-
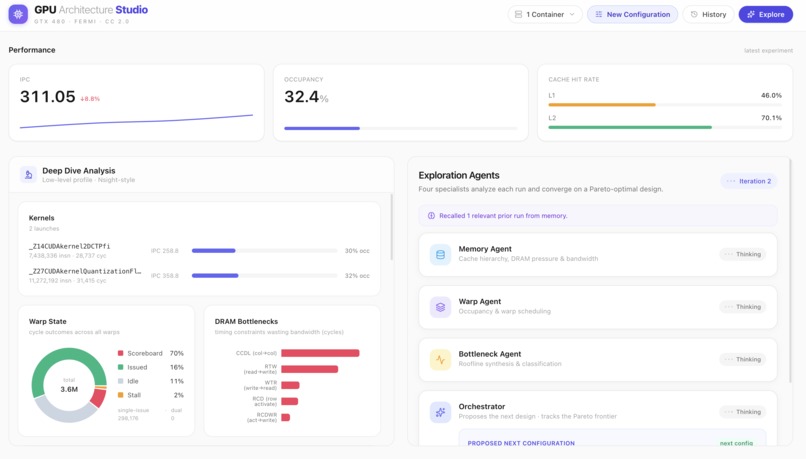
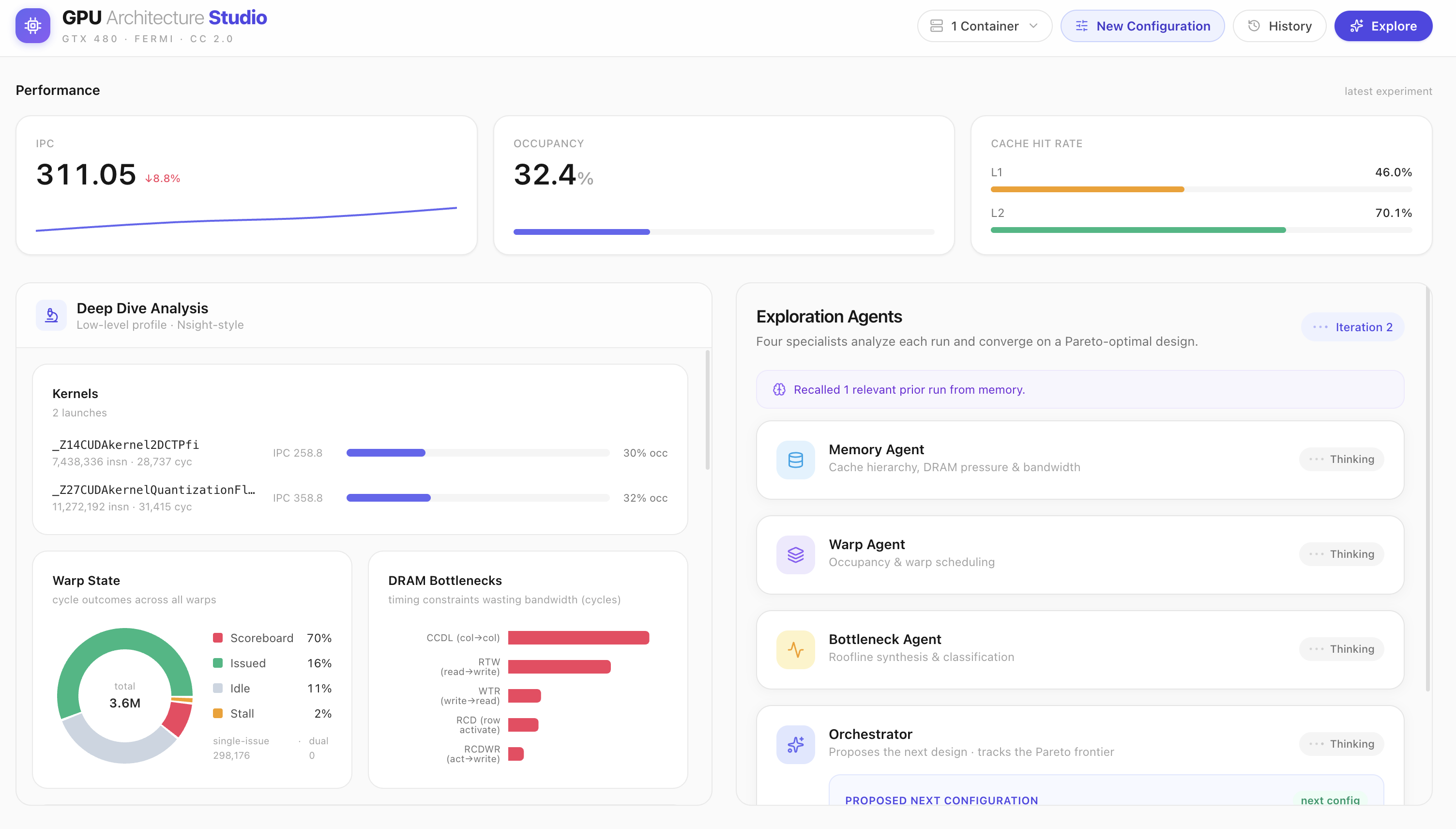
Live dashboard — IPC, occupancy, L1/L2 hit rates, Nsight-style deep dive, and four agents analyzing the run to propose the next config.
-
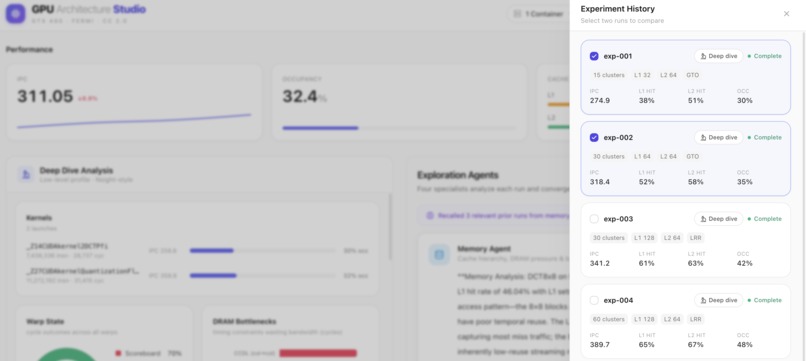
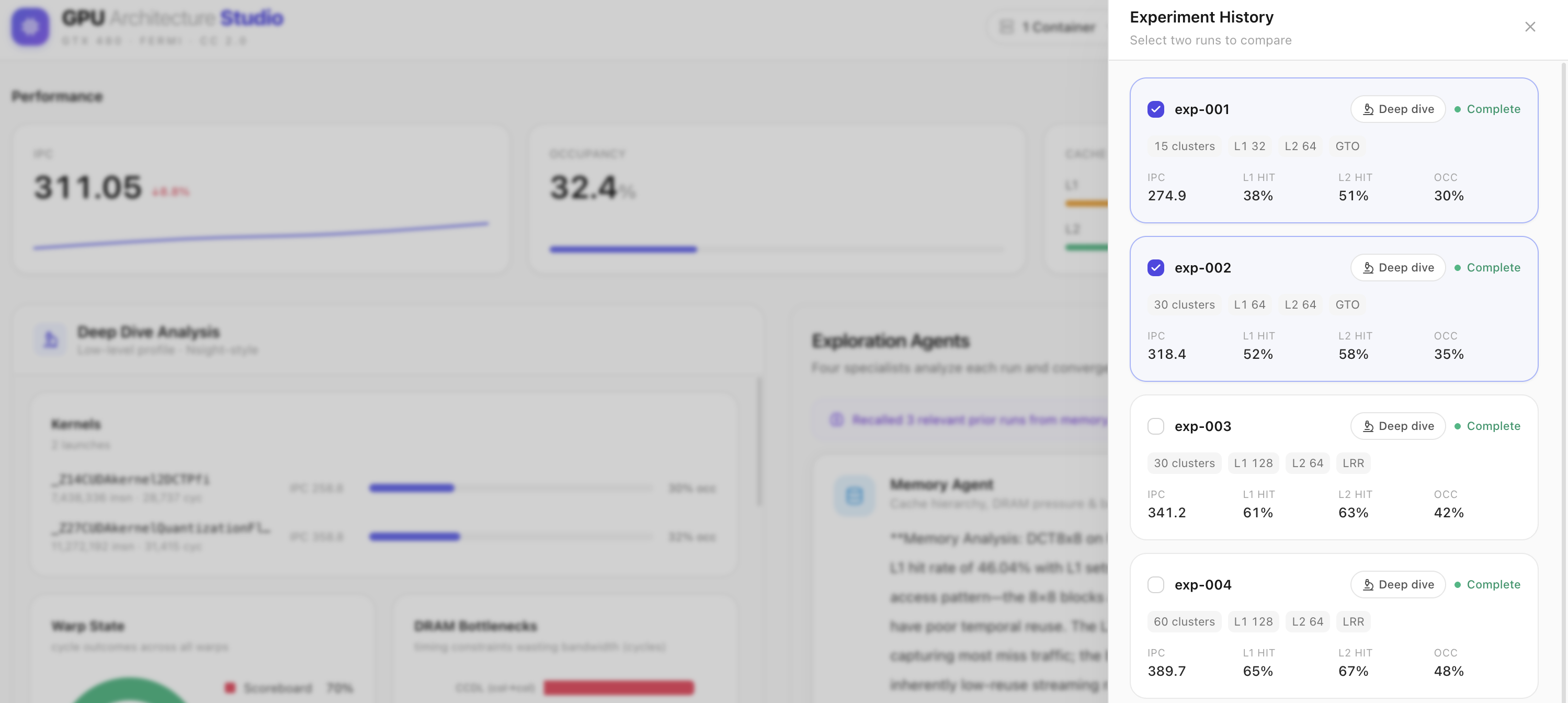
Experiment history: every run stored with full config and metrics. Select any two to compare, or pick a config to test next.
