-
-
This is agent test, the villian website that splice must try to overcome
-
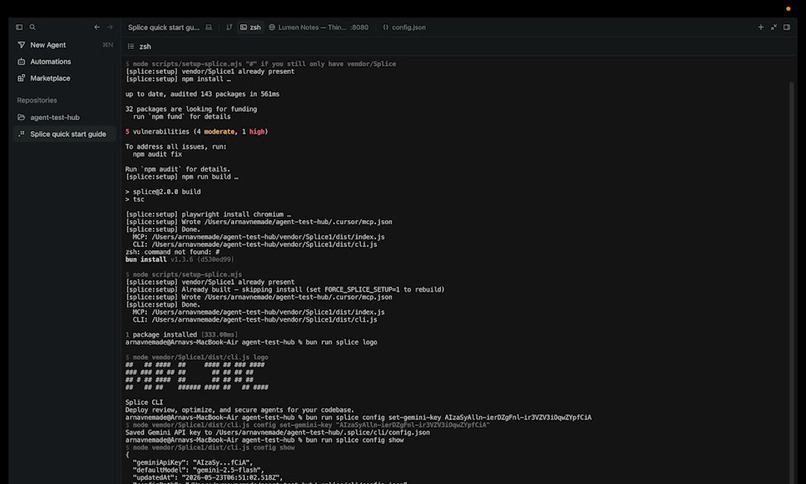
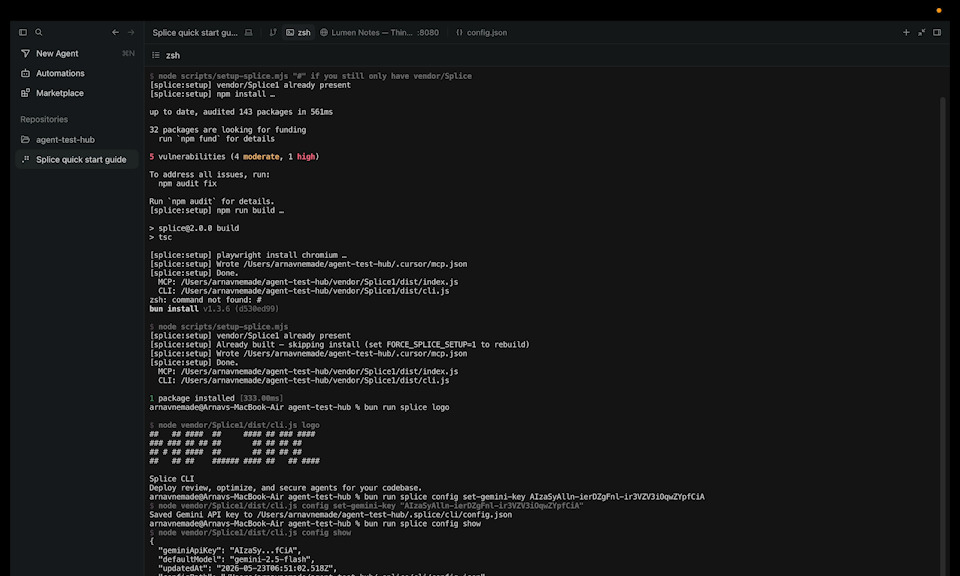
This image shows splice running in the terminal and its interactive CLI
-
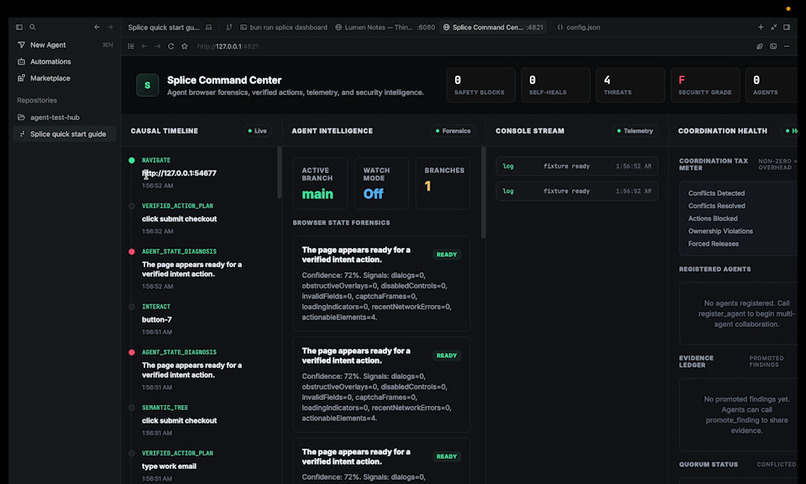
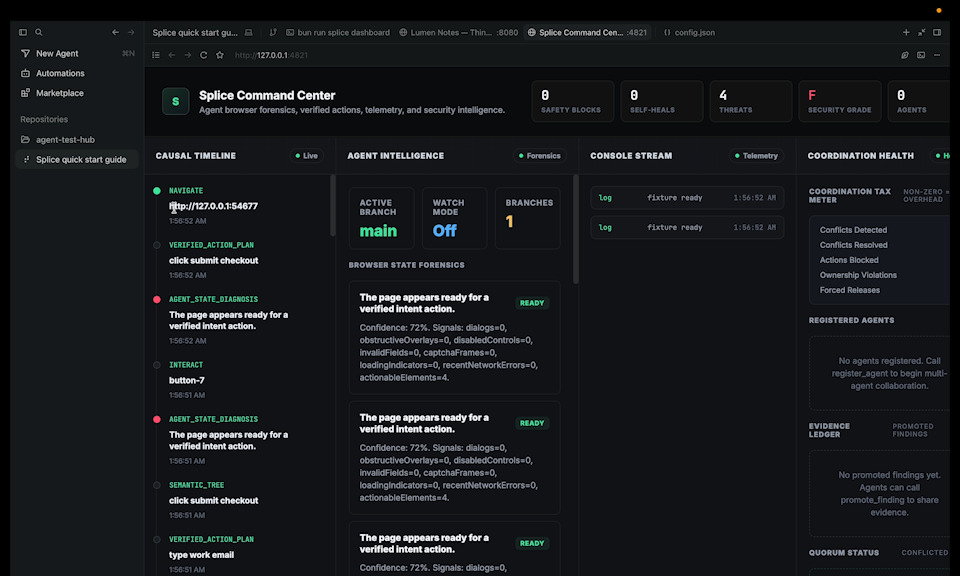
