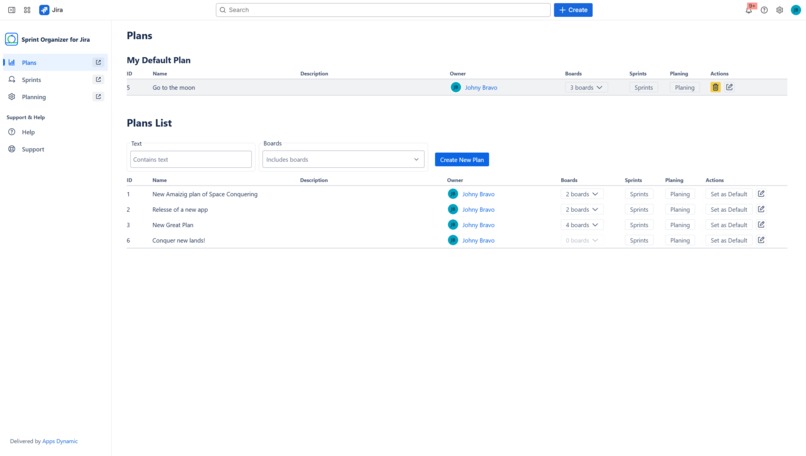
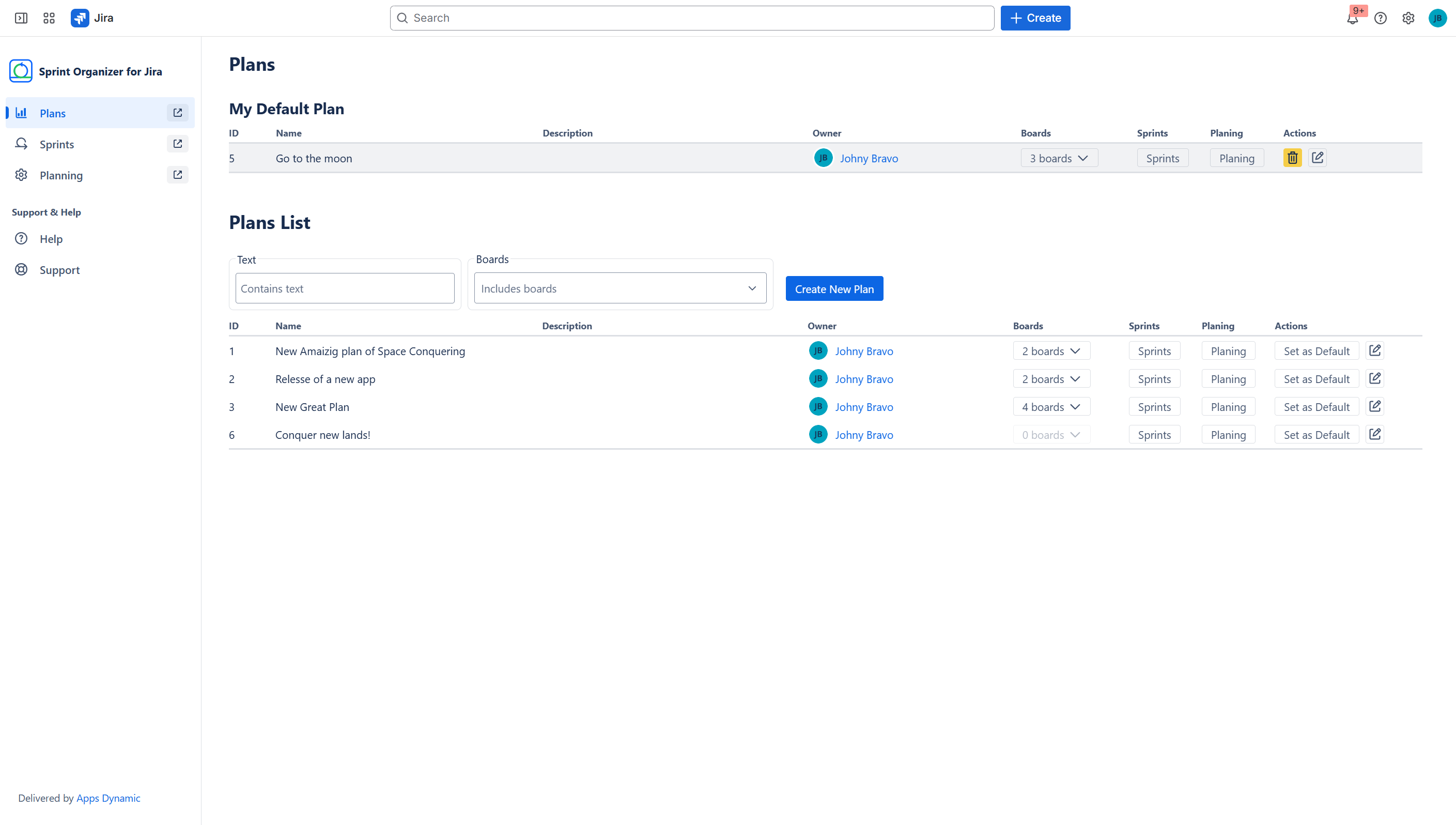
Manage global list of Plans
-
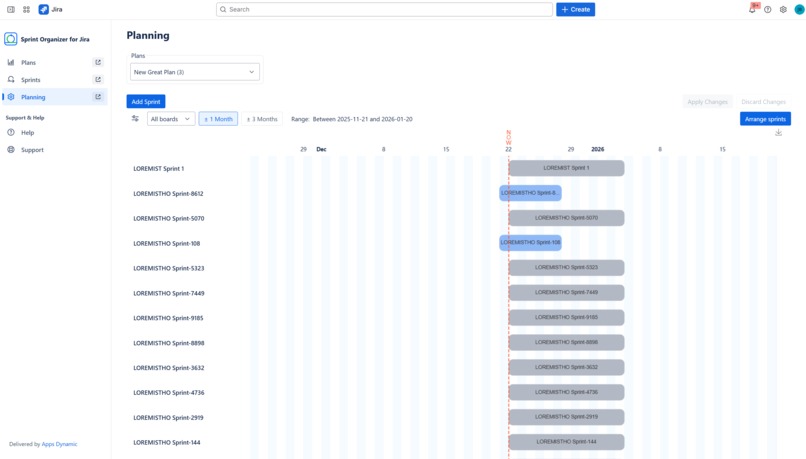
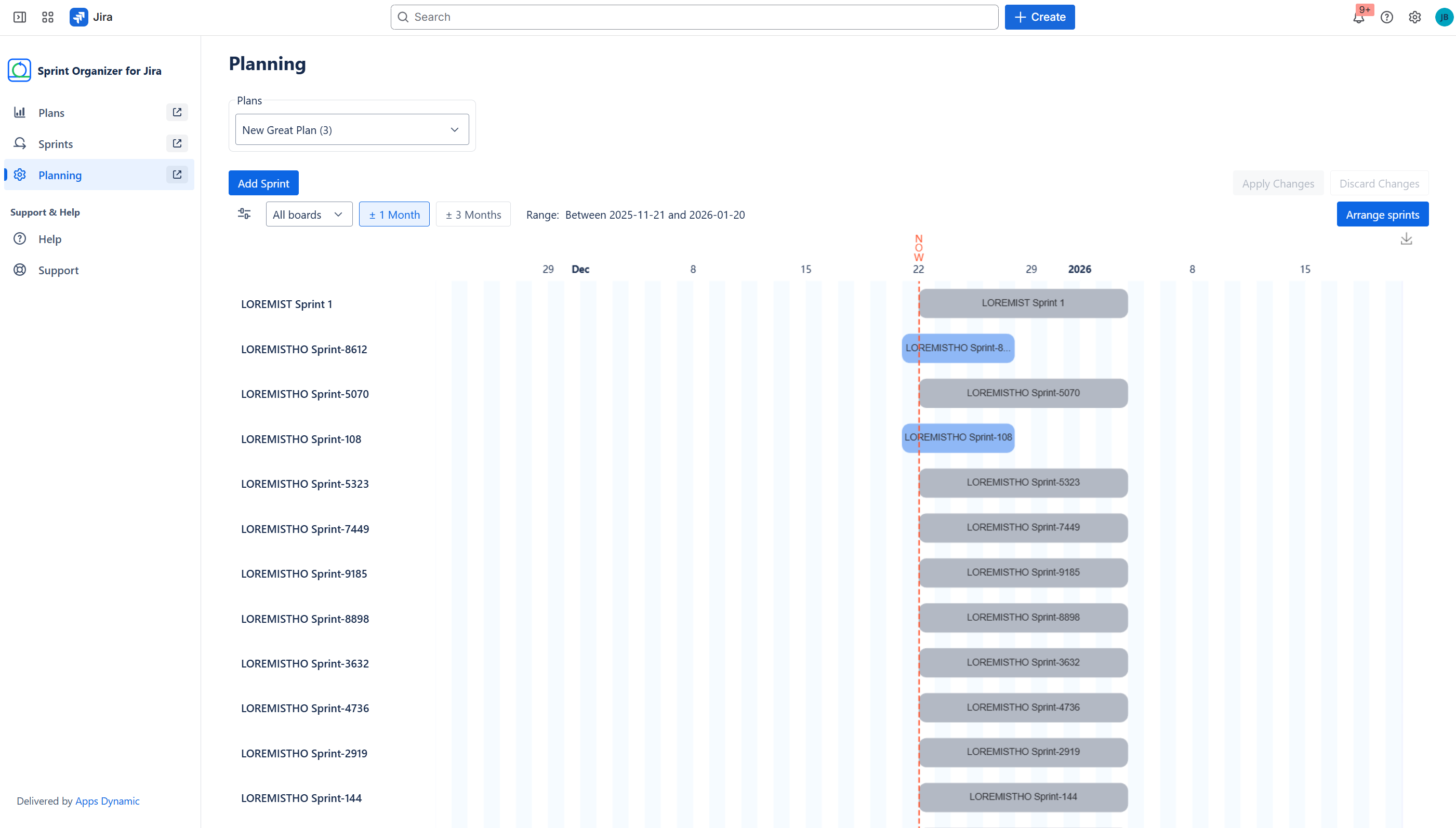
Organize Sprints within a plan
-
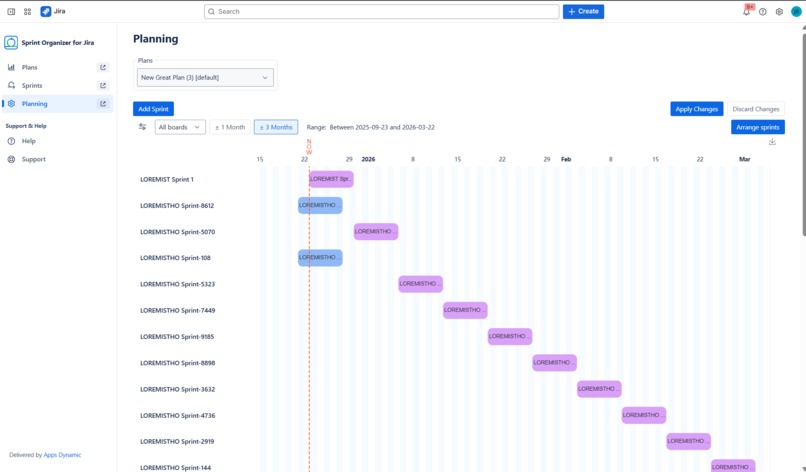
Auto Sprints arrangement
Inspiration
Everything started with a recurring and long-standing customer need: the ability to search and report on issues based on sprint attributes.
For many years, Jira Cloud users have been asking Atlassian for native support to query issues by sprint characteristics such as sprint dates, state, goal, or board context. Two long-running public tickets clearly illustrate this demand:
Despite being reported years ago and receiving sustained community interest, these gaps remain unaddressed in Jira Cloud.
As a result, teams still cannot reliably:
- build JQL filters based on sprint state, dates, or goals,
- create dashboards reflecting sprint-level context,
- perform historical analysis of sprint participation and timelines.
This forced organizations to rely on workarounds, manual tracking, or external tools—and exposed a deeper issue: sprint data is not treated as a first-class, queryable concept in Jira.
While addressing this limitation, we repeatedly encountered broader challenges around sprint visibility and coordination. Jira boards work well in isolation, but once teams operate across multiple boards, projects, and timelines, sprint management becomes fragmented. There is no native way to view sprint timelines across boards, plan future sprints centrally, or audit sprint changes over time.
We searched the Atlassian Marketplace for a solution that would combine sprint searchability, planning, and governance, but existing tools focused either on reporting after the fact or on high-level roadmaps detached from real Jira sprints.
This led us to build Sprint Organizer for Jira—a solution that exposes sprint metadata to issues, adds auditability and governance, and enables structured sprint planning across Jira Cloud.
What it does
Sprint Organizer for Jira provides centralized visibility, planning, and governance for sprints in Jira Cloud, starting with making sprint data directly available on issues.