-
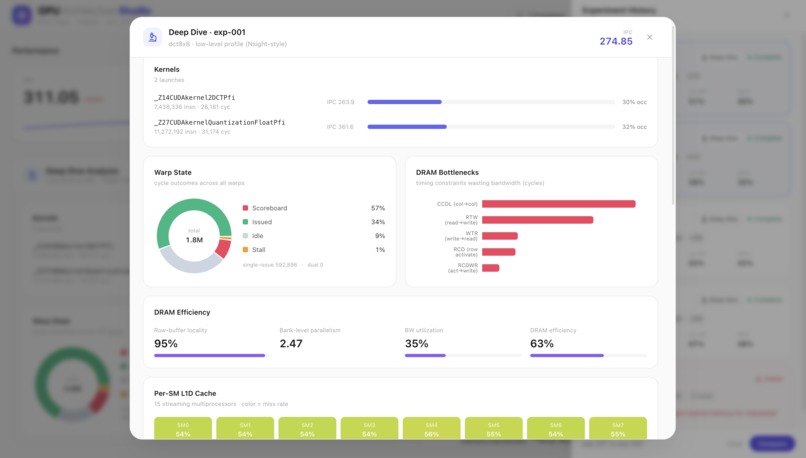
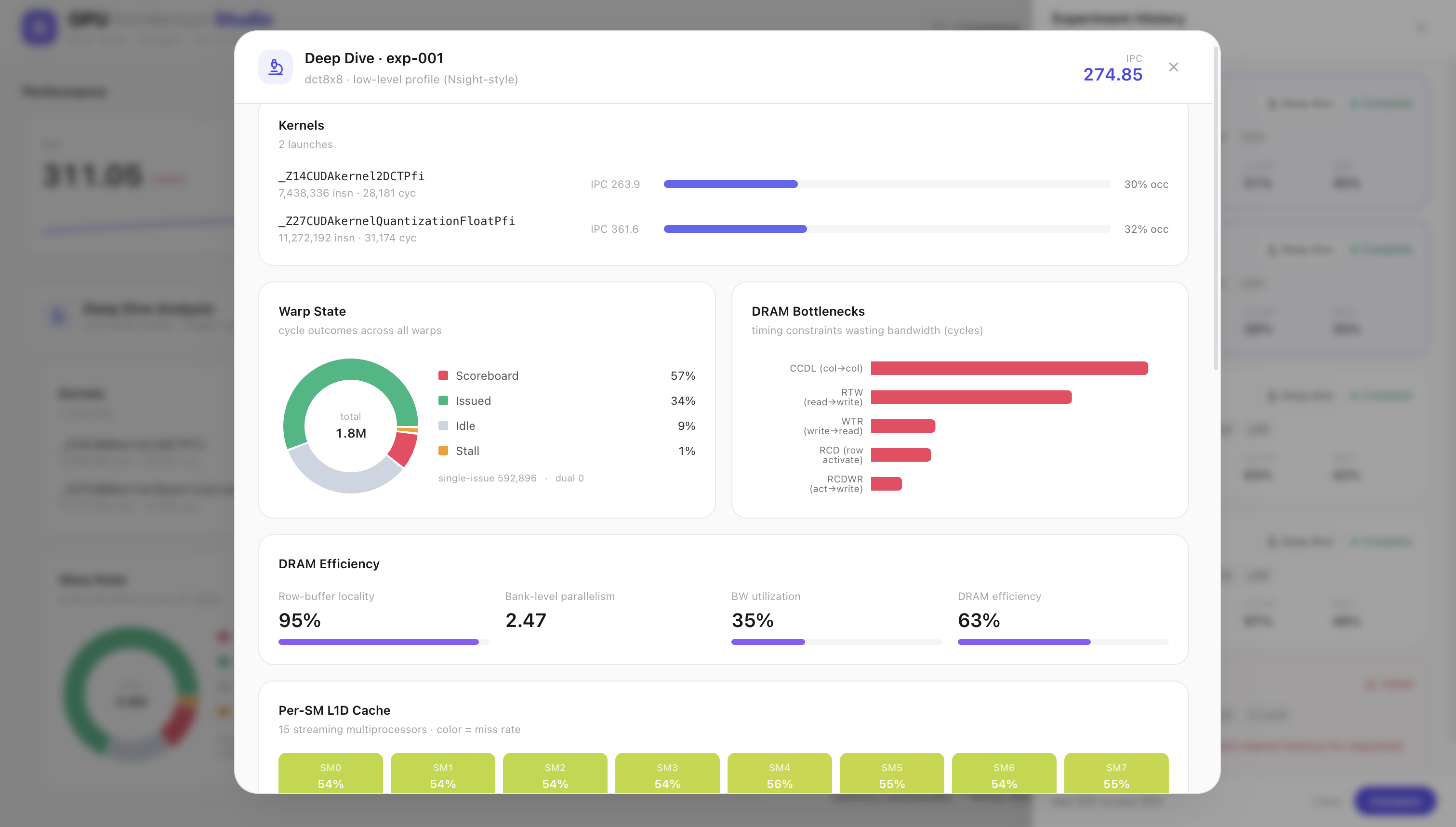
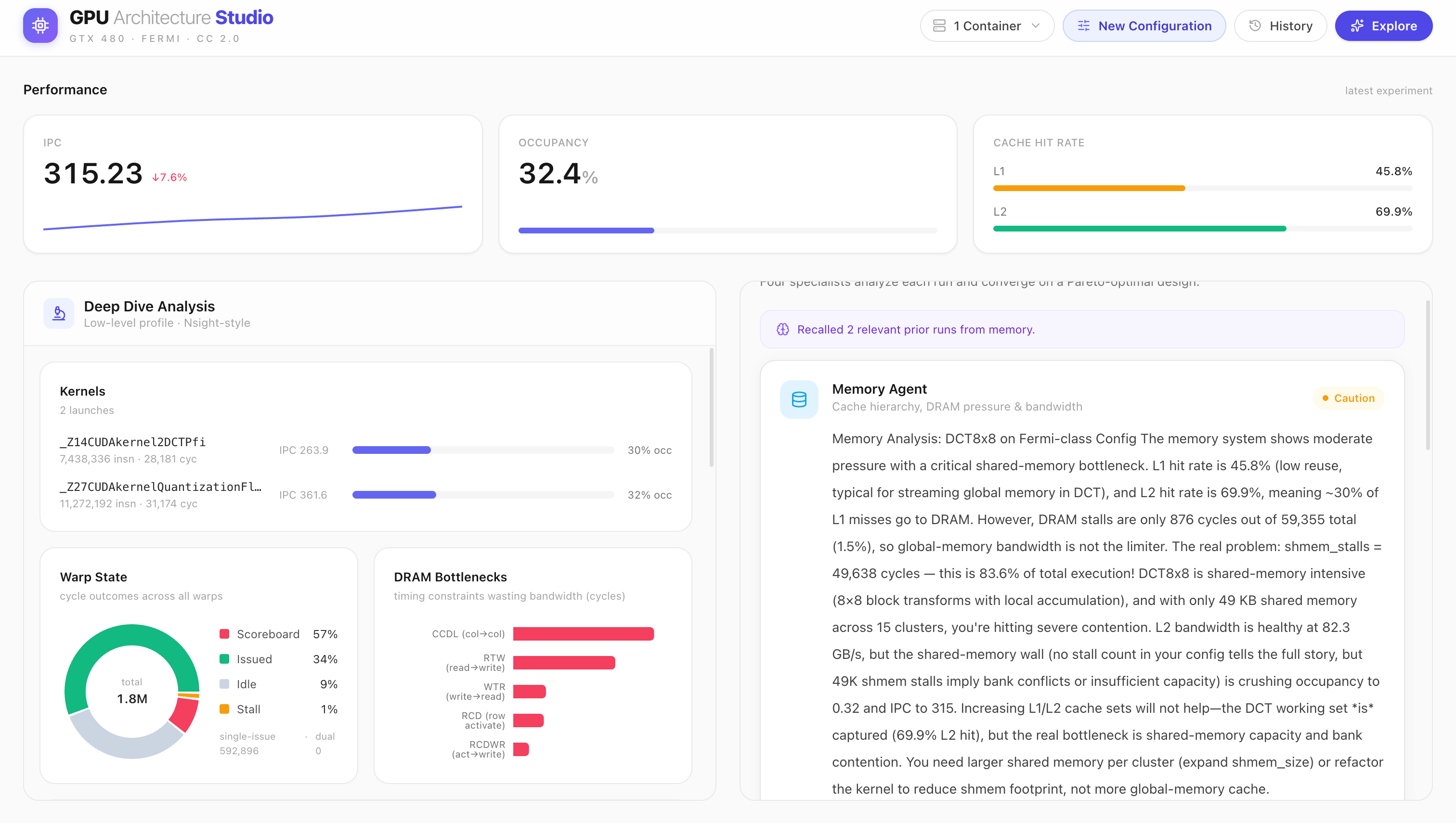
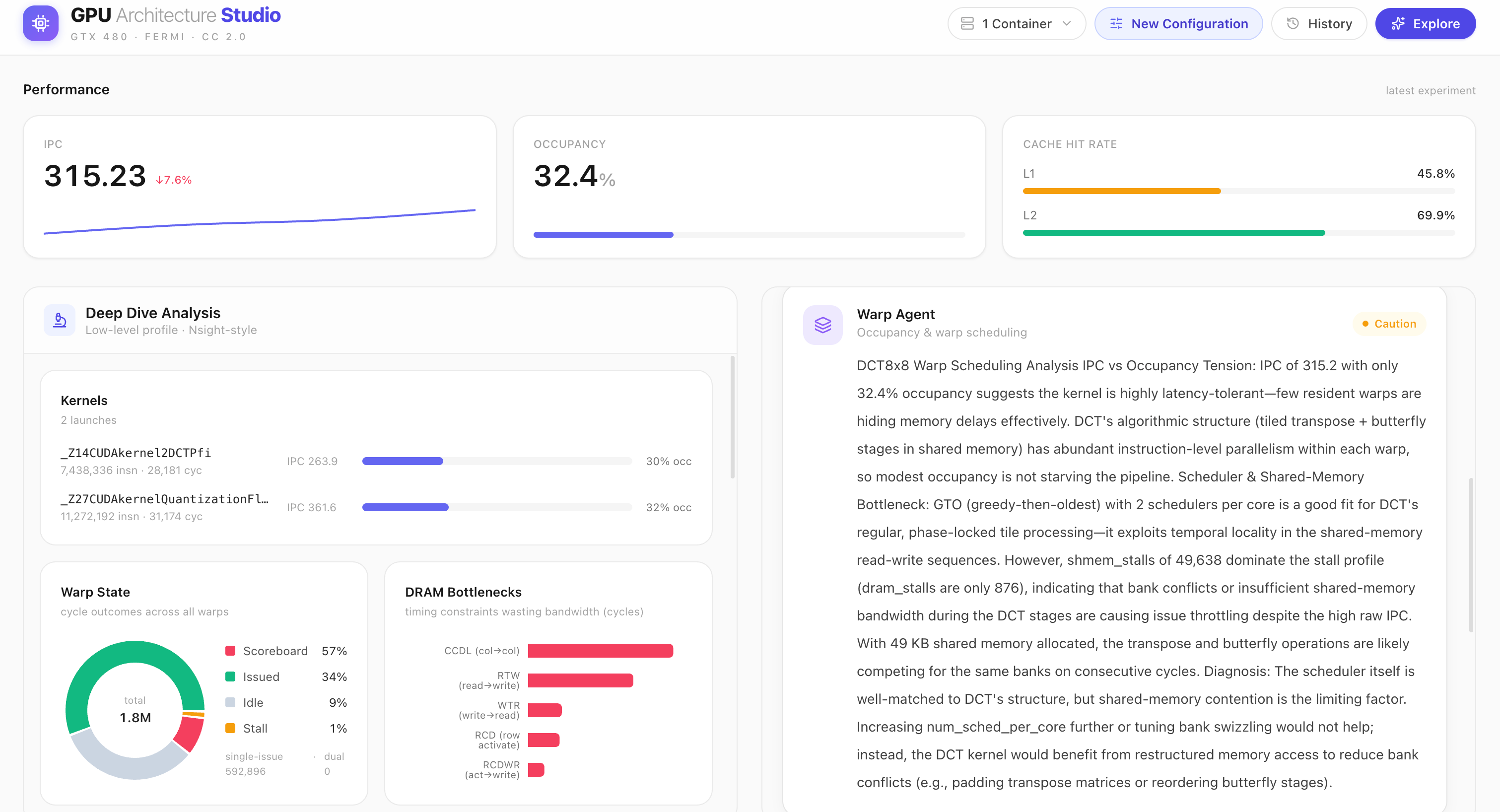
