-
-
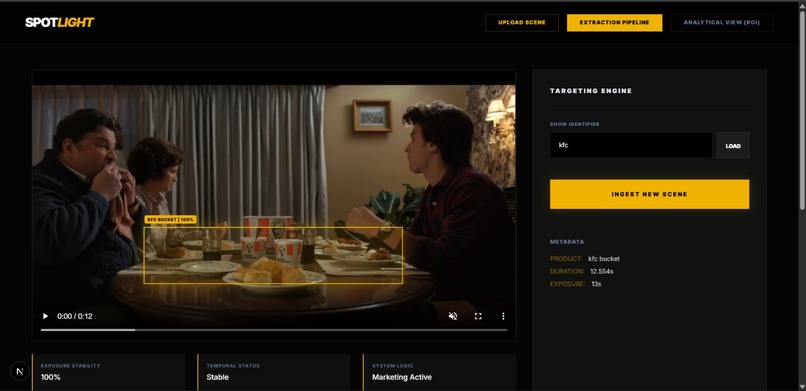
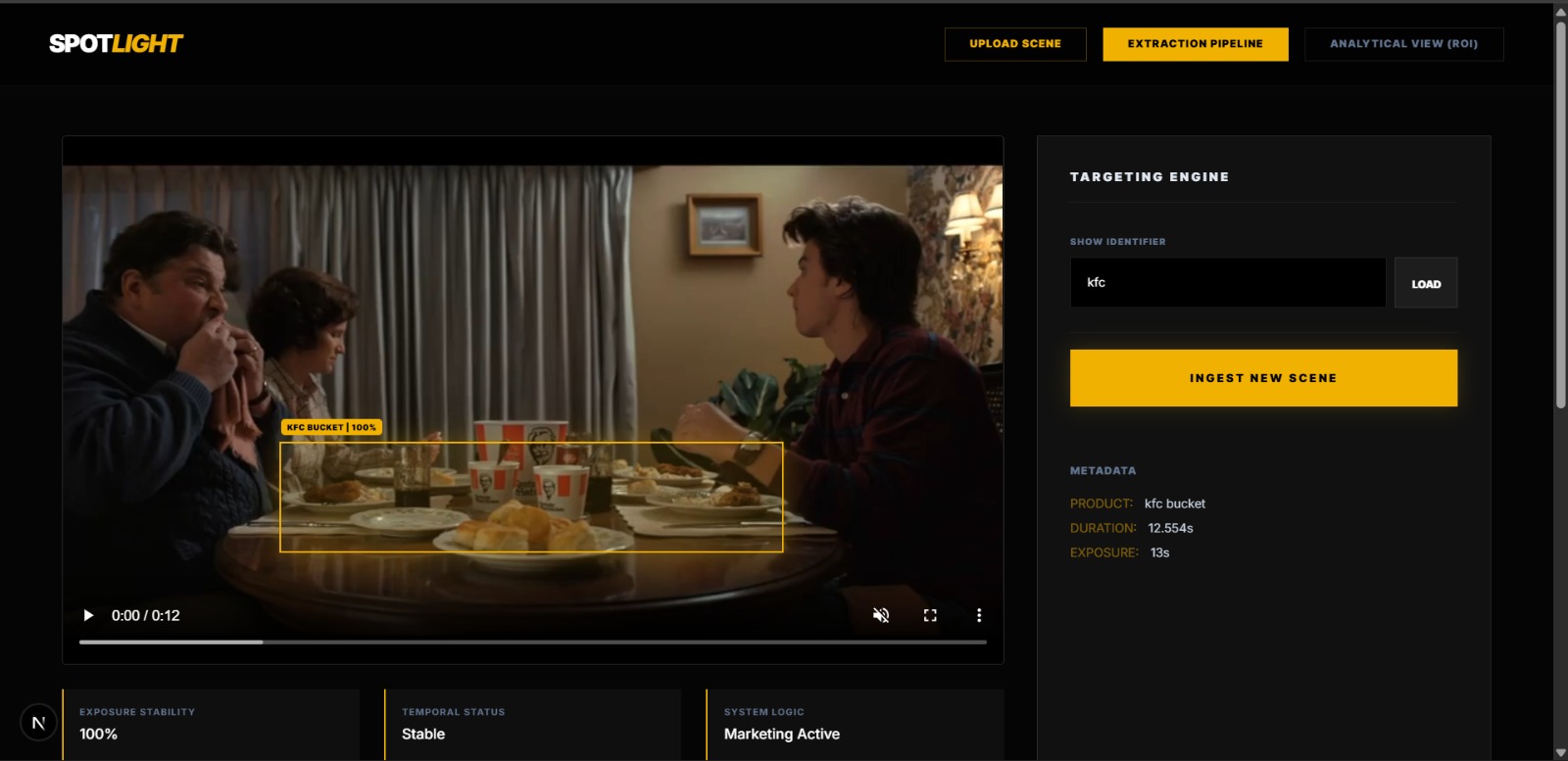
Scene Analysis
-
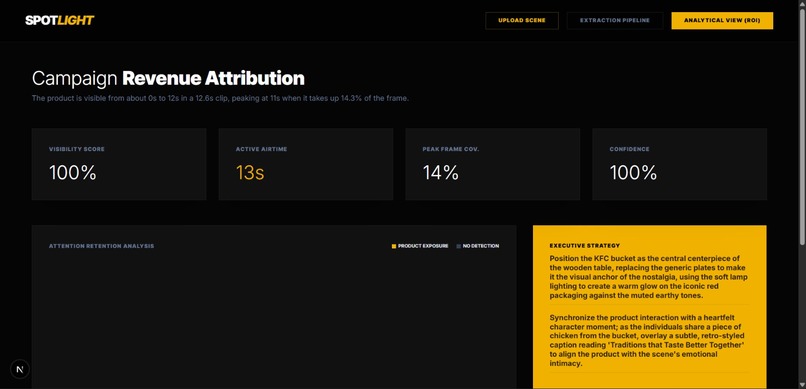
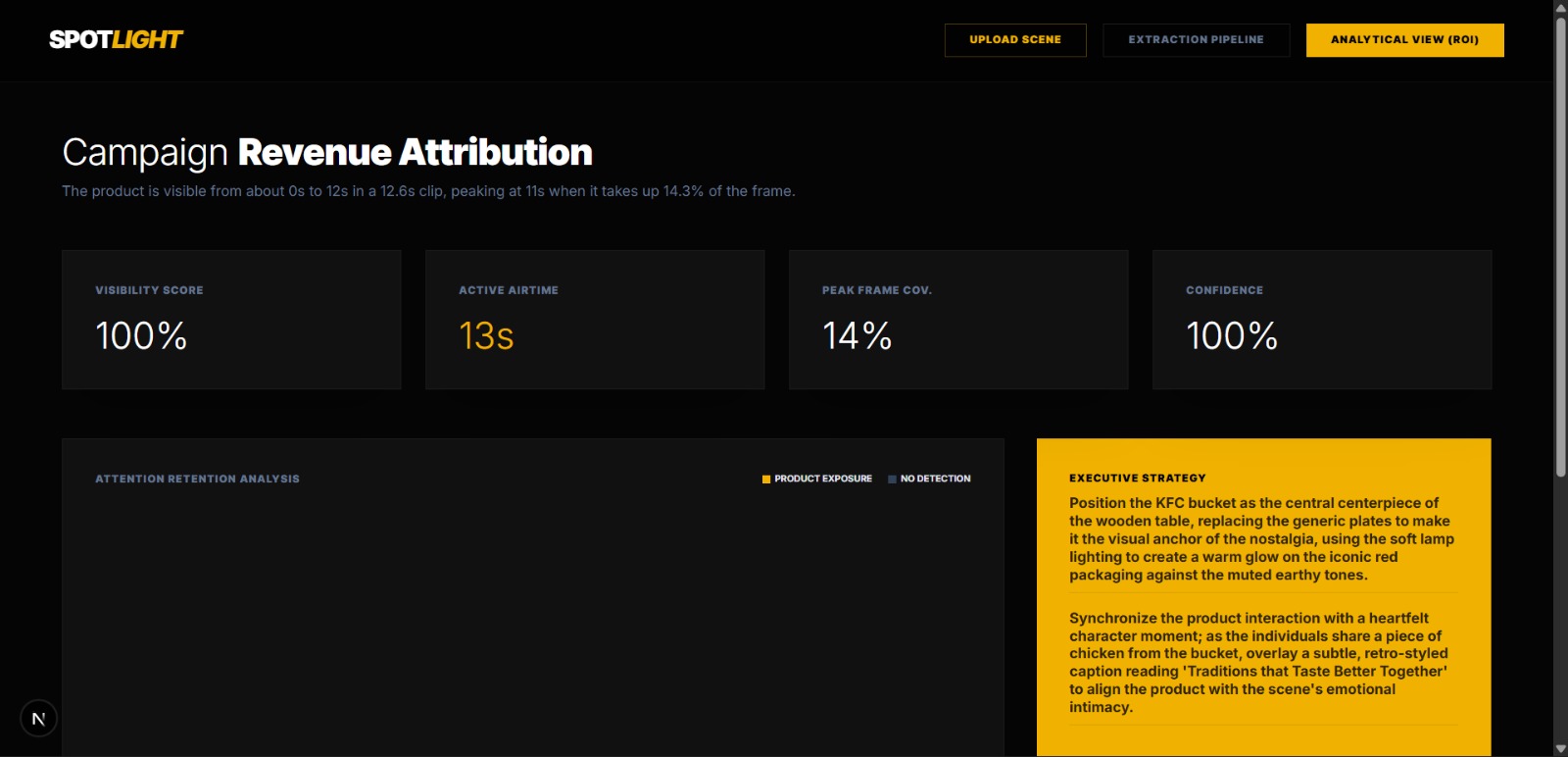
Analytics Dashboard
-

Brand Placement

Inspiration
Product placement in film and television is a multi-billion dollar industry built almost entirely on gut feeling. A brand pays hundreds of thousands of dollars for a KFC bucket to appear on a Stranger Things dinner table, then has no reliable way to verify whether that placement actually reached viewers. We wanted to change that. Spotlight was inspired by the gap between how much money flows into product placement and how little data comes back out.