Sprint Custom Fields (JQL-enabled)
The app delivers a dedicated set of custom fields that expose sprint metadata at the issue level and can be used in JQL, dashboards, filters, and reports:
- Sprint Name – name of the current Active/Future sprint
- Sprint State – state of the current sprint (Future / Active)
- Sprint Goal – sprint goal
- Sprint Start Date – start date of the current Future/Active sprint
- Sprint End Date – end date of the current Future/Active sprint
- Sprint Complete Date – completion date of the last closed sprint
- Sprint Board – origin board ID of the current sprint
- Closed Sprints – closed sprints the issue participated in
- All Sprints (was in) – full sprint history of the issue
These fields are updated asynchronously and allow teams to finally:
- search issues by sprint attributes,
- build sprint-aware dashboards,
- perform historical sprint analysis using native Jira tooling.
Sprint Visibility and Monitoring
On top of exposed sprint data, Sprint Organizer provides real-time visibility into sprint lifecycles:
- tracks Future, Active, Closed, and Deleted sprints,
- includes deleted sprint tracking starting from app installation,
- offers dashboards with sprint statistics and recent activity.
Cross-board Sprint Planning with Plans
Sprint Organizer introduces Plans—containers that aggregate sprints from up to 20 boards. Plans allow teams to:
- view sprints across multiple boards in one place,
- coordinate timelines across teams,
- manage permissions via Viewers and Editors.
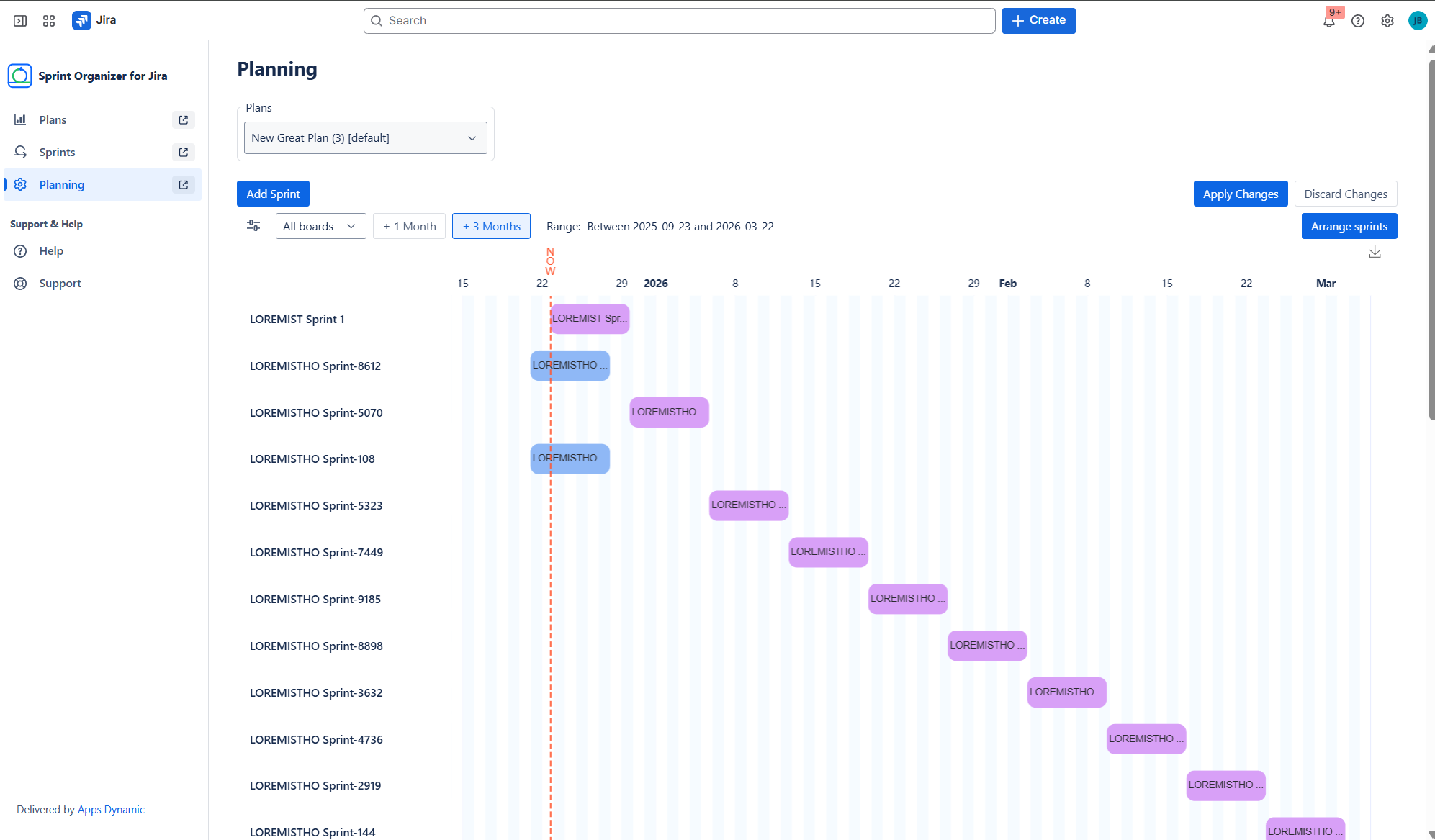
Gantt-based Sprint Planning
Using a Gantt chart and table view, teams can:
- reschedule sprint start and end dates (where Jira allows),
- adjust sprint duration with day or hour accuracy,
- create dependencies between sprints,
- manage sprint order and parallel execution,
- stage changes and apply or discard them safely.