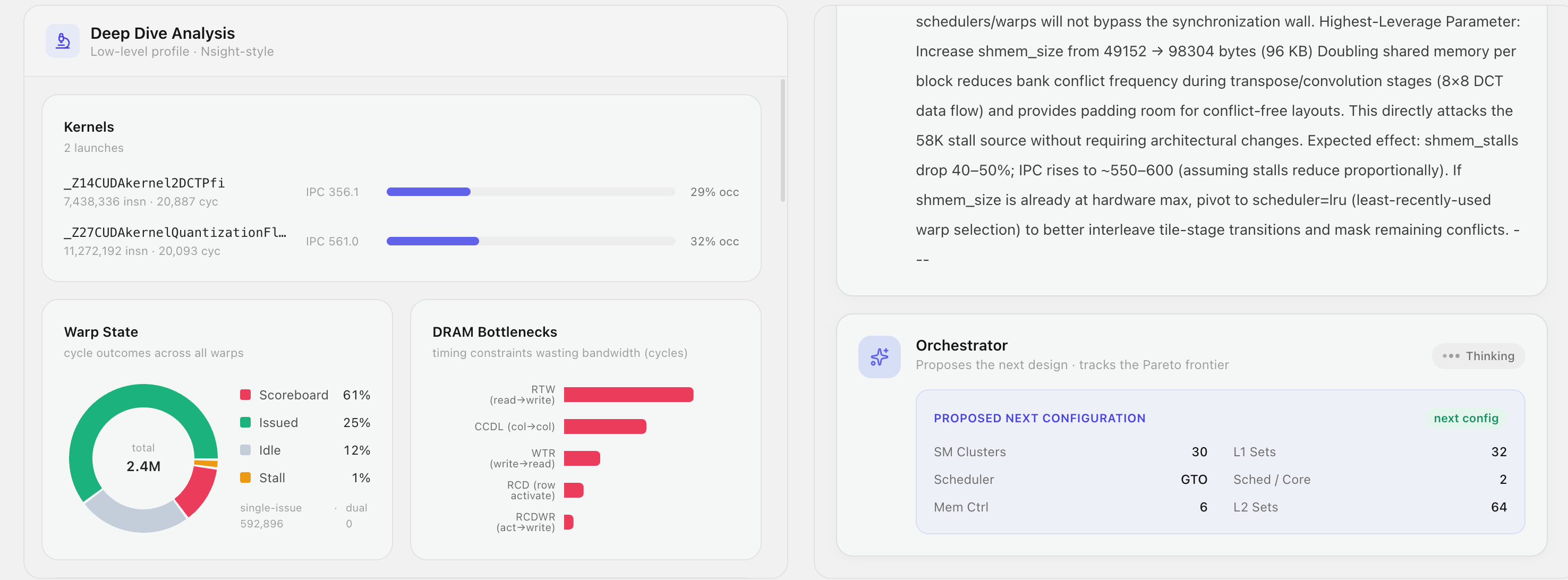
Deep Dive for exp-001: per-kernel IPC, warp state 57% scoreboard-stalled, DRAM bottlenecks, & efficiency metrics from real counters.