This is our localhost dashbaord that allows us to see exactly what issues splice and the agent face in a timeline
-
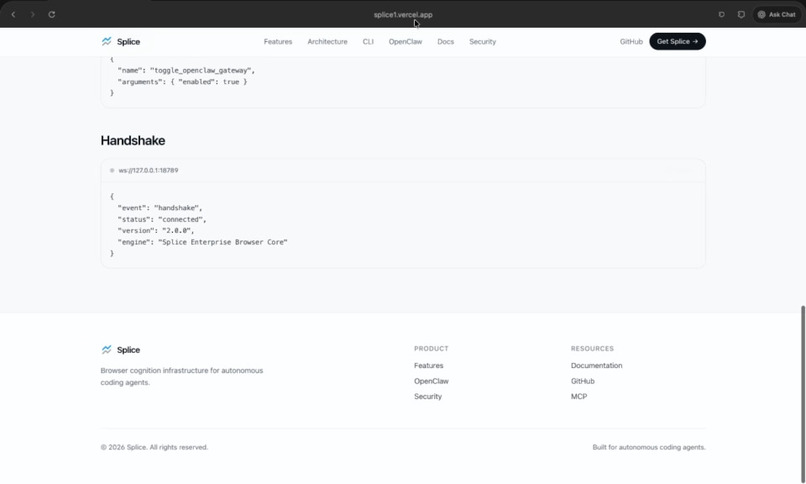
Openclaw Integration
-
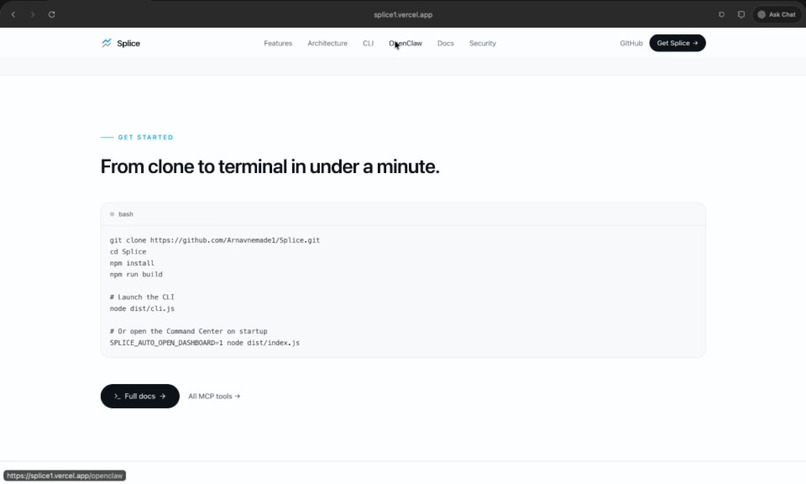
CLI
-
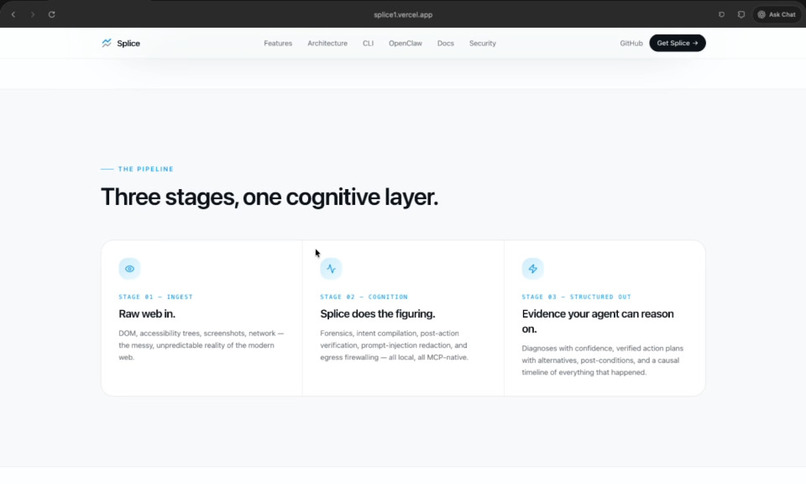
Architecture
-
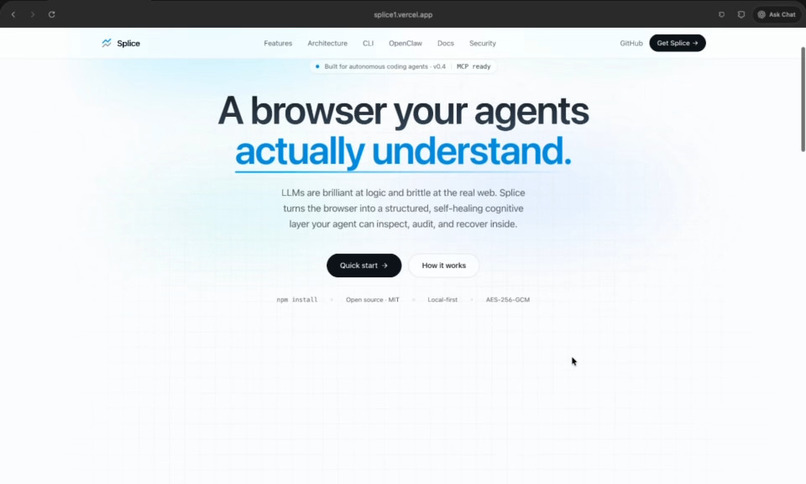
Features Page
