-
-

Slide 1
-

Slide 2
-

Slide 3
-

Slide 4
-

Slide 5
-

Slide 6
-

Slide 7
-

Slide 8






Sponge
Inspiration
While interviewing for selective software engineering roles, we noticed something unexpected. Several companies were allowing and even encouraging candidates to use AI tools during technical interviews.
This was not a novelty. It was part of the evaluation.
They were not only testing whether you could write code. They were testing whether you could think clearly and collaborate effectively with AI.
We looked for a way to practice that. Everything we found trained people to solve problems alone, as if AI tools do not exist.
So we built the platform we wanted to use ourselves.
What it does
Sponge is a coding interview simulator built for AI assisted problem solving.
Candidates are placed inside a real Python codebase. The repository is RQ v1.0, an open source job queue library. The task is specific and practical. Implement delayed job execution using enqueue_in and enqueue_at.
Each session includes:
45 minutes
A full in browser editor with the complete file tree
An AI assistant that can be used freely
When the session ends, the submission is scored on two components.
Test accuracy accounts for 50 percent of the score. Twenty automated tests run against the candidate’s implementation. Twelve tests are visible during development. Eight additional tests are hidden and only run at submission. These cover edge cases, scheduling behavior, and correctness under realistic conditions.
Collaboration quality accounts for the remaining 50 percent. The full session log is evaluated, including file edits, test runs, and AI interactions. The rubric measures problem solving, code quality, verification habits, and communication clarity. We also detect patterns such as never running tests or pasting AI output without modification.
The final score combines both dimensions.
How we built it
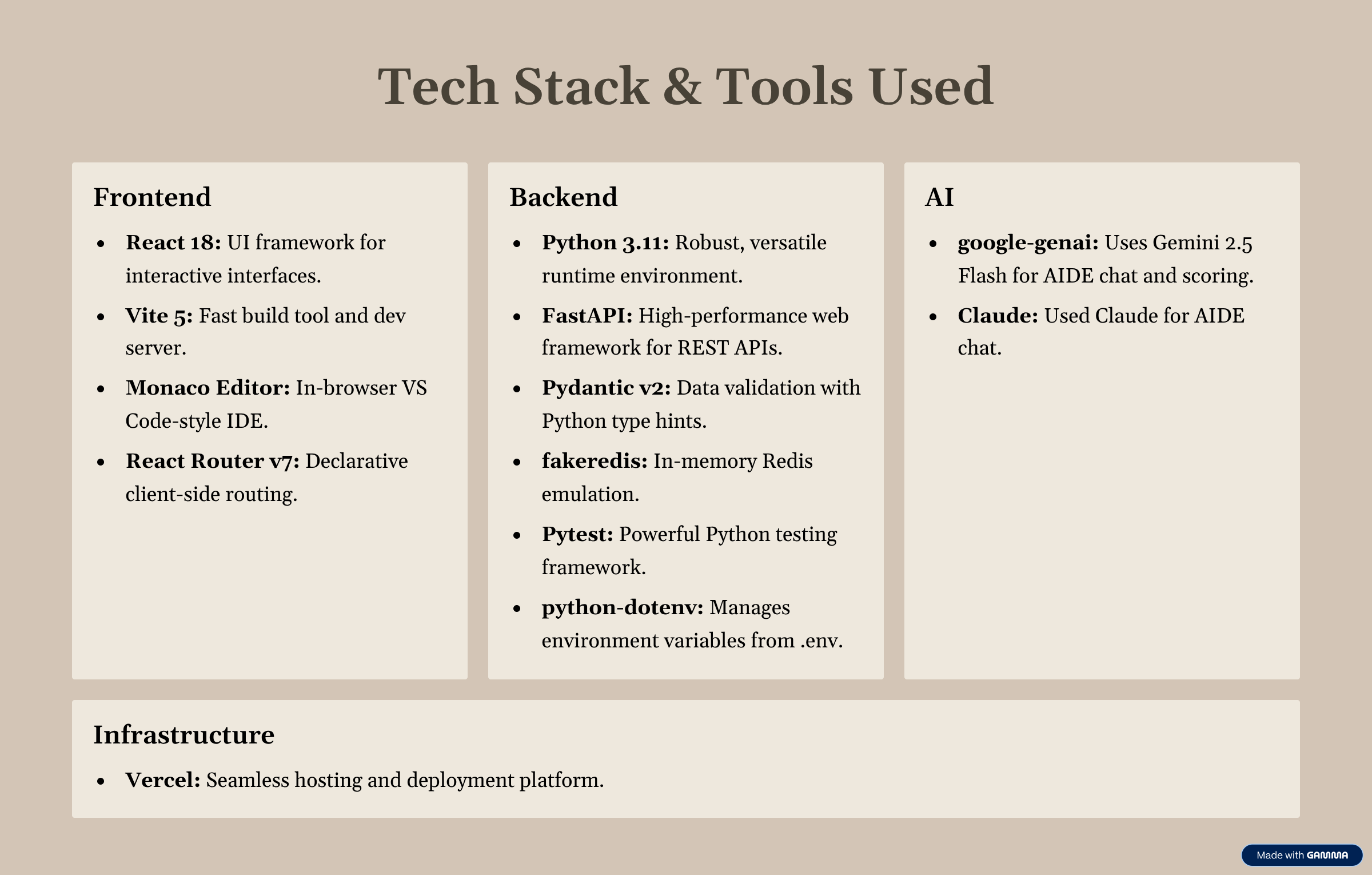
Frontend
The frontend is built with React and Vite. The editor uses Monaco and mirrors the full RQ repository structure. Every edit, chat message, and test run is stored as a timestamped event in the session log.
Backend
The backend is built with FastAPI and deployed on Vercel. It handles session management, file reconstruction, test execution, and scoring.
Test runner
When a candidate runs tests, their modified files are layered onto a clean copy of the RQ codebase inside a temporary directory. Pytest executes the visible test suite. On submission, the hidden tests run as well. Results are parsed from JUnit XML into structured pass and fail data.
Scoring engine