-
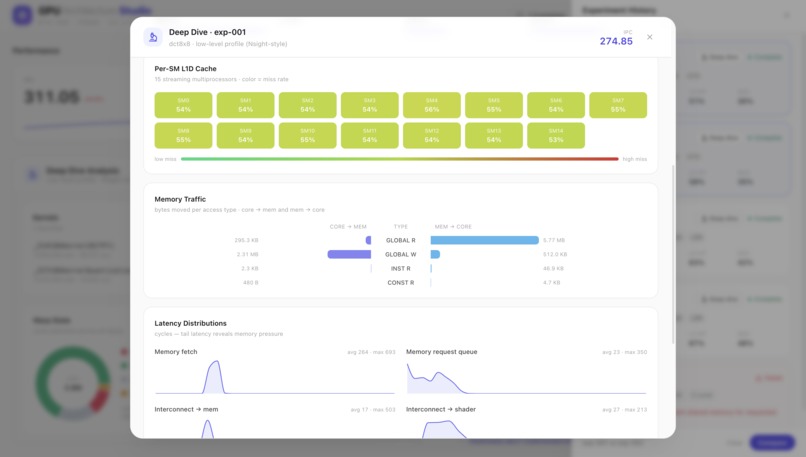
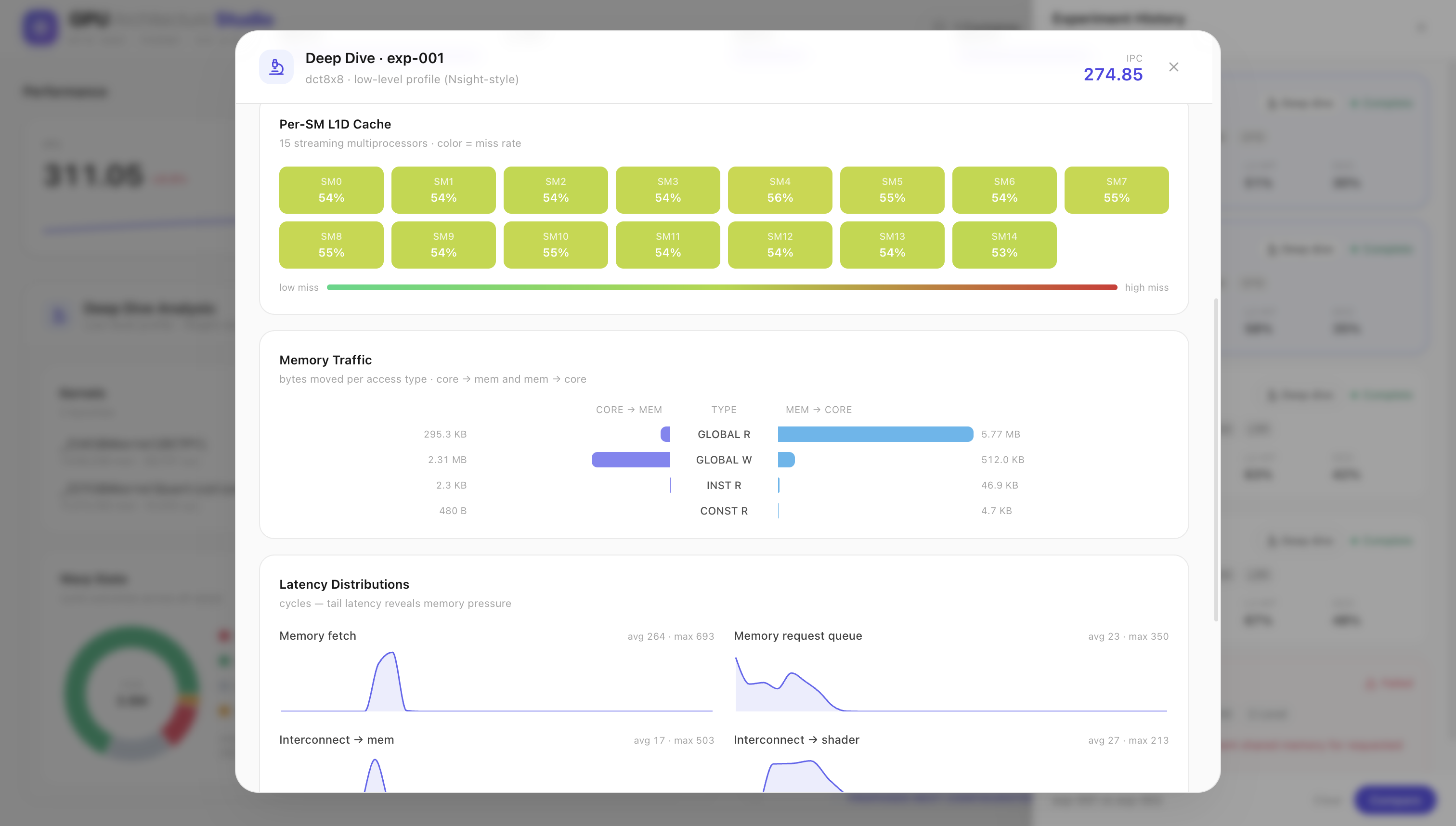
Same run, deeper: per-SM L1D miss rates across all 15 SMs, plus core↔memory traffic broken down by access type.
