-
Introduction page of SpotAI
-
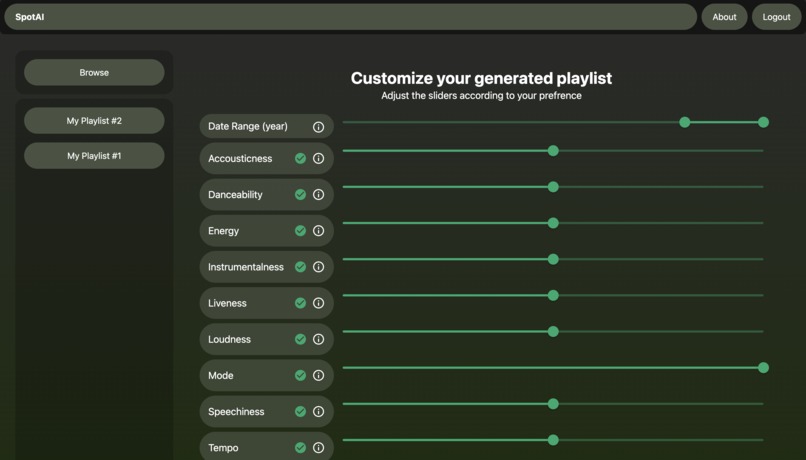
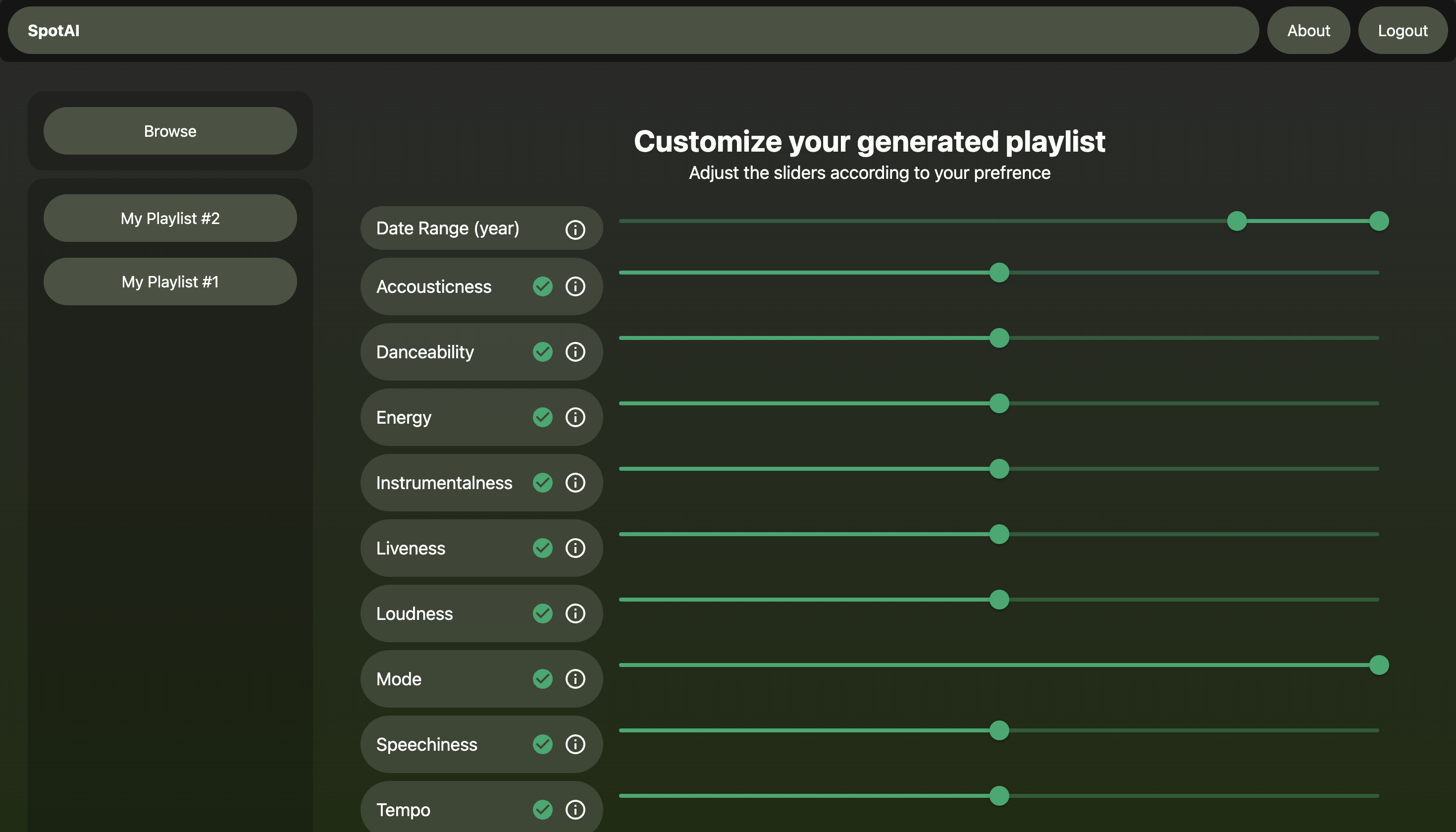
Model custom features
-
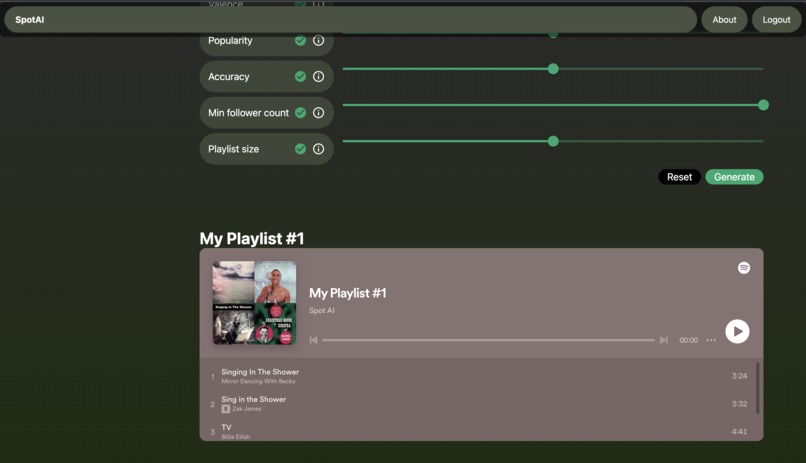
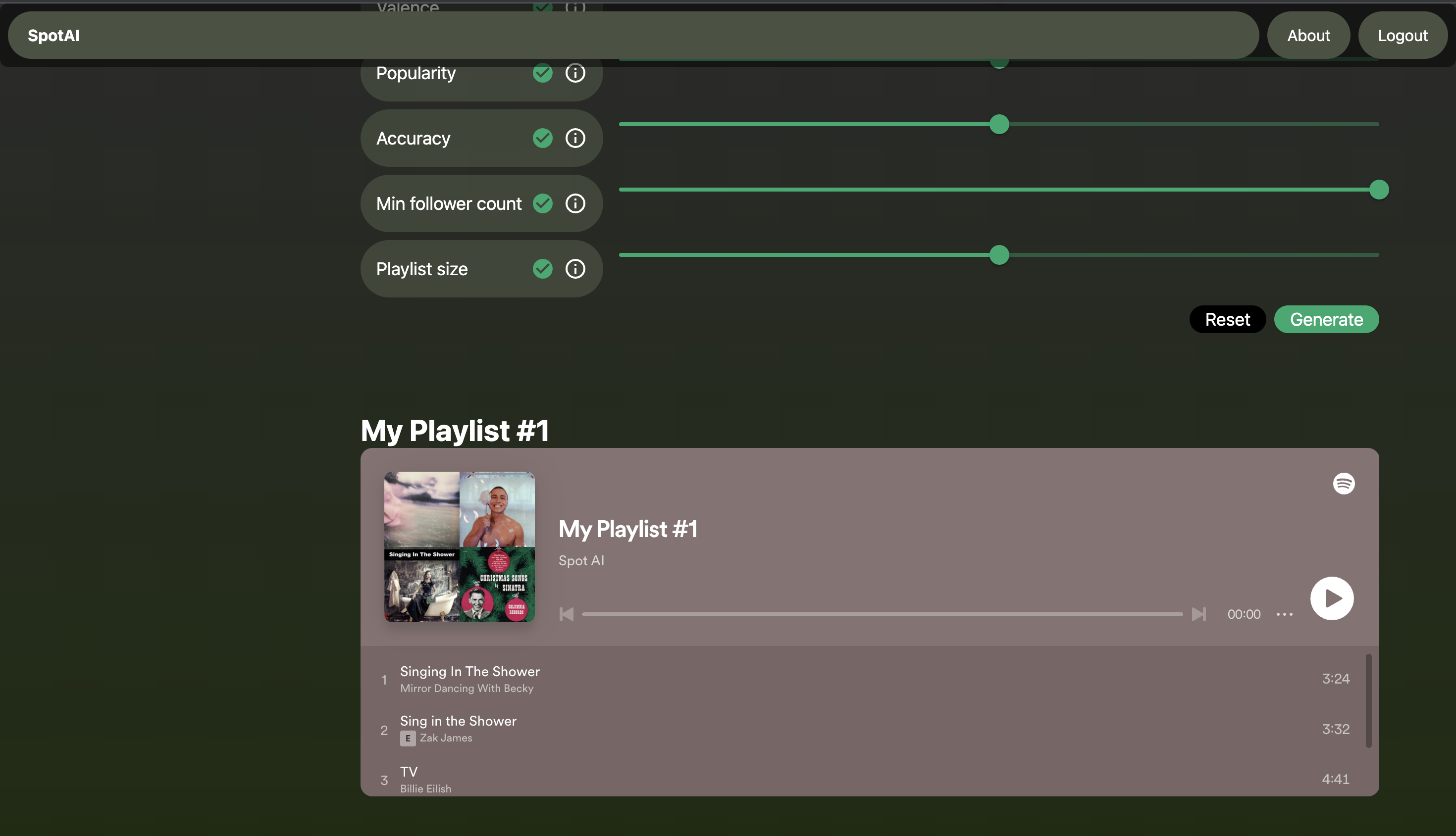
Generated playlist
SpotAI
Inspiration
Finding favourite songs among massive song datasets has become a difficult problem. Although popular music providers like Spotify and Apple Music attempted to create sophisticated autoplay algorithms, they do not provide the model variables to the users. We believe we are entitled to a minimal version of feature selection which reduces reliance on automated algorithms that often do not seem to output the best results. Hence why we rewind our playlists more regularly than enabling autoplay. As individual developers, we strongly believe in open-sourcing models that track user behaviour as a cooperative way of Software development that benefits all users.
What it does
We decided to tackle this problem by creating our model and providing a console containing 15 song features to edit. We created a database starting with an open-sourced dataset from zenodo, and we populated it with millions of songs' features from the Spotify API. The application will welcome the user with a homepage that will prompt for user login. Upon providing credentials, the