-
-
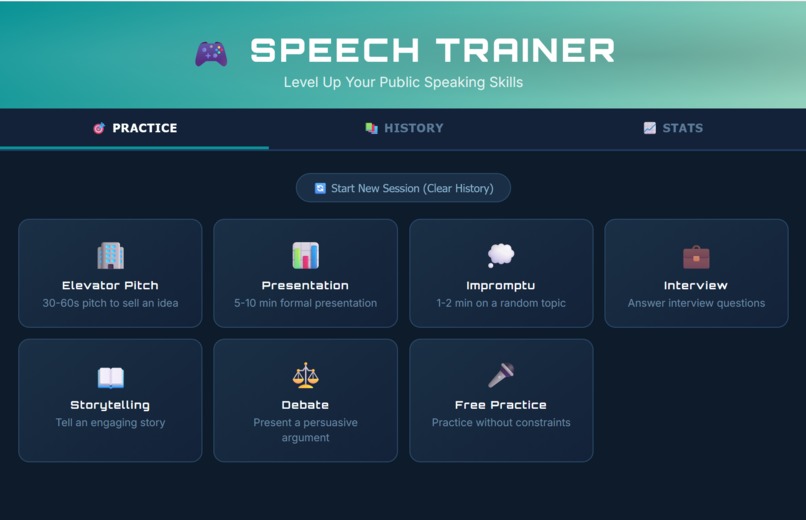
Main
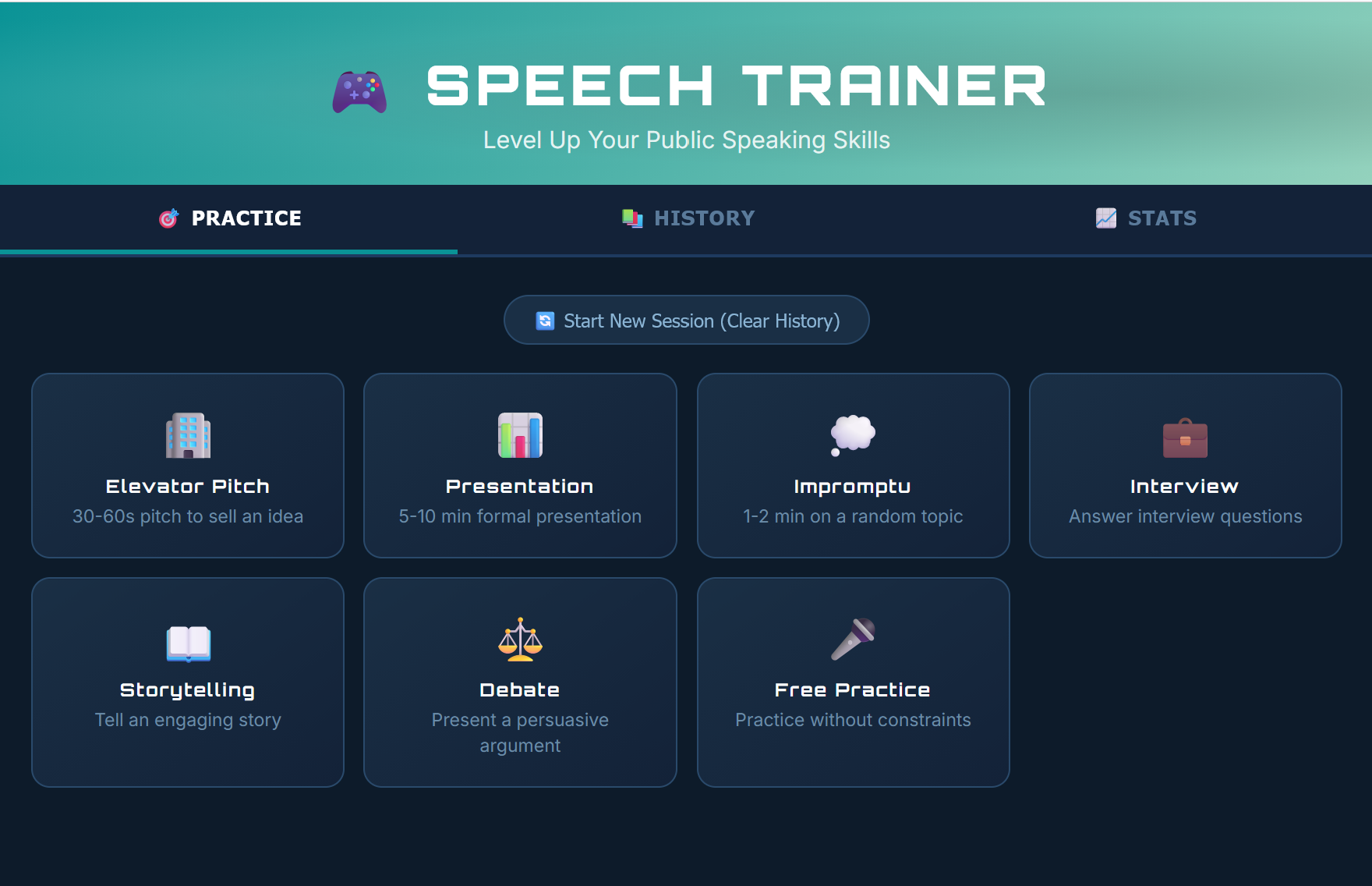
Inspiration
I was part of an impromptu speech team in high school. At the time, I had limited opportunities to receive feedback on my speaking, and many issues were hard to catch by listening to my own recordings. Some of these issues were word-level, such as mumbling and mispronunciations, while others were sentence-level habits, such as my tendency to start many sentences with “because.”
SpeechTrainer was inspired by this experience. It offers an AI-powered speech coach that analyzes recordings and identifies individual speaking patterns. I later expanded the idea to support different public speaking scenarios, such as elevator pitches, presentations, and storytelling.
What it does
SpeechTrainer allows users to select a public speaking mode and provides basic guidelines tailored to that mode. Users can record their speech with a real-time stopwatch.
After recording, SpeechTrainer analyzes the audio and presents feedback including speaking pace (words per minute), clarity score, fluency score, recommendations with priority rankings, and an interactive transcript. The transcript highlights mispronunciations, mumbled words, filler words, and grammatical issues with annotations.
Unlike many existing speech coaching tools, SpeechTrainer goes beyond word-level feedback such as detecting filler words and mispronunciations. It also provides sentence-level insights, including identifying repeated sentence structures, overly long sentences, and logical or grammatical issues.
The tool stores practice sessions locally and builds a history of recordings, allowing users to track and visualize their progress over time. Users can also replay their recordings to hear themselves.
