-

Facial Recognition
-
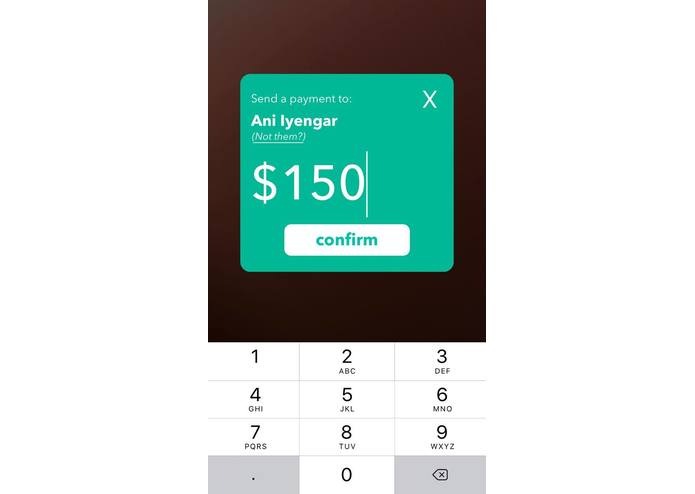
Personal Transfers
-
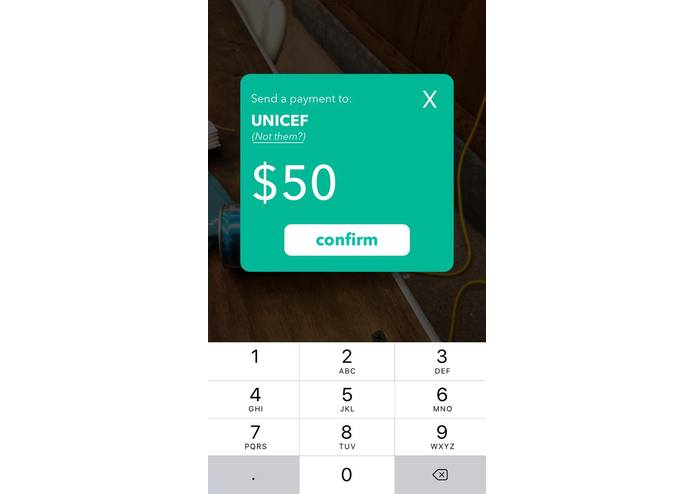
Organizational Donation
-
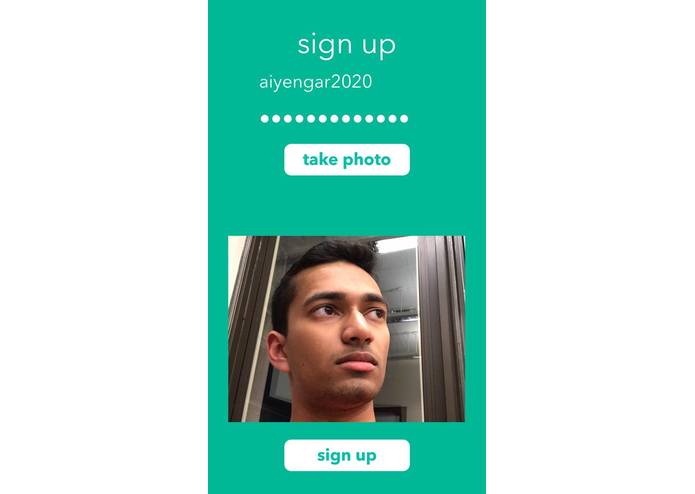
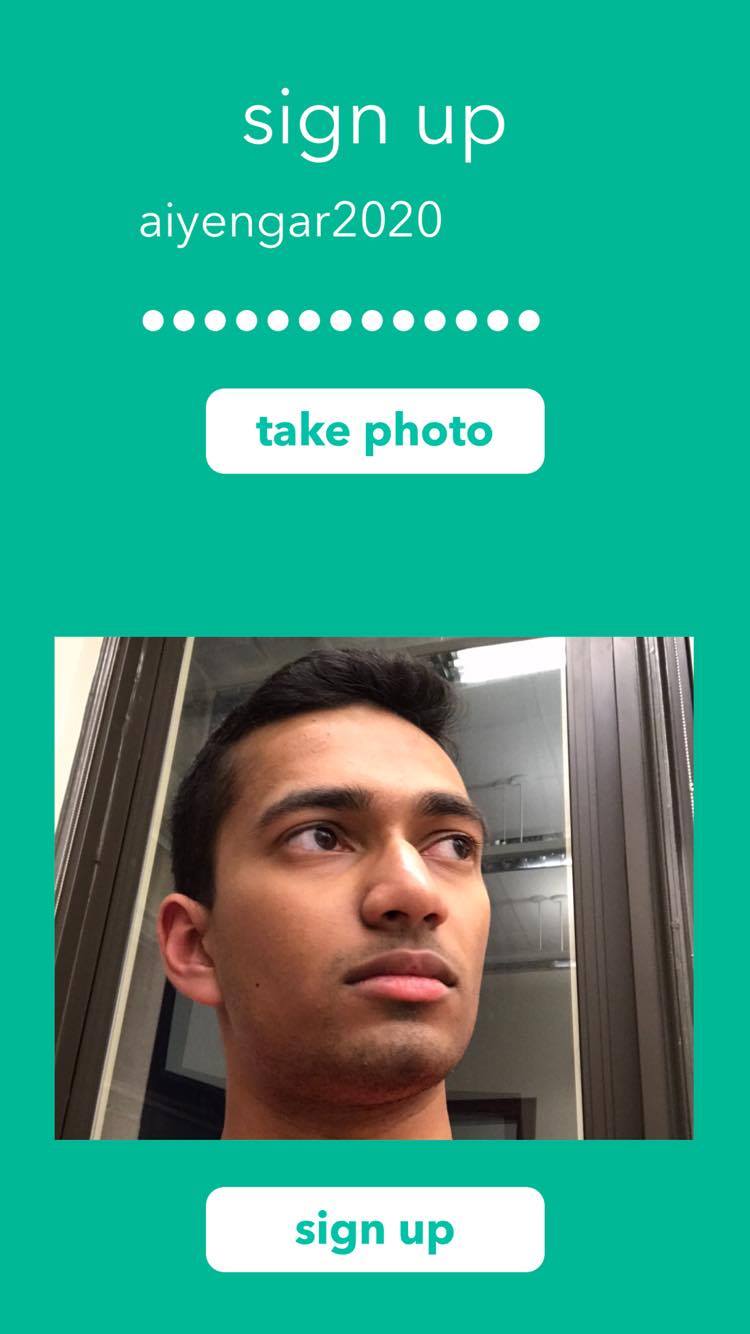