Gemini processes the complete session event log and evaluates it against a rubric across four dimensions: problem solving, code quality, verification discipline, and communication. Test accuracy is calculated directly from pass rate. Collaboration scoring is derived from behavioral signals in the log.
AI assistant
The AI assistant uses the Gemini API with a constrained system prompt. It is designed to help with reasoning and debugging without simply handing over the final implementation.
We used proper pair-programming practices to build out this project using Claude Code and Cursor.
Challenges
Running Python subprocesses on serverless infrastructure was the hardest technical issue. The Vercel runtime behaves differently from a traditional server. Package visibility, import paths, and temporary directories required careful handling to make pytest run reliably.
We also dealt with silent failures. Early versions of the test runner would fail without returning meaningful error output. We fixed this by surfacing full stdout and stderr traces back through the API.
Accurate delivery of the RQ source code required more care than expected. We initially embedded the source manually into a JavaScript file. One file was accidentally truncated, which caused subtle import errors. We replaced this with a generator script that rebuilds the snapshot automatically from the source.
Scoring AI collaboration remains the most uncertain part of the system. There is no objective ground truth for effective AI usage. The rubric is iterative and will continue to evolve.
What we are proud of
The test runner works reliably on serverless infrastructure.
The hidden test suite catches shallow or hardcoded solutions that pass only the visible tests.
The scoring model is transparent. Half the score comes directly from correctness. The other half comes from observable collaboration behavior.
The codebase is real. Candidates work inside a production library with real abstractions and constraints.
What we learned
Evaluating AI assisted collaboration is complex and not yet standardized.
Serverless environments are unforgiving when running subprocess heavy workflows.
Silent errors are costly. Every failure should return enough context to diagnose the issue immediately.
Technical interviews should measure how someone works under realistic conditions, not in isolation from modern tools.
What is next
Expand the platform with additional problem sets across different codebases.
Build a recruiter dashboard that allows session replay and deeper evaluation beyond a single score.
Benchmark the scoring rubric using controlled test populations to calibrate weights.
Introduce real time pair sessions where two candidates collaborate in the same environment.
Pilot Sponge with companies that want to evaluate AI native engineering skills.




Log in or sign up for Devpost to join the conversation.