What it does
Building Spotlight taught us that the hardest problem in video AI is not detection — it is tracking. Getting a vision model to identify a product in a single frame is straightforward. Getting that identification to hold across scene cuts, lighting changes, partial occlusions, and camera motion is an entirely different challenge. We learned to think about video not as a continuous stream but as a series of discrete scenes separated by hard cuts, each requiring its own detection pass. We also learned that prompt engineering for vision models is as important as the model itself — the difference between a vague prompt and a richly described product description was the difference between the model finding the KFC bucket and missing it entirely.
How we built it
The pipeline has three stages. First, the video is uploaded and a single keyframe is extracted, where Groq's Llama 4 Scout vision model analyzes the frame and returns a bounding box for the target product. Second, an upfront pass detects all scene cuts using HSV histogram correlation, and we pre-compute exactly which frames need a fresh Groq vision call versus which frames can be handled by propagating the previous mask forward using dense Farneback optical flow. On Groq-called frames, we ask the model for a polygon describing the product's exact silhouette and refine it using OpenCV GrabCut to tighten edges at the pixel level. Third, the mask data is aggregated into per-frame visibility metrics and surfaced in a React dashboard built with Tailwind CSS. For the analytics layer, we built three marketing intelligence agents powered by Google's Gemma model. These agents analyze the mask data and frame metrics to generate actionable insights for brand managers — interpreting visibility scores, assessing placement quality, and producing a plain-English summary report of how effectively the product placement performed across the clip
Challenges we ran into
The biggest challenge was temporal consistency across scene cuts. Standard optical flow tracking fails completely on a hard scene cut — the tracked points teleport to random image content and the mask drifts to the wrong location. Our solution was to treat scene cuts not as a tracking problem but as a re-detection problem: detect cuts upfront, call Groq on those frames fresh, and use optical flow only within continuous segments where it is reliable. The second challenge was mask precision — early versions used a simple bounding box rectangle which looked obviously wrong on a cylindrical KFC bucket. Getting to a polygon-shaped mask required combining Groq's polygon output with GrabCut refinement and carefully clipping polygon points to prevent stray detections. The third challenge was speed. Each Groq vision call takes time and calling it on every frame of a 300-frame clip was not viable, so we pre-computed a schedule of exactly which frames needed API calls and handled everything in between with local optical flow computation, which is essentially free.
Accomplishments that we're proud of
The thing we are most proud of is solving temporal consistency across scene cuts — a problem that breaks most off-the-shelf tracking solutions. The Stranger Things clip is not a continuous shot; it jumps between multiple camera angles and scenes, and our mask follows the KFC bucket through every single one of those cuts without losing it. We are also proud of the mask precision we achieved. Rather than settling for a rectangle drawn around the product, we built a pipeline that returns a polygon tracing the actual silhouette of the object, refined at the pixel level using GrabCut. The result is a mask that follows the shape of the bucket, not just a box around it. Building all of this within a single hackathon was the accomplishment we are most proud of as a team.
What we learned
We learned that video AI is fundamentally a temporal problem, not a visual one. Any model can find an object in a photograph. The hard part is keeping that identification coherent across time, motion, and discontinuity. We also learned that the quality of a vision model's output is almost entirely determined by the quality of the prompt you give it — describing the KFC bucket as a large red and white striped cylindrical cardboard container with the KFC logo performed dramatically better than simply saying KFC bucket. Finally, we learned to scope ruthlessly under time pressure. Product replacement was on our roadmap and we made meaningful progress on it, but recognizing when to cut a feature and double down on what was already working was one of the most valuable decisions we made during the hackathon.
What's next for Spotlight
The immediate next step is product replacement — using the mask we generate to composite a different brand's product into the scene using Stability AI inpainting, so a KFC bucket becomes a Popeyes bucket without touching a single frame manually. Beyond that, the natural expansion is from clip-level analysis to episode-level and series-level analysis, giving brands a dashboard that tracks their product placement ROI across an entire Netflix season. We also see a clear path to real-time overlays — using the mask to place a clickable buy-now badge directly on top of the product as a viewer watches, turning passive product placement into an interactive commerce moment. Spotlight is the infrastructure layer that makes all of this possible, and we have only scratched the surface of what it can do.

Log in or sign up for Devpost to join the conversation.