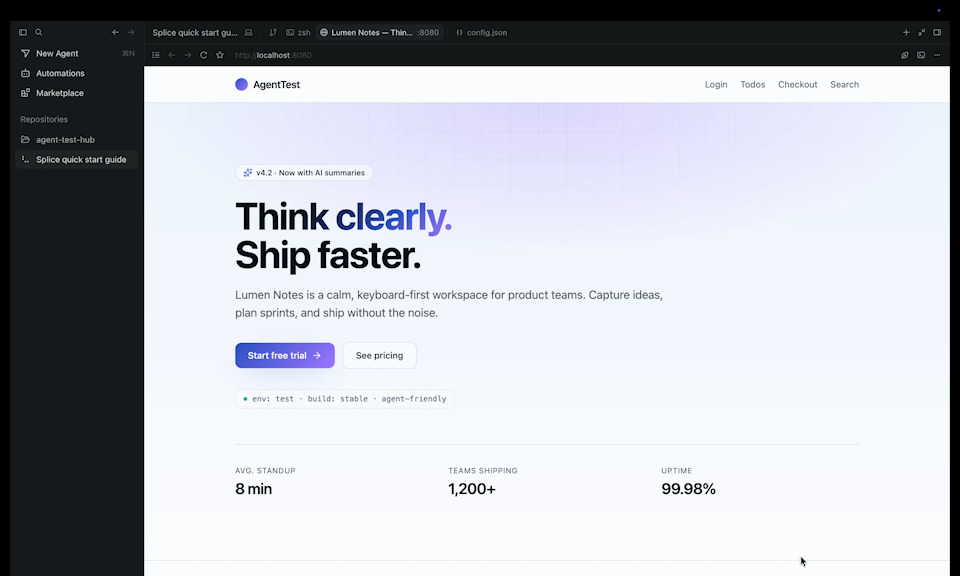
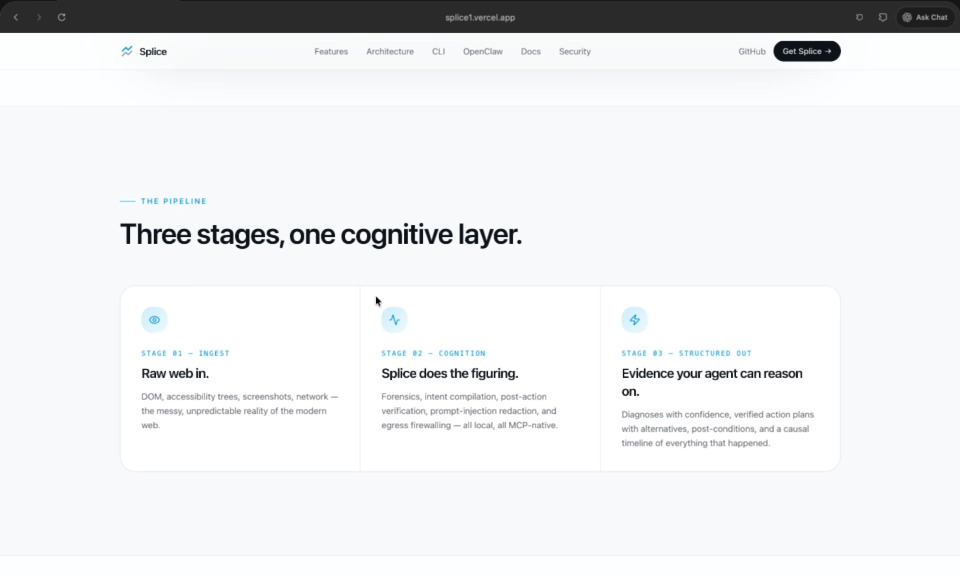
Inspiration
AI agents are getting better at reasoning, but they still struggle when they have to actually use the web. A real webpage is messy: buttons disappear, forms fail validation, popups block the screen, CAPTCHA interrupts workflows, and agents often do not know why they failed. That inspired me to build Splice, an ambitious browser-agent infrastructure concept focused on making autonomous web agents safer, more observable, and easier to debug. Instead of only asking, “Can the agent click the button?”, I wanted to answer a more important question: when the agent fails, can we understand why?