-
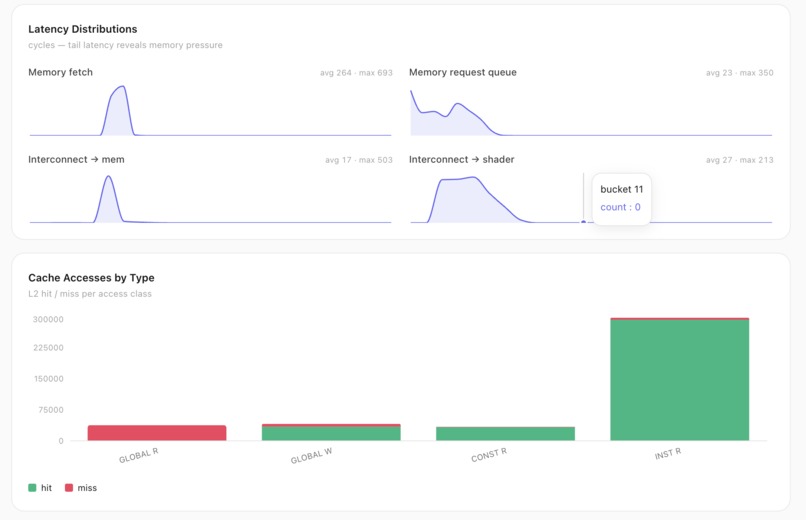
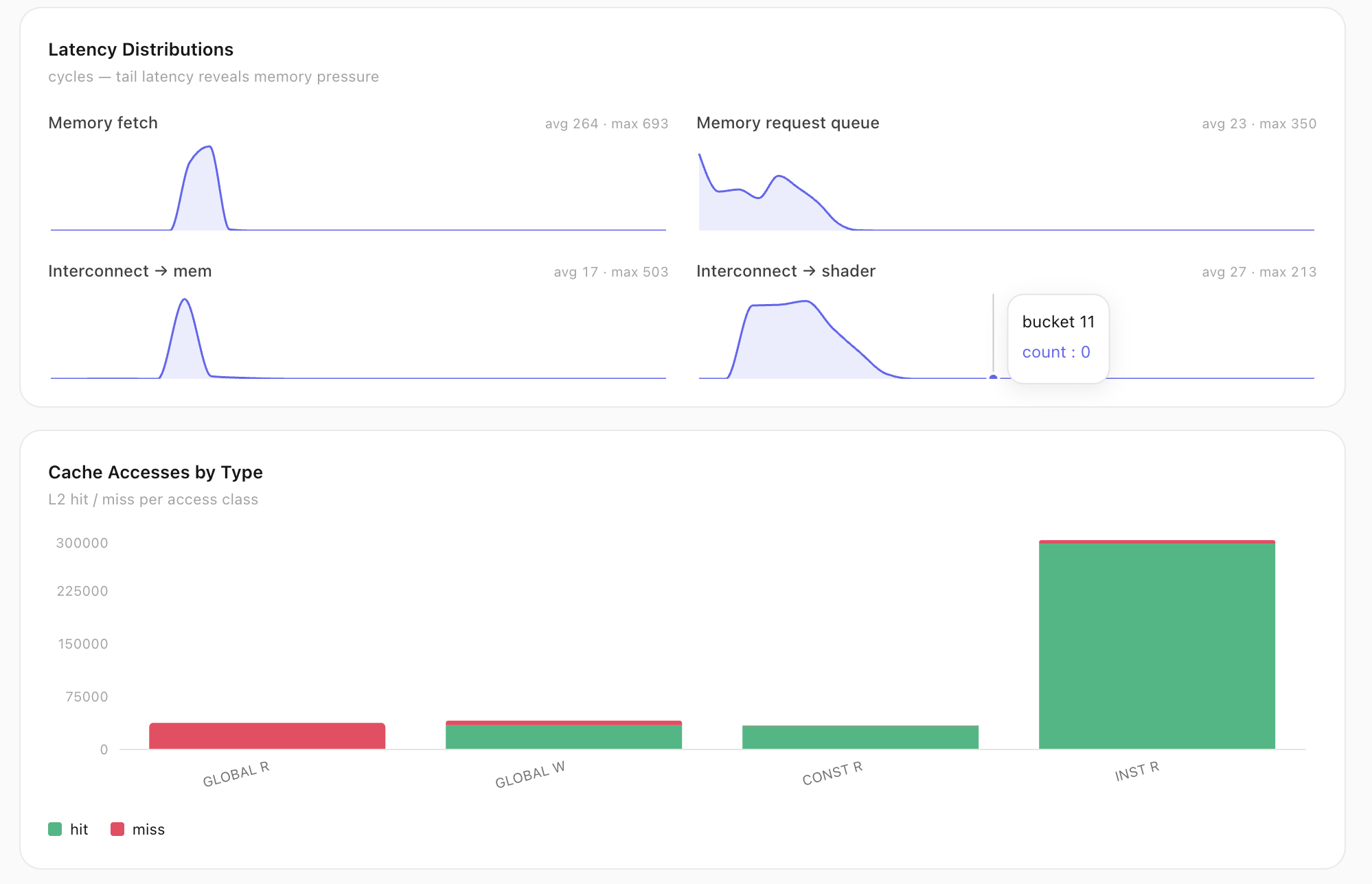
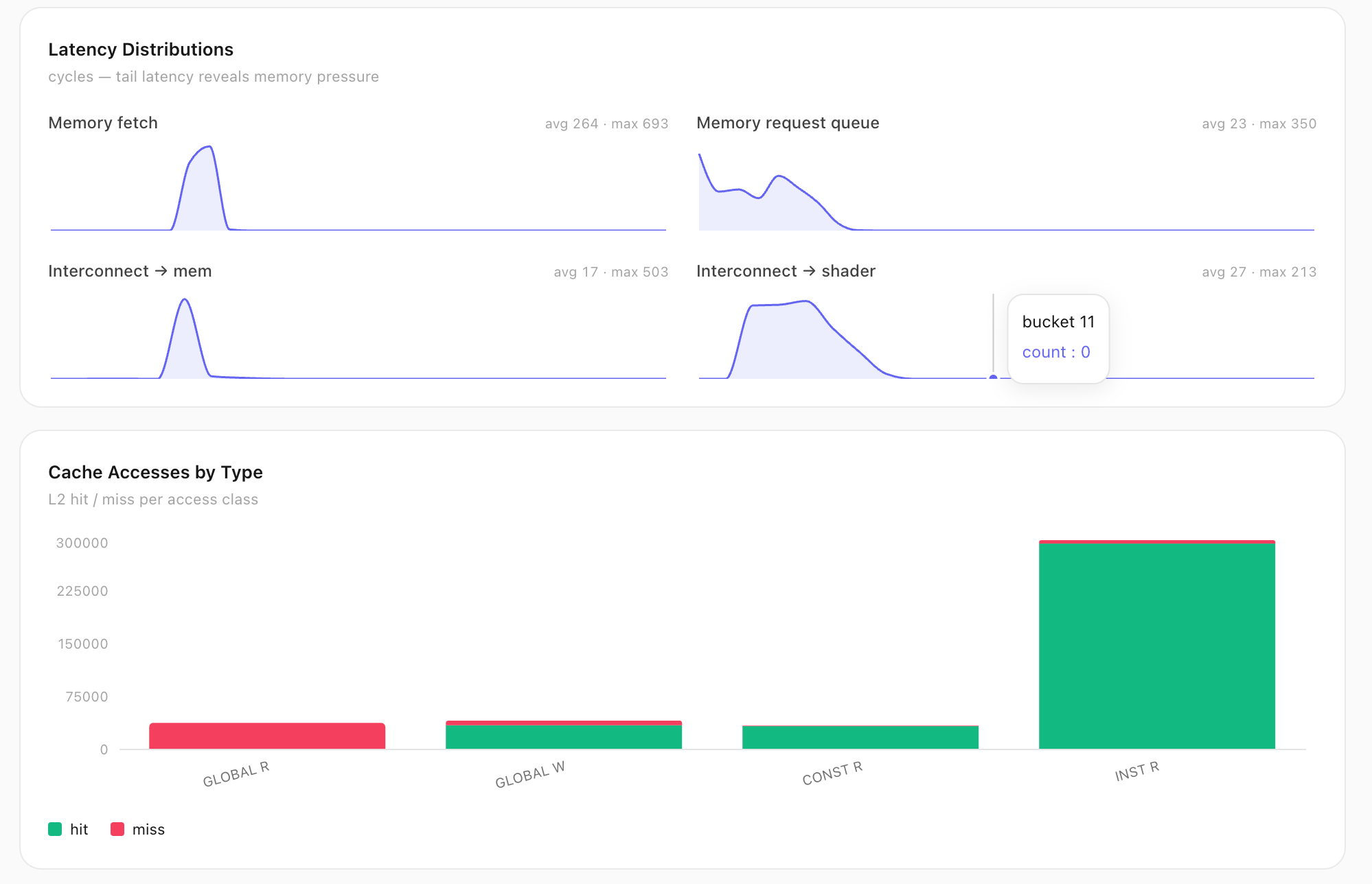
Latency distributions expose tail memory pressure (fetch max 693 cyc), and L2 hit/miss is split per access class.