Creating an Account
-
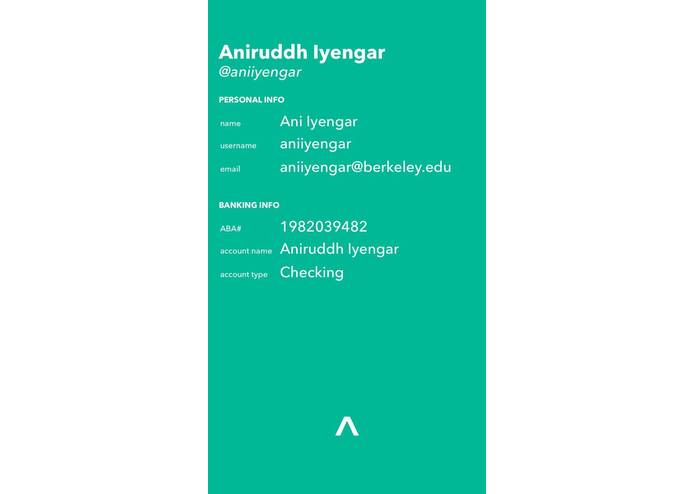
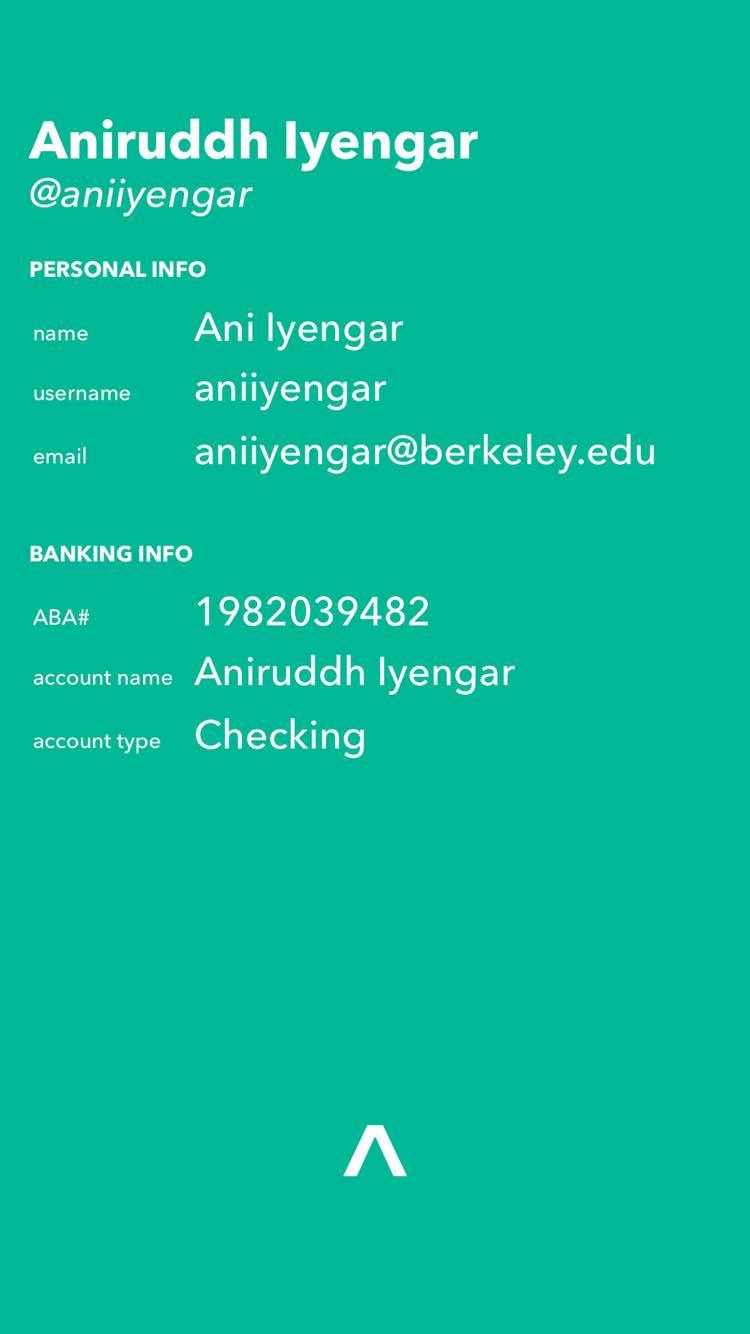
Account Details
-
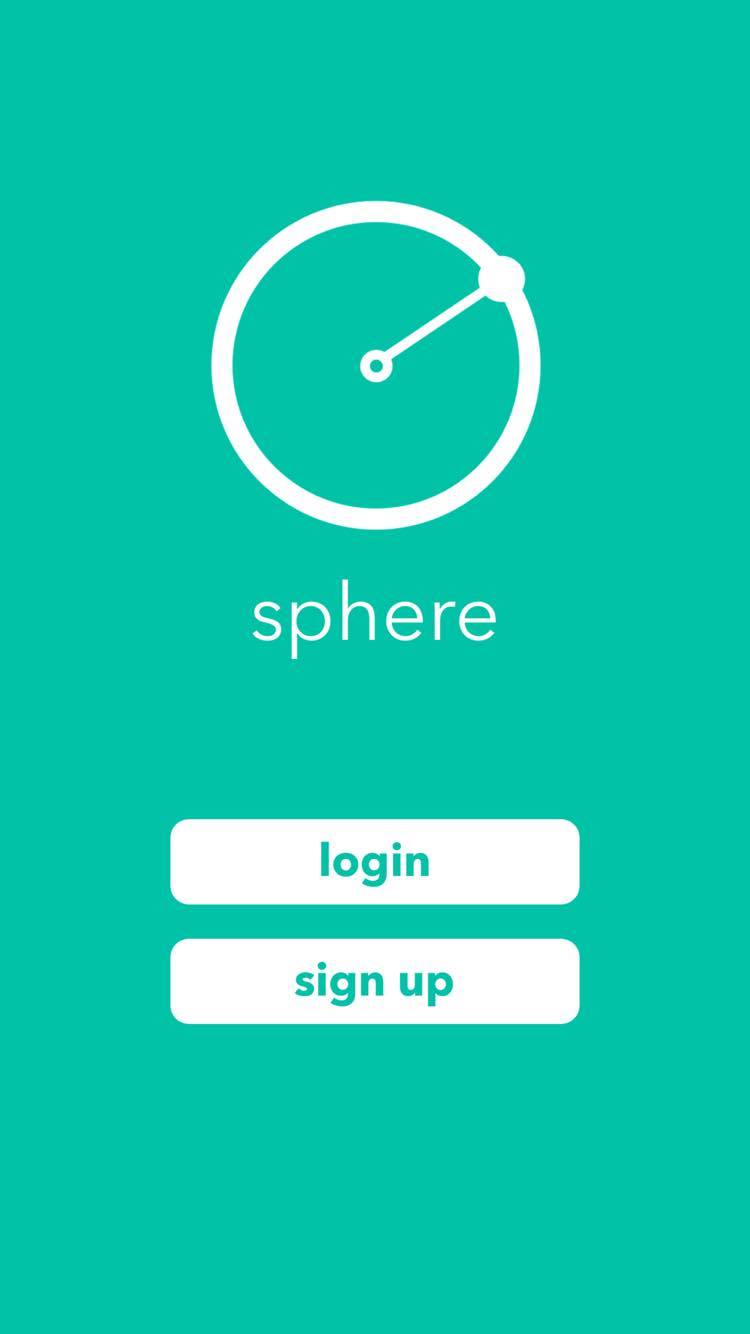
Opening Screen
-