Audit Logs and Governance
All sprint-related changes are tracked and auditable:
- Global Audit Log – last 500 sprint changes across the instance,
- Project Audit Log – last 500 changes scoped to a project,
- covers creation, edits, start, close, and deletion events,
- provides detailed change previews for transparency and compliance.
Sprint Organizer does not replace Jira boards or sprint mechanics.
It adds a search, planning, and governance layer on top of native Jira sprints, ensuring sprint data remains accessible, traceable, and manageable at scale.
How we built it
Sprint Organizer for Jira is a Jira Cloud application built on Atlassian Forge, fully aligned with the Runs on Atlassian model. All execution and data processing remain within Atlassian infrastructure.
Core principles:
- strict adherence to Jira permissions and board visibility,
- no duplication of sprint data—everything reflects native Jira state,
- separation between staged planning changes and applied execution,
- deterministic handling of sprint state transitions and date updates.
Special attention was given to:
- cross-board sprint aggregation without breaking Jira’s board model,
- performant and predictable Gantt interactions,
- full auditability of sprint operations,
- asynchronous processing of custom fields to protect Jira performance.
Challenges we ran into
Sprint data access limitations
Sprint data in Jira Cloud is exposed through a separate Agile API:
- sprints cannot be queried directly,
- sprints must be fetched per board,
- orphaned or partially accessible sprints require special handling.
Team-managed projects and Sprint field removal
In Team-managed projects, the Sprint field can be removed:
- sprint data must then be resolved per issue,
- each issue may require individual sprint lookup to update custom fields,
- this significantly increases API usage and complexity.
Custom field scalability
Custom fields must be populated for potentially very large numbers of issues:
- all issues require initial population after installation,
- values must stay in sync with sprint changes,
- reacting immediately to every event easily exceeds API limits.
To solve this:
- issues are queued for update,
- custom fields are updated in bulk batches every 30 seconds,
- this trades minimal delay for system stability.
Audit log history
To present meaningful audit logs, previous values must be available.
We initially considered Forge SQL for this purpose, but its pricing and limits proved significantly worse than Forge KVS for this access pattern.
As a result, we designed a KVS-based approach optimized for change history storage.
Gantt chart implementation
No existing Gantt library met our requirements:
- changing duration and dates,
- drag & drop rescheduling,
- dependency linking,
- accuracy modes,
- weekend highlighting.
The final solution combines:
- ECharts for rendering,
- custom React components layered on top of the chart,
- bespoke interaction logic to support all planning features.
Sprint permissions complexity
Sprint permissions in Jira are complex and not clearly documented:
- visibility depends on board, project, and sprint state,
- orphaned sprints require special handling,
- determining who can see or modify what required extensive experimentation.
Plans and permissions model
Designing Plans required balancing:
- efficient data loading,
- strict isolation of private plans,
- Viewer vs Editor permissions,
- minimal API calls while ensuring correct visibility.
Large-scale sprint views
Managing and presenting a very large number of sprints—especially on the Admin page—required careful UX decisions to ensure:
- meaningful defaults,
- strong filtering,
- usable dashboards instead of overwhelming lists.
Accomplishments that we're proud of
We delivered a solution that brings sprint-level searchability, planning, and governance to Jira Cloud despite significant platform constraints.
