-
-
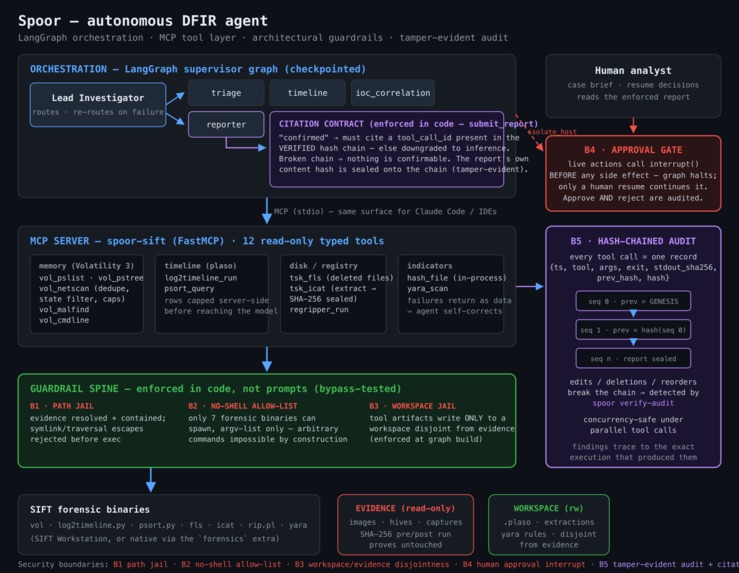
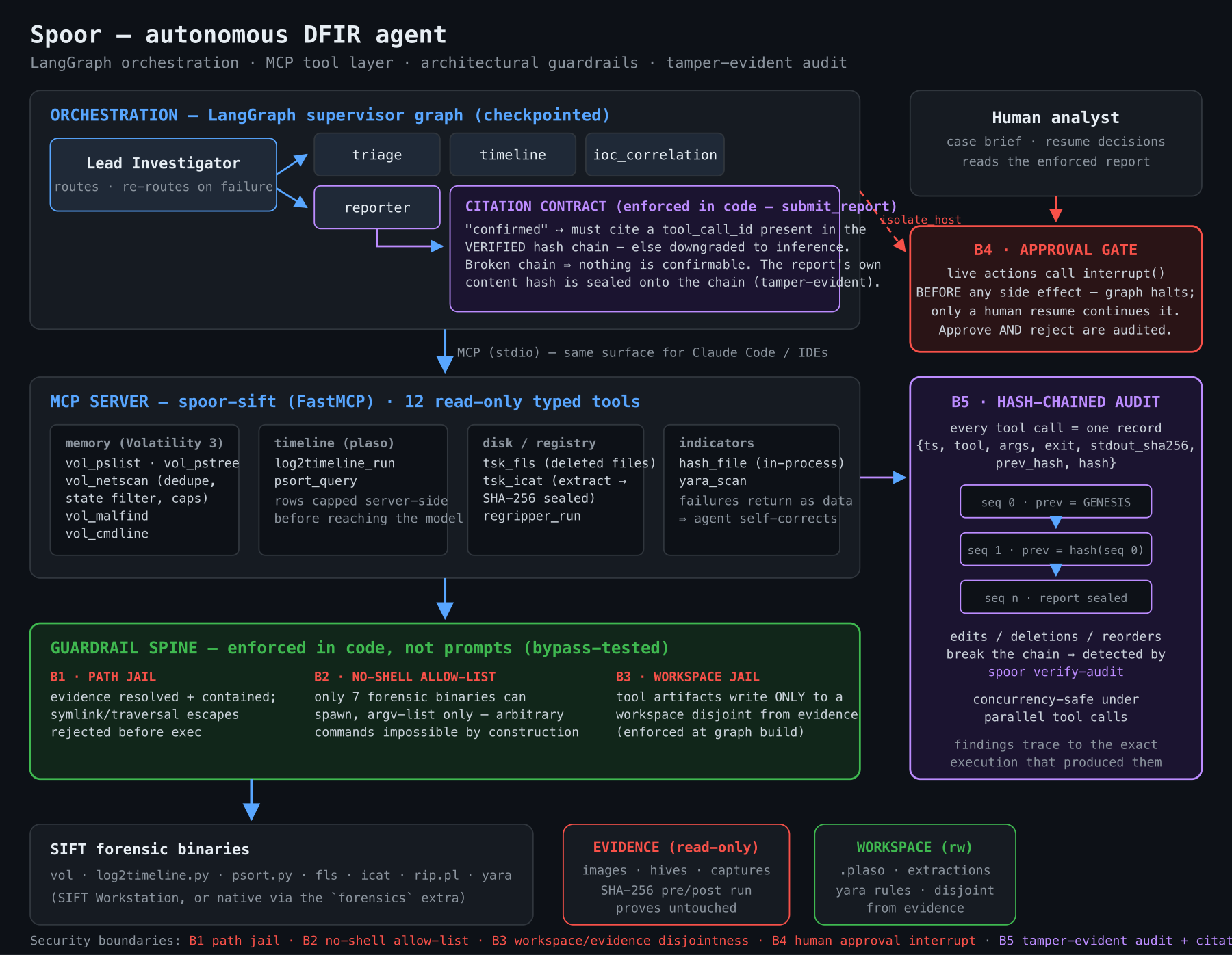
spoor architecture
Inspiration
The hackathon brief named the fear out loud: the thing standing between an LLM and a real incident-response seat is hallucination. An analyst who invents a process, a beacon, or a logon is worse than no analyst — a confident wrong answer gets acted on, and in IR that means pulling the wrong box off the network at 3 a.m.
