-

Final Project
-

Final Project 2
-

User Interface
-

Prototype Testing Apparatus with Display
-

Prototype Testing Apparatus with Display 2
-
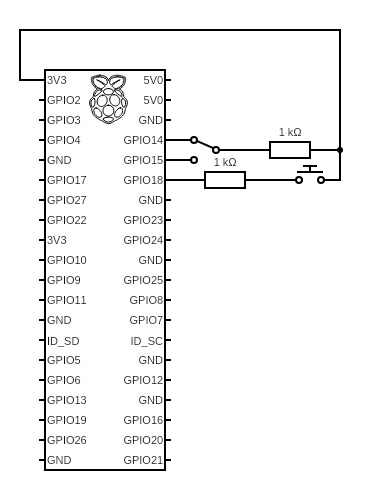
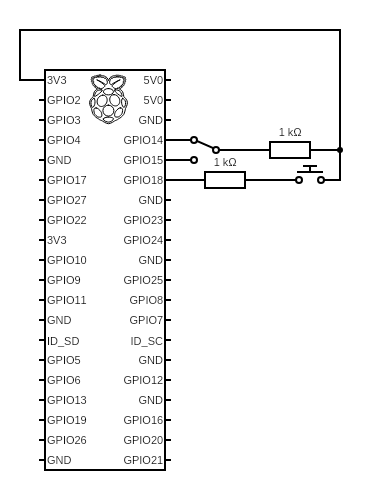
GPIO Circuit Diagram
-
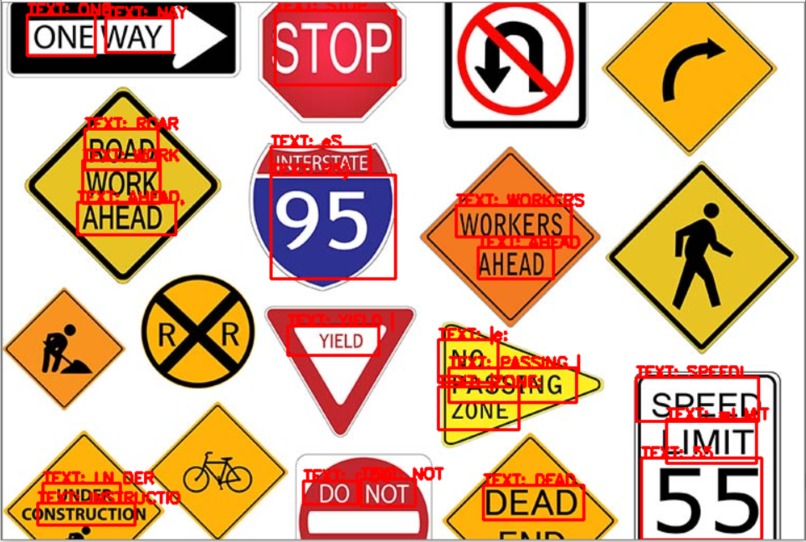
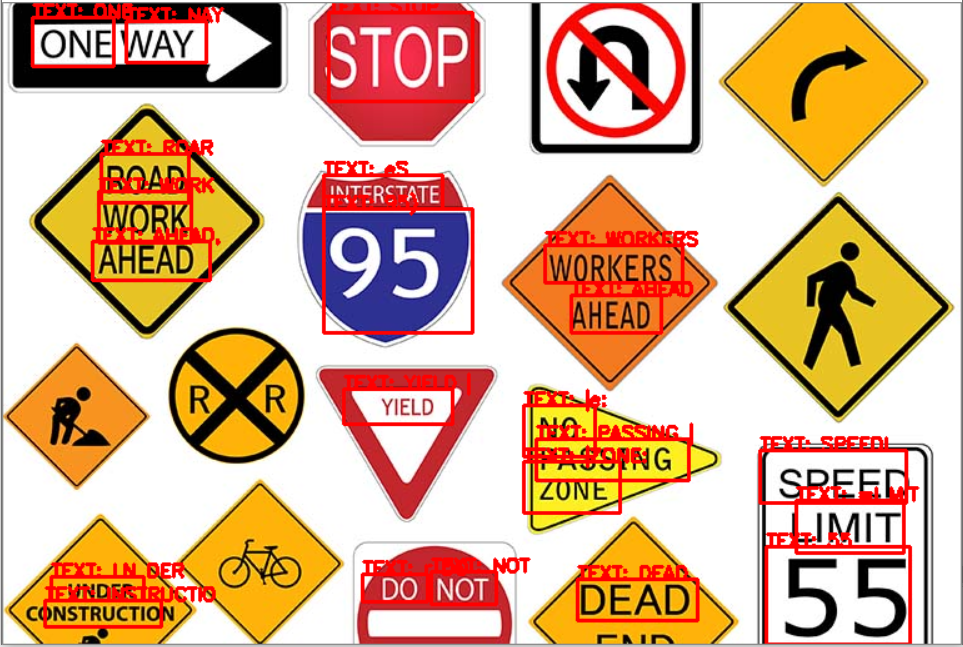
Example Processed Image





Inspiration
We wanted to utilize hardware in our hack and create a tangible product that could improve lives. Our goal was to create a offline low-cost wearable solution to empower the blind and visually impaired. Our device helps identify words in sight by converting text to spoken speech. We hope to provide a non-contact alternative to braille that can be accessed without an internet connection.
What it does
The Speech Lens has two settings: photo and video mode. In photo mode, the user presses a button to take a photo and text in view is spoken from left-to-right. In video mode, the camera feed is constantly processed and detected words are verbally communicated. These modes can be toggled using a switch. Speech Lens interprets these images using EAST, a deep neural network that identifies and draws regions of interest (ROI) around text. These regions are processed using Tesseract, an optical character recognition engine. Lastly, the pyttsx3 text-to-speech library is used to read the text aloud to the user.
How we built it
We used a Raspberry Pi 3 with Pi Camera v2.1 for initial prototyping and development, and the final prototype was created using a Raspberry Pi Zero W. The device is powered using a external 10000mAh battery bank and uses bluetooth for audio output. We used the Raspberry Pi GPIO pins to implement a button for photo capture and a slide switch to change operational modes (video vs camera mode). The main script was completely written in Python and the openCV/Tesseract/EAST open source code was found online.
Challenges we ran into
We ran into initial difficulties sourcing hardware and installing libraries properly. Getting functional code transferred and operational on the Raspberry Pi was a constant challenge.
Accomplishments that we're proud of
We are proud of completing a hardware hack despite resource constraints. We were able to utilize the components we had on hand and create a feasible product.
What we learned
- Independently researching/implementing new technologies
- Coding as a team
- Working under time pressure.
What's next for Speech Lens
- Improve framerate for video capture mode
- Improve ergonomics and usability
- Add object/facial detection
Built With
- east-model
- numpy
- opencv
- picamera
- python
- pyttsx3
- raspberry-pi
- tesseract



Log in or sign up for Devpost to join the conversation.