We are proud of:
End-to-end sprint management at scale
A comprehensive system for viewing, editing, and planning sprints that remains simple and intuitive for everyday users, while staying fast and reliable even with very large numbers of sprints and issues.Advanced, interactive Gantt planning
A custom-built Gantt chart that enables intuitive sprint planning, including:- interactive date and duration changes,
- dependency creation between sprints,
- one-click automatic sprint ordering that respects dependencies,
- support for parallel sprint execution.
Reliable custom field synchronization
A fast and robust custom field update mechanism that enables advanced JQL queries not possible with standard Jira fields, while safely operating within strict API limits.Complete sprint history control
Full visibility into sprint history, including deleted sprints, allowing comprehensive visualization, auditing, and change tracking over time.
Together, these achievements allow teams to manage sprint timelines as governed, auditable, and performant structures—rather than isolated board artifacts.
What we learned
Building Sprint Organizer for Jira significantly deepened our understanding of both Jira Cloud internals and the practical realities of developing complex products on the Forge platform.
Key learnings from this project include:
Designing Forge event triggers intentionally
How to create Forge triggers that listen to Jira events, filter them early, extract only relevant data, and react in a controlled and efficient way—rather than responding blindly to every emitted event.Efficient use of Atlassian Design Tokens (Atlaskit)
How to correctly consume Atlassian design tokens in custom components and external libraries, including integrating ECharts in a way that remains visually consistent and fully compatible with the Atlassian ecosystem.Event aggregation instead of real-time processing
How to use@forge/eventsQueue as a buffering mechanism for initialization and update tasks—aggregating changes and processing them in batches instead of reacting to individual events in real time, which is critical for scalability.Choosing the right authorization context
When to call Jira APIs using user permissions versus app permissions, and how this choice directly impacts data visibility, correctness, and security.Custom fields as first-class integration primitives
How to create Jira custom fields, manage their values at scale, and reliably use them in advanced JQL queries, dashboards, and reports—despite asynchronous updates and API limits.Understanding Team-managed vs Company-managed projects
Deep understanding of architectural and functional differences between project types, including how Sprint field behavior, permissions, and API access differ—and how those differences affect integrations and automation.Advanced sprint mechanics in Jira
A thorough understanding of how sprint creation, lifecycle, permissions, visibility, and deletion actually work in Jira Cloud, including undocumented behaviors and hard platform limitations.Data modeling and caching in Forge
Designing efficient data structures and caching strategies using Forge KVS to minimize API calls, improve performance, and support large-scale Jira instances.Working within Forge platform constraints
Learning how to deal with execution limits, throttling, missing API data, and pricing constraints through conscious architectural decisions and functional trade-offs.Designing scalable admin interfaces
How to design clear, usable, and scalable administrative UIs that remain effective even when managing very large numbers of sprints, plans, and configurations.
Overall, this project reinforced a key principle:
on Forge, architecture is shaped more by platform constraints than by feature ideas.
Accepting those constraints early—and designing around them deliberately—leads to more reliable, predictable, and maintainable solutions.
What's next for Sprint Organizer for Jira
Future development will focus on expanding Sprint Organizer beyond individual sprint planning toward large-scale, coordinated sprint group management.
Planned directions include:
Advanced planning and management of sprint groups at scale
Extending planning capabilities from single sprints to larger sprint groups, with richer context that includes:- users and team composition,
- components and versions,
- sprint and cross-sprint goals,
- new capability models based on skills.
Skills as a first-class concept
Introducing skills as structured entities that can be associated with:- users,
- issues,
- components,
- versions.
This will enable more realistic capacity planning, better alignment of work with team competencies, and improved visibility into skill distribution across sprint timelines.
Richer contextual planning
Enhancing sprint planning with additional dimensions such as ownership, responsibility, and goal alignment, allowing teams to reason not only about when work happens, but also who it depends on and what capabilities are required.Continuous alignment with Forge platform evolution
Actively monitoring the Forge platform for new capabilities, APIs, and architectural improvements that could significantly enhance performance, usability, or automation possibilities for our customers.
Where new Forge features provide clear value, we plan to adopt them to:
- simplify workflows,
- reduce technical limitations,
- improve responsiveness and scalability.
The long-term vision remains unchanged:
to make sprint planning in Jira queryable, auditable, scalable, and context-aware, while evolving alongside the Atlassian platform and the needs of growing organizations.
Try this out!
Built With
- atlaskit
- echarts
- forge
- javascript
- jira-rest-api
- react

Log in or sign up for Devpost to join the conversation.