-
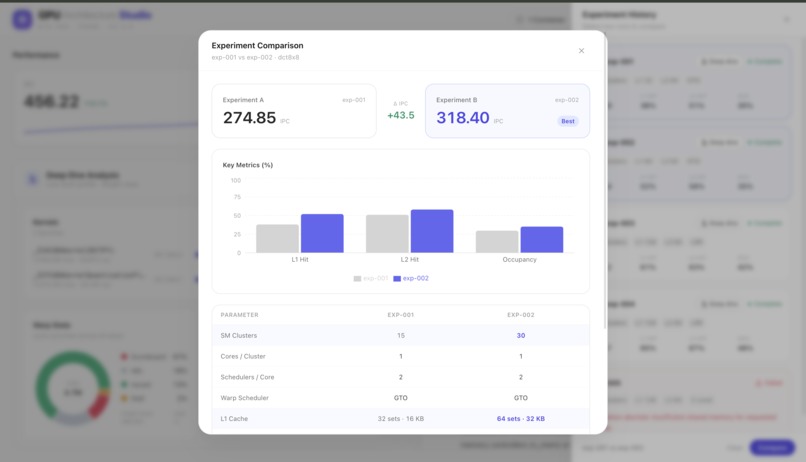
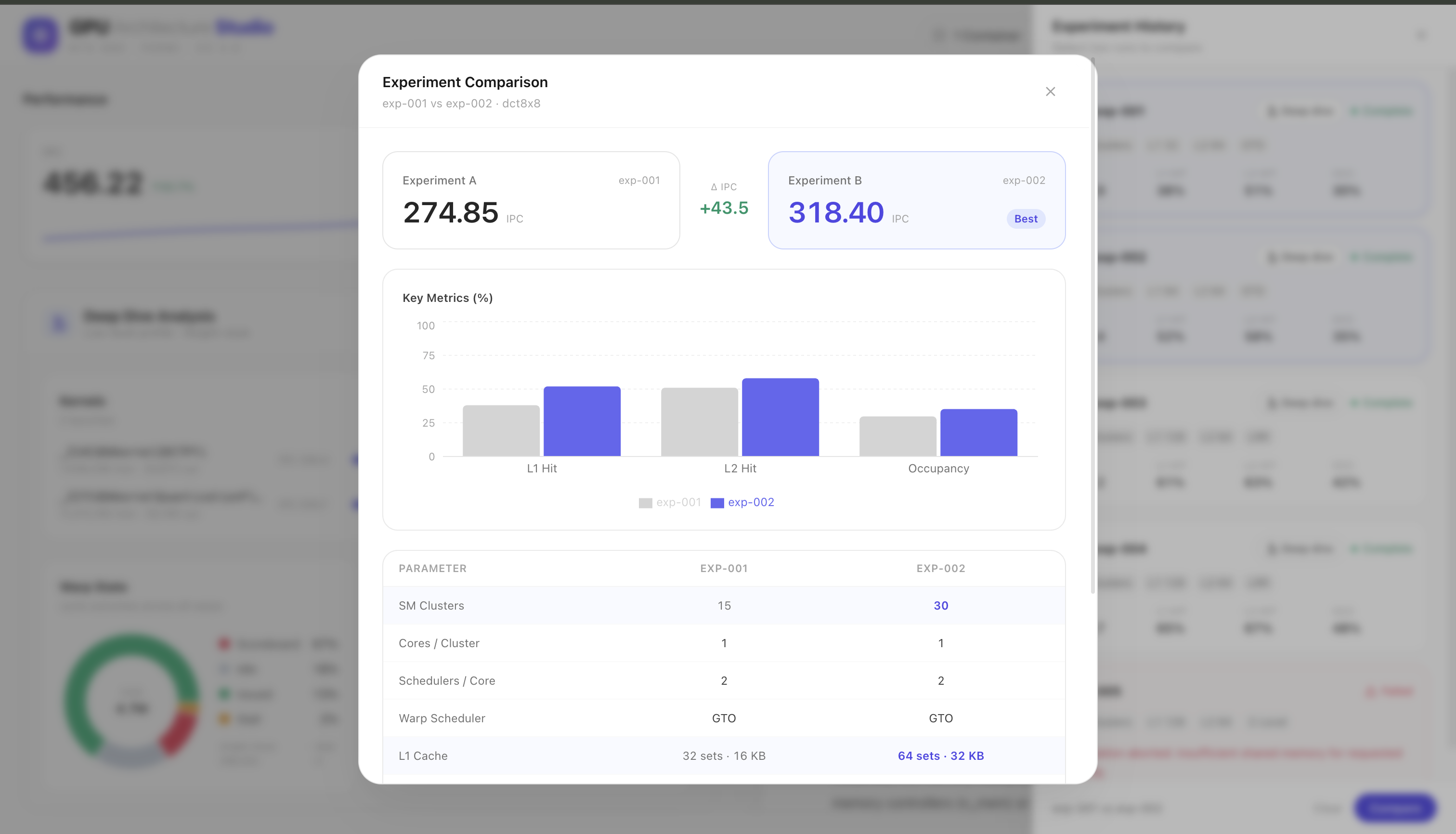
Side-by-side compare: exp-002's 30 clusters and larger L1 lift IPC +43.5 over exp-001 — the agent's reasoning made visible.
-
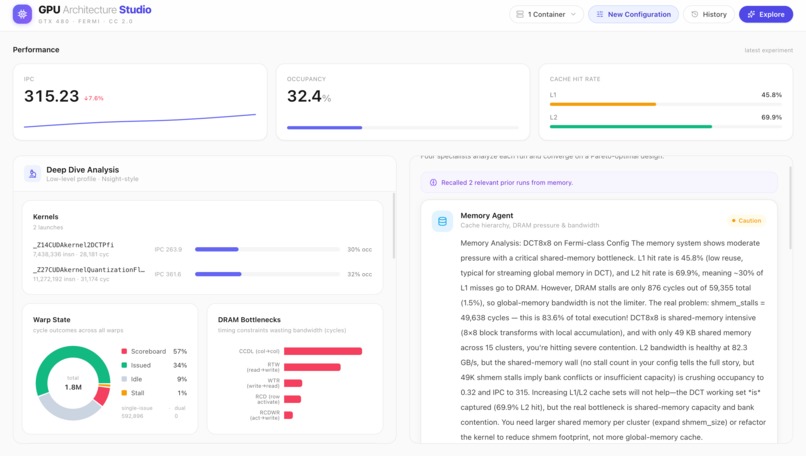
Memory Agent reads real counters and pinpoints the true bottleneck: shmem stalls at 83.6% of execution, not cache — flagged "Caution.
