-
-

-

-

-

-

prototyped in figma



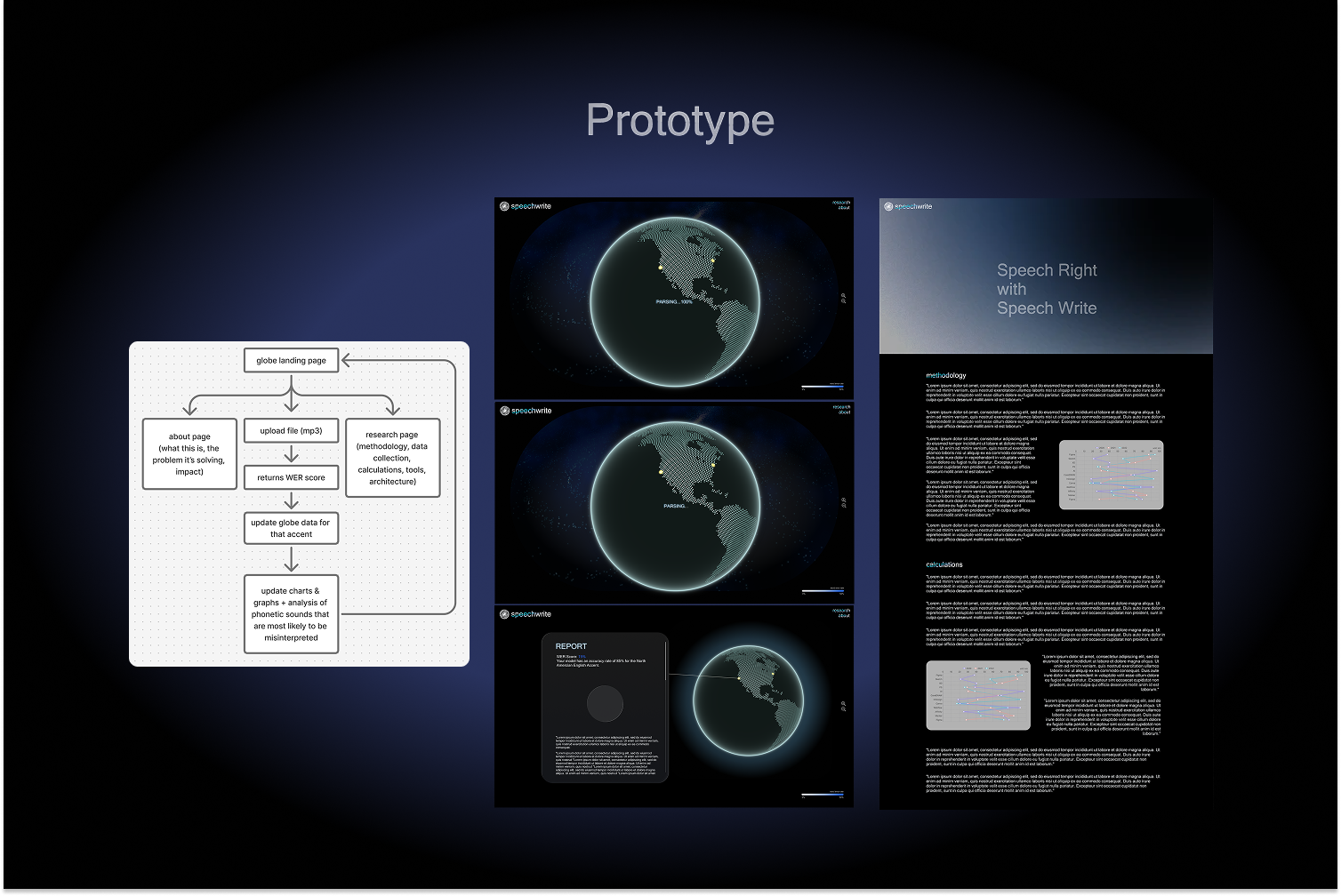
Inspiration
Have you ever tried watching a video with closed-captions, only to find out that the auto-generated subtitles didn't match what was being spoken at all? In the entertainment industry, speech-to-text technology has improved massively for movies and games. However, the algorithm for determining what words are actually being spoken still makes mistakes with larger biases toward certain accents and demographics.
We are also taking our first artificial intelligence courses this semester and were excited to apply what we learned in class to this project!
What it does
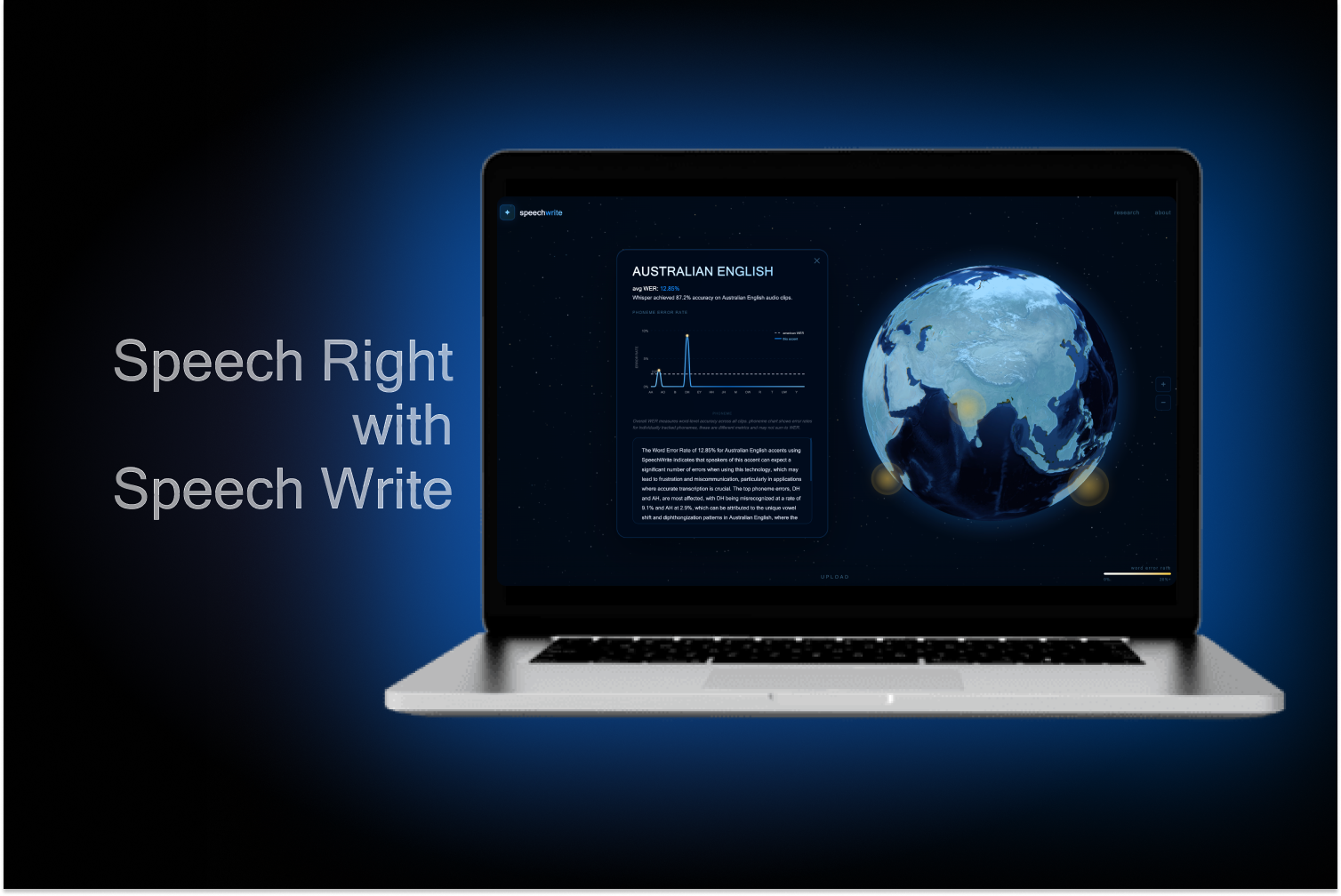
SpeechWrite measures how fairly automatic speech recognition systems treat speakers of different English accents, making global disparities visible and quantifiable. Our research reveals that speakers from non-Western backgrounds face error rates 2-5x higher. Going beyond just speech-to-text, this could directly impact access to entertainment, legal, and assistive technologies.
How we built it
Research
- Looked into how speech recognition systems break audio into phonemes and predict words
- Chose Mozilla Common Voice for open source audio (mp3) and transcript files with diverse accents
Model
- Transcribed audio with OpenAI's Whisper API
- Converted transcripts to phonemes
- Measured substitutions & deletions against the reference
Visualization
- Created a heatmap display of high error rate areas
- Used charts to show which phonemes are misrecognized within accent groups ## Challenges we ran into
- Poorly recorded audio datasets
- Many missing or underrepresented accents that we didn't have enough data to cover
- Trying to get the visualizations to match what we saw in our heads ## Accomplishments that we're proud of
- Data gathered from phoneme analysis
- Unique visualizations
What we learned
- How speech-to-text uses hidden markov models and neural networks to calculate the probability of phonemes and words to produce the best transcriptions
What's next for SpeechWright
We hope to be able to test much larger datasets and different speech-to-text models. With a larger, organized dataset, we could have access to more accurate results, as well as a diverse range of different language observations, and cooler visualizations :O.



Log in or sign up for Devpost to join the conversation.