user is forwarded to the main console containing 15 variables to edit. The algorithm will automatically analyze the selected playlist and initialize the model variables. The variables are selected upon clicking on the checkmark if the user wishes. The generate button will create a playlist of the recommended tracks that can be played from the application.
Additionally, we provide the user with one of two options:
- use the small dataset (4000 songs) for testing purposes
- use the large dataset (up to 15 million songs) for a general use-case
We also created a Grafana dashboard that provides analytics on our dataset, as well as tracks system usage using Prometheus.
How we built it
We built SpotAI as a responsive web application enabling as many model variables as we can. The front end is made with React, vite, and tailwind CSS. We implemented Spotify's iframe to display playlists and play songs, and Spotify's authentication protocols to safely provide login credentials. The server side is built with Python's flask, and we used MySQL for a backend database. To test our API, we used swagger (flasgger on Python).
We also worked with Grafana and Prometheus to offer visualization using their proprietary UI.
Challenges we ran into
When dealing with the large 36Gbs dataset, we suffered from long-running queries. The proposed solutions for the future are either optimizing our model by introducing indexes and caching solutions or dropping MySQL in favour of hiveQL that scales horizontally and runs on a parallel distributed environment like Spark.
We also struggled to host SpotAI on a GCP micro server instance. We were able to expose the application URL to
the outside world, but it was not establishing a MySQL connection (from within the instance).
Finally, deploying the application on the cloud was painful without using a dockerized solution (docker-compose).
Accomplishments that we're proud of
We intended to build an application that we can use EVERYDAY. I am proud that we achieved something that major music providers did not. We provided more freedom to the user without compromising their experience.
What we learned
We got to experience deploying an application on GCP for the first time. It was also our first time working with Grafana and Prometheus thanks to DRW's workshop.
What's next for SpotAI
As a team, we decided to continue working on improving SpotAI and implementing solutions to the challenges we faced. We are also making it a priority to fix our GCP deployment and make SpotAI accessible to everyone through a trusted domain.







Log in or sign up for Devpost to join the conversation.