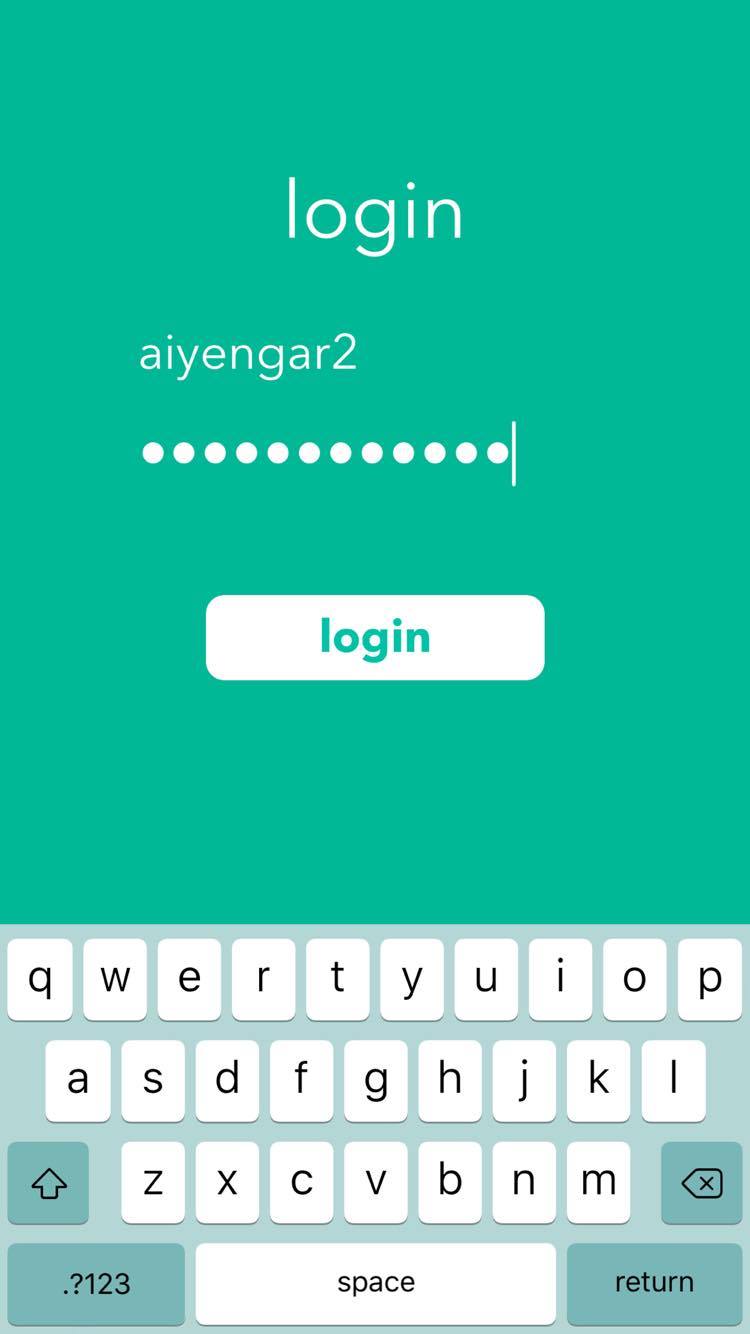
Login UX

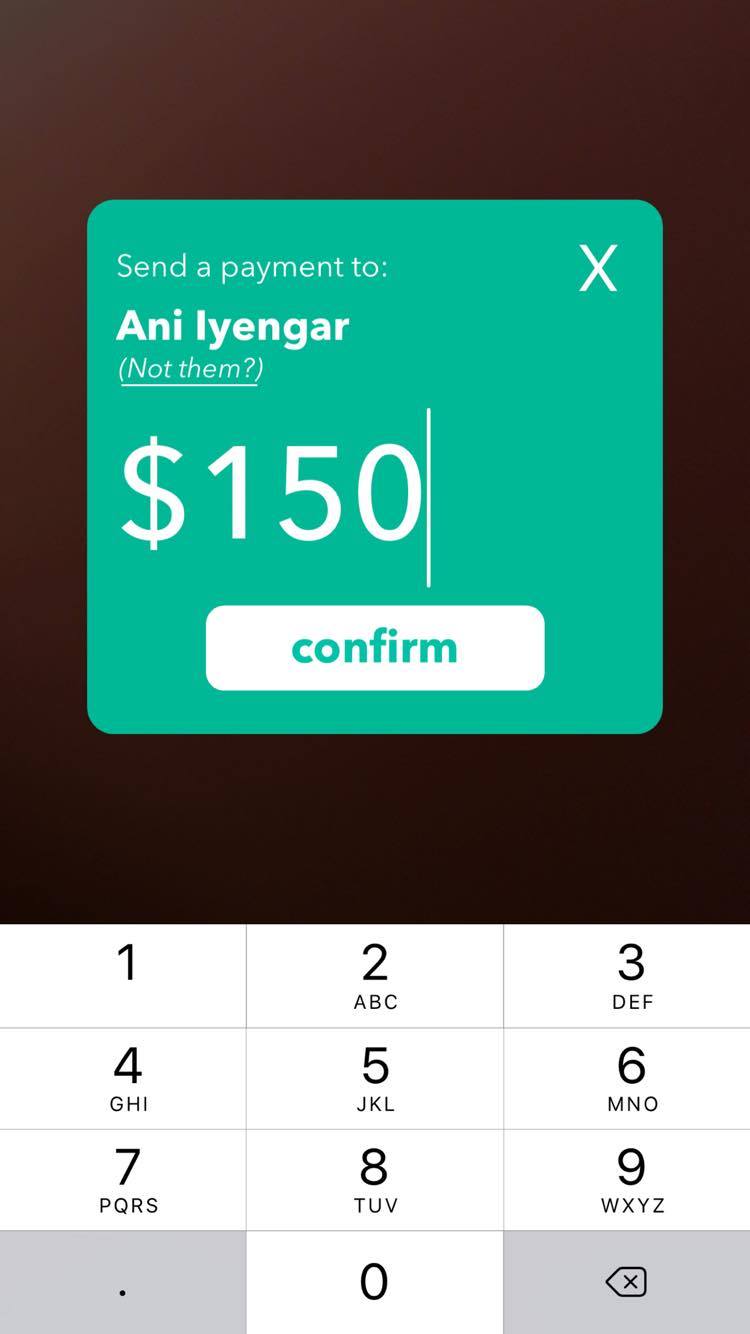
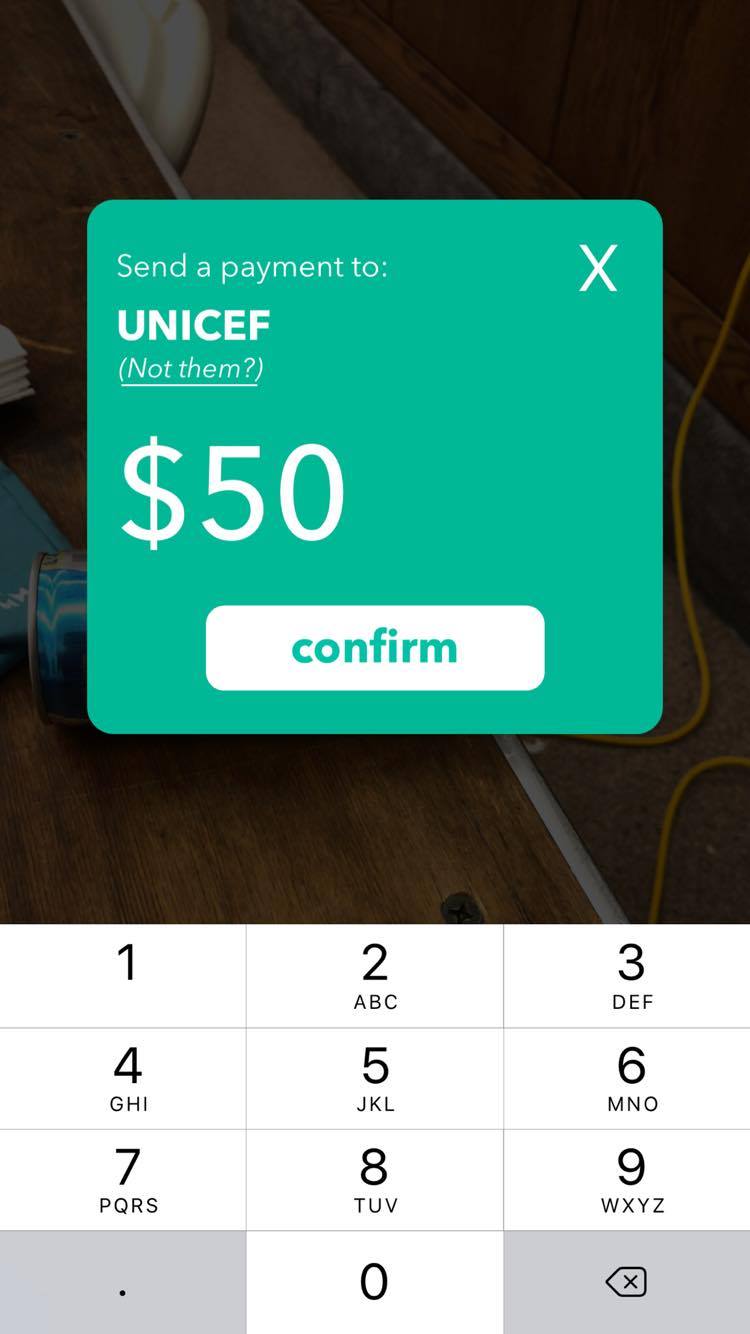
Inspiration
Millions of spontaneous money transfers occur everyday, but the mobile experience remains mundane and takes too long. We realized that one of the biggest barriers to donating money is that people don't know how to, and when it comes to transferring money to people, users are frustrated by the menial particulars such as routing numbers, usernames, phone numbers, email addresses, etc. We wanted to simplify the process of donating money to organizations or transferring money to people through a single seamless process that requires raising a phone camera to the recipient. By reforming the mobile money transfer process, we believe we can revitalize civic and social participation by reducing traditional barriers to funding.