How we built it
Speech analysis is performed using Gemini 3 API. We did prompt engineering to ensure reliable structured output and efficient LLM usage.
The front end is built with html, css, and JavaScript, featuring a gamified UI design. and the backend uses Flask to build a pipeline for audio-preprocessing and gemini API tool calls.
Challenges we ran into
We initially built the frontend using Streamlit, but when deploying, we realized that streamlit lacks support for required audio-processing libraries forced us to pivot to html and java script frontend.
Preprocessing audio into a format compatible with the Gemini model was surprisingly challenging, especially handling different recording formats and upload requirements.
Accomplishments that we're proud of
A polished, game-like UI that makes speech practice engaging.
A session-based recording history with progress tracking and visualization.
Mode-specific practice guidelines and feedback. For example, Impromptu mode provides a hidden prompt and starts a timed preparation period once the prompt is revealed.
What we learned
How to process and analyze audio using large language models.
End-to-end system design across frontend UI, backend logic, and API integration.
Prompt engineering for structured, machine-readable LLM outputs.
What's next for SpeechTrainer
SpeechTrainer has gone through 3 rounds of iterative user testing, and we plan to expand testing to a broader audience to gather more feedback.
We also aim to let users define personal speaking goals and receive more customized recommendations based on their long-term progress.

Log in or sign up for Devpost to join the conversation.