So we didn't start from "make the agent smarter." We started from a harder question: why would a responder ever trust an autonomous agent's report? Our answer is the same reason they trust volatility or dd — every claim is tied to a verifiable execution, and the evidence is provably untouched. Trust is architectural, not hoped for.
What it does
You point Spoor at a piece of evidence and give it one prompt. A LangGraph multi-agent graph — a Lead Investigator routing triage, timeline, IOC-correlation, and reporter specialists — works the case autonomously and returns a report where every confirmed finding cites the exact tool call that proves it.
On the real DFIR Madness Case 001 ("The Stolen Szechuan Sauce") domain-controller memory image (2.1 GB), driving native Volatility 3, Spoor found the evil on its own:
- coreupdater.exe (PID 3644) — a rogue process with a phantom parent PID (2244, a process that doesn't exist), no command line, alive ~15 seconds before self-terminating.
- A confirmed C2 channel: 10.42.85.10:62613 -> 203.78.103.109:443, ESTABLISHED, owned by that process.
- Code injection — 15 anonymous PAGE_EXECUTE_READWRITE regions across 5 processes, including the Active Directory Web Services process on the DC.
- An attacker Session-2 logon — a second interactive session on a domain controller.
Anything Spoor can't back with a tool execution is labeled an inference, not a finding — enforced in code, not in a prompt.
The trust stack (the part that's different)
- No hallucinations. A finding is confirmed only by citing a
tool_call_idin the verified audit chain;submit_reportdowngrades the rest to inferences, deterministically. Real-run result: hallucination rate 0.000. - Tamper-evident audit. Every tool call appends a hash-chained record; flip one byte and the chain breaks.
spoor verify-audit-> 8 records, chain intact. - Evidence never touched. SHA-256 of the image is byte-identical before vs. after the run — read-only proven, not asserted.
- Guardrails that fail closed. Path traversal, absolute-path escape, symlink escape, non-allow-listed binary — all four rejected in code (
spoor demo-guardrails). - Human in the loop. Destructive actions interrupt() for approval before any side effect.
Accuracy, measured honestly
Scored against the memory-visible subset of the verified answer key: recall 0.500 · precision 0.250 · F1 0.333 · hallucination 0.000.
Recall 0.50 with zero hallucination means Spoor found the real malware and the real C2 — and cited both. Precision 0.25 is over-reporting, not fabrication: the same rule that credits coreupdater.exe also flags five legitimate Windows binaries that genuinely carry injected RWX regions — real anomalies, just not in the curated 4-item key. And we show our work: mid-build we caught our own scorer dropping the malware detection, fixed it test-first, and published both the raw and corrected numbers. Self-correction in the open is the whole thesis.
How we built it
- Python 3.12 + LangGraph: a supervisor graph routes a Lead Investigator over triage / timeline / IOC-correlation / reporter specialists across a shared case state, with a checkpointer and a completeness gate.
- An MCP server exposing 12 read-only forensic tools over stdio — usable by the agents and by any MCP client.
- Native Volatility 3 plus Sleuth Kit, RegRipper, plaso, YARA — every tool behind one spine: typed input -> guardrails -> no-shell allow-listed runner -> hash-chained audit record -> structured JSON.
- Five security boundaries with live bypass tests, and 112 tests, TDD-first.
- Runs on Claude Sonnet 4.6 via OpenRouter; no key committed.
What we learned
Trust in an autonomous agent is an engineering property, not a model property. The model finds the evil; the harness — citations, audit chain, guardrails, integrity proof — makes the answer usable. The most credible number we have is the one that made us look worse.
Challenges we ran into
- Driving a real 2.1 GB image without drowning the model — server-side row caps, netscan dedup, token budgeting.
- Enforcing citations without crushing recall — the contract had to be deterministic, in
submit_report, not a prompt. - The honest scorer-correction call: the fix lowered our headline precision. We shipped it anyway.
What's next
- More public cases to move accuracy off a single sample.
- Richer IOC typing (malicious-file vs. injection-site) to close the precision gap honestly.
- Full SIFT timeline on the workstation disk image. ## How we built it
Challenges we ran into
Accomplishments that we're proud of
What we learned
What's next for Spoor — autonomous DFIR you can audit
Built With
- anthropic-claude
- langgraph
- mcp
- python
- sift
- volatility3

Log in or sign up for Devpost to join the conversation.