What it does
Sphere enables money transfers by simply pointing your phone toward the person/organization you would like to transfer to— a user holds their camera towards the person or organization they want to send money to (who have to be on our platform), and our facial recognition and machine learning algorithms determines the person or NGO through a support vector machine (SVM). The user is then prompted to confirm if the system-determined person or NGO is correct— if it is wrong, the user simply inputs the correct person or NGO’s username and this serves as negative reinforcement for the training algorithm. If the system prediction is correct, the snapped picture serves as positive reinforcement for training. Through this dual reinforcement process, our model gets increasingly accurate based on how often our app is used. After prompting for the correct recipient, the user must determine the amount they would like to transfer and we would facilitate a transfer between the user’s designated bank account to the recipient’s— essentially, we reduced the money transfer process to 3 taps, while maintaining security and precision. Our platform is encrypted end-to-end through an OAuth2 system.
How we built it
We wrote our iOS frontend in Objective-C. Our backend was written in Python using Flask, and we used the Clarifai API for image recognition, and the Capital One Nessie API for banking data. Our user data was stored in a PostgreSQL database. We got our sample images for our image classification through a combination of taking pictures of ourselves (the teammates) and an extensive dataset from Yale. We mapped these images and their classifications with Capital One Nessie accounts. As a proof of concept for charitable donations, we took 10 major organizations and manually classified them for our training algorithm. Then, we used the JustGiving API to donate to charities, but its not necessary as our bank accounts are dummy accounts. We also used the bcrypt library for recursive hashing, and OAuth for our client tokenization protocol.
Challenges we ran into
We basically created a complete money transfer platform. There were really 5 big overarching challenges.
- Encryption. It was key to ensuring that information could be kept secure. Not only is the Nessie API we used protected by high security standards, we reinforced our own login system with OAuth and protected all data behind layers of encryption based on the bcrypt library.
- Computer Vision. One of the most difficult aspects we came across was finding a solid cloud-based image classification API to use. We originally planned on using TensorFlow or OpenCV to do classification on our server, but with each person/organization representing a “class”, this path would have been extremely resource exhaustive for our limited resources on Heroku. Going through at least 4 APIs before returning to Clarifai, we found it difficult to find an API that allowed us to train our own models or setup thousands of classes on our own model.
- Integrating the Capital One Nessie API. Because our system was heavily reliant on the Nessie API, we had to create our own wrapper for Python. This was tedious and cumbersome, mainly because the documentation was slightly ambiguous. However, it offered a rich and immense set of dummy data which made this extra work extremely fruitful.
- Consuming the camera stream. The app's constant camera stream took input from the iPhone's outward-facing camera, which was processed for facial features and redrawn with overlays that indicate that the camera recognizes a face. This required the use of lower-level A/V libraries that took advantage of multithreading and asynchronous image capture. It also presented the challenge of memory management, since the extra processing took potential memory from other vital components of the app. These were solved largely by trial and error, but with it coming a deeper understanding of the inner workings of the iPhone.
- Design and user experience. Since our ultimate goal was to make money transfers as easy as possible, we needed to think hard about what features we needed, and which ones would simply burden the consumer. We reduced the entire app to a few screens, most of which were ancillary, and focused on the one main action that a user could take–-transferring money-–and made it as quick and intuitive as possible.
Accomplishments that we're proud of
All 4 of us came from different parts of the US, and we only shared one thing in common: building amazing user experiences with machine learning and data science. We are all quite mesmerized by how we came together and collaborated to create a full-fledged product in 36 hours. It helped us learn and grow as people through better team-work skills and as developers through learning new APIs and concepts.
Also, we are really proud about our machine learning integration, because although all of us had previous experience with it, none of us ever fiddled with computer vision.
What we learned
We learned that it is critical to have a clean UI and a seamless UX. We also learned that the predictive capabilities of machine learning are nearly unlimited in their application to everyday problems.
What's next for Sphere
We hope to add more organizations and non-profits onto our platform, and expand to more varieties of organizations and people. We also hope to rewrite our machine learning libraries with caching and parallel processing optimizations so we can expand the number of classes without being resource exhaustive or adding too much latency on our server.
Built With
- capital-one-nessie
- clarifai
- flask
- justgiving
- objective-c
- postgresql
- python








Log in or sign up for Devpost to join the conversation.