-
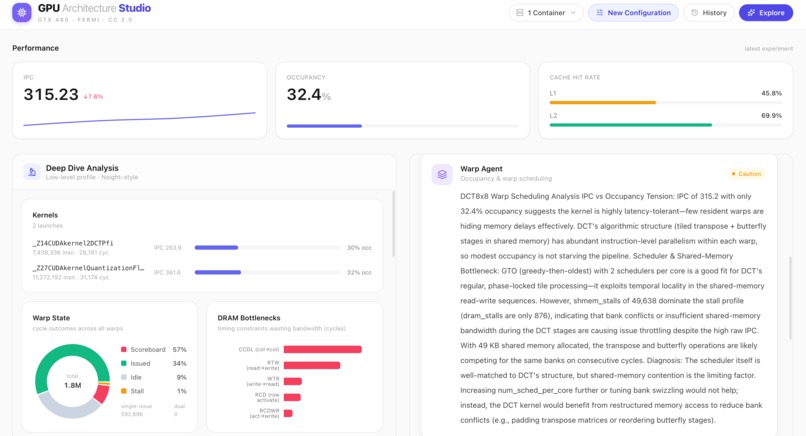
Warp Agent diagnoses the IPC-vs-occupancy tension: GTO fits DCT, but bank conflicts in shared memory are the real limiter.
-
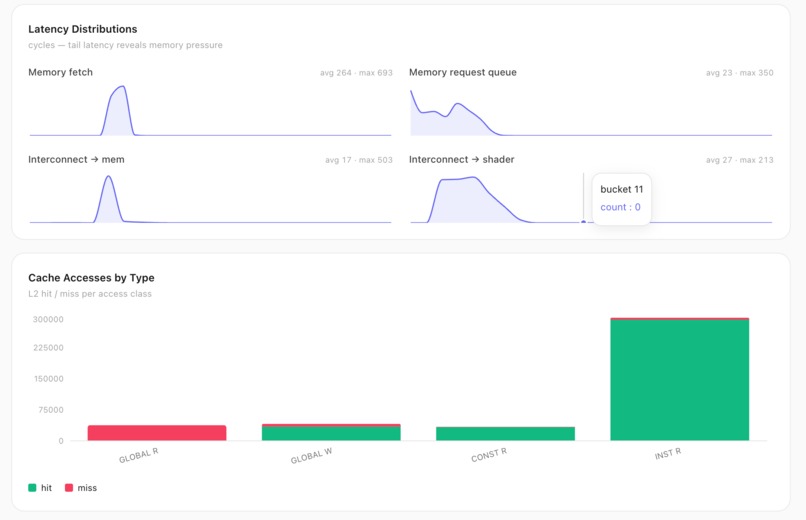
Latency distributions expose tail memory pressure (fetch max 693 cyc); L2 hit/miss split per access class.
-
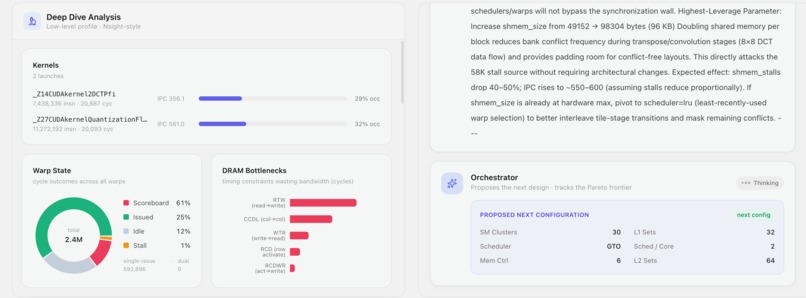
The Orchestrator reasons over the diagnosis and emits a concrete next config — e.g. double shmem_size to attack the 58K stall source.
-
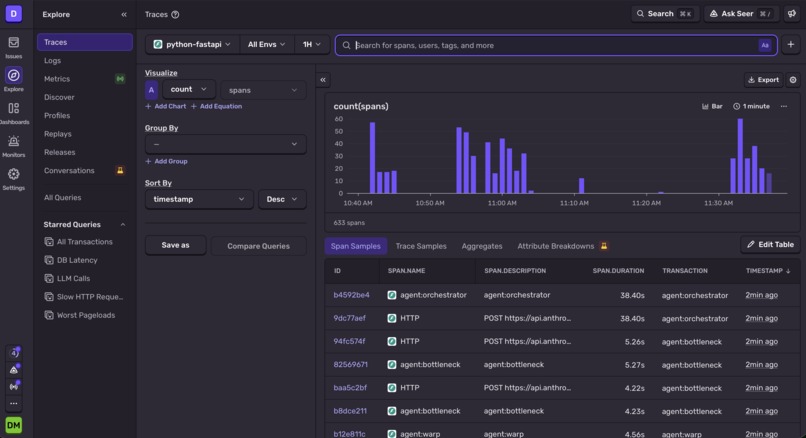
Sentry traces every sim and agent call capturing failures with the offending config so silent crashes become reproducible debuggable issues.
-
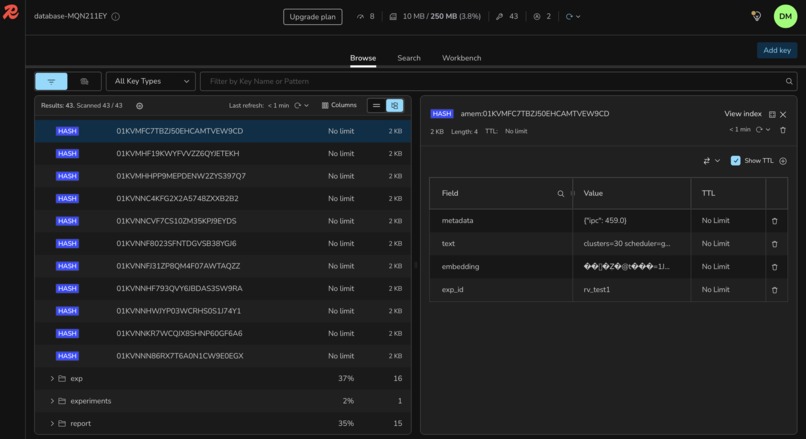
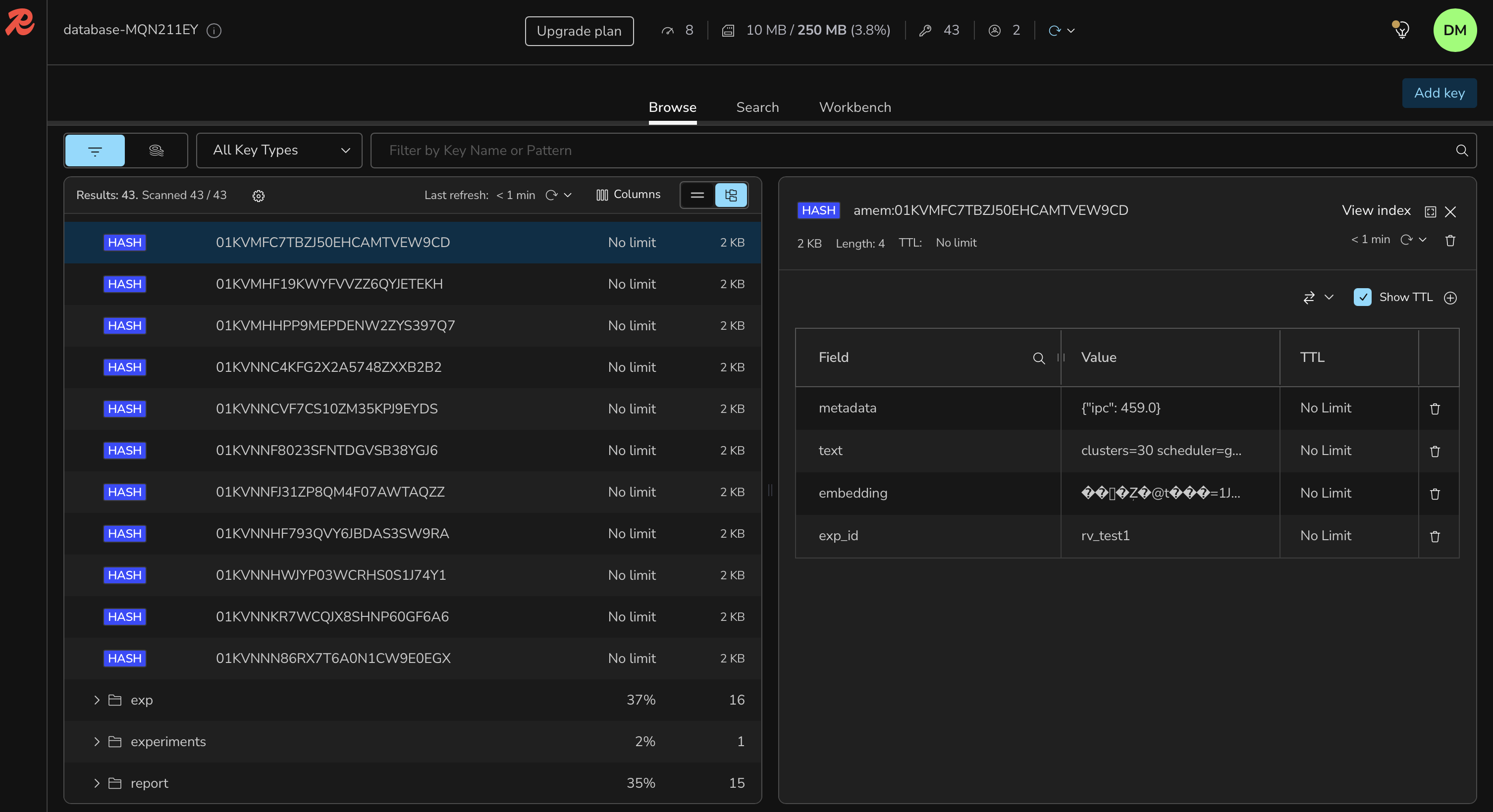
RedisVL stores each experiment as a vector; the Orchestrator semantically recalls relevant past runs before every decisionmemory, not cache.