What Splice does
Splice is a prototype for secure browser infrastructure and observability for autonomous web agents. In its current working state, the main functional part is the error and failure-diagnosis system, as shown in our demo video. The system can surface issues when an agent workflow breaks, such as blocked interactions, missing elements, validation problems, and failed browser actions. Instead of failing silently, Splice helps show what went wrong. The larger vision includes semantic browser understanding, security checks, agent coordination, OpenClaw integration, and request-for-human-intervention workflows. However, I want to be clear that some of these features are still conceptual. The OpenClaw integration and human intervention request flow represent where we want Splice to go, but they are not fully working production features yet. The full functionality of splice is only as seen in the video.
How we built Splice
I built Splice using TypeScript, Node.js, Playwright, and the Model Context Protocol SDK. Playwright handles browser automation, while the MCP structure gives Splice a path toward becoming a tool server that AI agents can connect to. The core idea was to create a browser manager that can navigate pages, inspect browser state, track actions, and report problems when an agent gets stuck. I also began building a larger architecture around telemetry, security auditing, browser snapshots, multi-agent coordination, and dashboard-style observability. Because Splice is a super ambitious idea, we focused the working demo on the error-detection and debugging side first. That became the proof of concept for the bigger system.
Challenges we ran into
The biggest challenge was the scope. Splice is not a simple web app. It is closer to infrastructure for autonomous AI agents, which means it touches browser automation, security, state management, telemetry, agent coordination, and human-in-the-loop recovery. I also ran into the reality that browser agents are difficult to make reliable. A page can fail for many reasons: the element might not exist, a modal might block the screen, the form might be invalid, the browser state might be stale, or the agent might be trying to act on the wrong target. Some features, like OpenClaw integration and human intervention requests, are part of the long-term vision, but they are still conceptual. The working part we can clearly demonstrate right now is Splice’s ability to surface errors and explain failure states.
Accomplishments that we're proud of
Im proud that Splice is more than a browser wrapper. It feels like real infrastructure for agentic browsing. It has browser branching, telemetry, semantic extraction, encrypted snapshots, local dashboards, security scanning, verified browser actions, and multi-agent coordination in one system. I am especially proud of the Command Center and validation flow. The project can generate local observability reports, validate OpenClaw status through WebSockets, and serve the dashboard through a local Command Center server. I'm also proud that it was designed to integrate with real agent systems. The integration guide shows how to connect it to a generic MCP client, an agent swarm, or Claude Desktop, which makes the project feel usable beyond just a demo.
What we learned
I learned that browser automation is much harder than just opening a page and clicking buttons. The real challenge is understanding context. An agent needs to know what is on the page, what is blocking it, what went wrong, and whether it is safe to continue. I also learned that ambitious infrastructure projects need to be broken down into smaller working pieces. For Splice, that first working piece became error detection and observability. Once that foundation exists, the larger concepts like OpenClaw integration and human intervention become easier to build toward.
What's next for Splice
Next, I want to turn the conceptual pieces into working features. That means making the OpenClaw integration functional, building out the request-for-human-intervention system, improving the dashboard, and expanding the error-diagnosis engine into a more complete agent recovery system. I also want to improve the semantic browser layer so the agent can understand pages more clearly and act with higher confidence. Long term, Splice could become a full observability and safety layer for autonomous web agents, helping them browse the internet without failing blindly or acting unsafely.
Built With
- anthropic
- chromium
- cli
- codex
- cursor
- discord
- gemini-api
- github
- html
- javascript
- json
- mcp
- node.js
- openai
- playwright
- typescript
- vscode

Log in or sign up for Devpost to join the conversation.