Inspiration
Picking the right GPU microarchitecture for a workload is a brutal search problem. With just the knobs we expose SM clusters, cores/cluster, memory channels, scheduler, shared-memory size, L1/L2 cache - the space is already $$4 \times 3 \times 4 \times 3 \times 3 \times 3 \times 4 \times 3 = 15{,}552 \text{ configurations,}$$ and each one means hand-editing a simulator config, queueing a cycle-accurate run, and squinting at a 3,000-line counter dump. Today that loop is done by a handful of specialists over weeks. We wanted to put that expert loop on autopilot and let anyone drive it by just describing a goal.
What it does
GPU Architecture Studio is an autonomous design-space explorer. You give it a goal ("maximize IPC for the JPEG workload"); a team of AI agents then proposes a config, runs a real GPGPU-Sim simulation, diagnoses the bottleneck, proposes a better config, and repeats converging on a Pareto-optimal design and explaining every step. The agents decide what to run next it's not a UI that explains what you ran. You can drive it from a web studio or chat with it through ASI:One.
How we built it
- Simulation: a FastAPI backend drives GPGPU-Sim (GTX-480/Fermi) in Docker, generates configs, and parses the real counters.
- Agents: four Claude agents: Memory, Warp, and Bottleneck specialists (Haiku) plus an Orchestrator (Sonnet, adaptive thinking) that reasons over the full history.
- Memory: RedisVL as agent memory, each experiment is embedded and the Orchestrator semantically recalls relevant past runs before each decision.
- Reliability: Sentry traces every sim and agent call and captures failures with the offending config.
- Reach: Fetch.ai uAgents with the Agent Chat Protocol expose it on Agentverse / ASI:One - including a multi-agent bureau where the Orchestrator delegates to the specialist uAgents over Fetch messaging.
Challenges we ran into
- The simulator fought back.The simulator fought back. Scaling clusters segfaulted GPGPU-Sim until we realized the interconnect must be regenerated to match: k = n_clusters + n_mem × 2. We now emit both files together.
- A silent loop-killer. The Orchestrator returned empty proposals, adaptive thinking was consuming the entire token budget. Diagnosing it (not guessing) and raising max_tokens fixed it.
- Flaky infrastructure. A Redis drop mid-run once killed a successful experiment; we made persistence best-effort so a datastore blip can never lose a result.
- Dependency isolation for uAgents (older pinned deps) solved by running Fetch agents in a separate env that talks to the backend over HTTP.
Accomplishments that we're proud of
A loop that genuinely improves the design real simulations climbing IPC 315 → 459 → 490 with the Orchestrator justifying each move; agent analysis sharp enough to pass for a real architect; Redis used beyond caching as vector memory; and the whole system reachable from a chat, with reliability engineering that turns crashes into graceful, monitored failures.
What we learned
Always test against real simulator output, never assumed formats. Tiered models (cheap specialists, smart orchestrator) keep cost ~$0.25/run. Vector recall turns the agent's growing history from a context-window problem into an advantage. And clean seams (injectable stores, HTTP-decoupled agents) let sponsors layer in without breaking the core.
Sponsor Tracks
We didn't reach for sponsor tech to check boxes each one solved a problem the autonomous loop genuinely had. The clean seams in our architecture (injectable stores, HTTP-decoupled agents) are exactly what let them slot in without bending the core.
Anthropic (Claude) the reasoning itself. Claude is the loop, not a feature on top of it. The diagnosis "L1 miss traffic is low-reuse streaming; highest leverage is more clusters" is a Claude judgment over a 3,000-line counter dump, and the next config is a Claude decision. We leaned into the model lineup on purpose: cheap Haiku specialists (Memory, Warp, Bottleneck) do the per-run analysis, and a Sonnet Orchestrator with extended thinking reasons over the full experiment history to pick the next move. That tiering is what keeps a full exploration at ~$0.25/run instead of being cost-prohibitive. We also built the whole system with Claude Code.
Redis Redis beyond caching, as the agent's memory. This was the integration we're most genuinely proud of, because it fixed a real failure mode. As the run grows, the Orchestrator can't fit every past experiment in its context window. Instead of truncating history, we embed each experiment and store it in RedisVL; before every decision the Orchestrator semantically recalls the most relevant prior runs (the "recalled N relevant prior runs" moment in the UI is this firing). That turns a growing history from a context-window liability into a compounding advantage and it's Redis as a vector database, not a key-value cache. Redis also backs the experiment store, made best-effort so a datastore blip can never lose a successful result.
Sentry reliability for an unattended autonomous loop. A loop that runs cycle-accurate simulations and LLM calls without a human watching fails in ugly, silent ways and we hit several: GPGPU-Sim segfaulting on cluster scaling, the Orchestrator returning empty proposals when adaptive thinking ate the token budget. Sentry traces every simulation and every agent call and captures failures with the offending config attached, so each crash becomes a reproducible, monitored issue instead of a dead loop we have to guess at. Diagnosing the empty-proposal bug from a captured trace (rather than guessing) is precisely why this earned its place.
Fetch.ai reach and real agent-to-agent collaboration. We wrapped the explorer as uAgents speaking the Agent Chat Protocol, so it's reachable on Agentverse / ASI:One you can drive a full design exploration just by chatting with it. Beyond a single entry point, we built a multi-agent bureau where the Orchestrator delegates to the specialist uAgents over Fetch messaging, which is genuine agent-to-agent collaboration rather than one process calling functions. Running the Fetch agents in their own environment that talks to the backend over HTTP also solved a real dependency-isolation problem.
https://agentverse.ai/agents/details/agent1qv0wrqka6vhj6enxaurju53ky30hp4qz9hfvp0spuz5s7490lpjexzcv45n/profile https://asi1.ai/chat/3224a73e-3390-4a71-aca0-bd9bfc213ece
What's next for Spr0utS0urc4
A more fluid and pluggable system to connect more SIMS for end-to-end hardware analysis not just GPU, multi-container parallel exploration, a richer UI, deeper multi-agent collaboration.



Log in or sign up for Devpost to join the conversation.