-
-

-
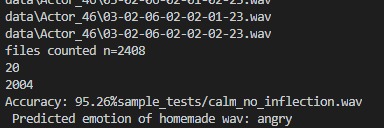
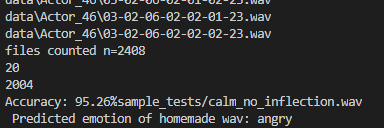
Picture showing accuracy of model and files used for continuous training
-
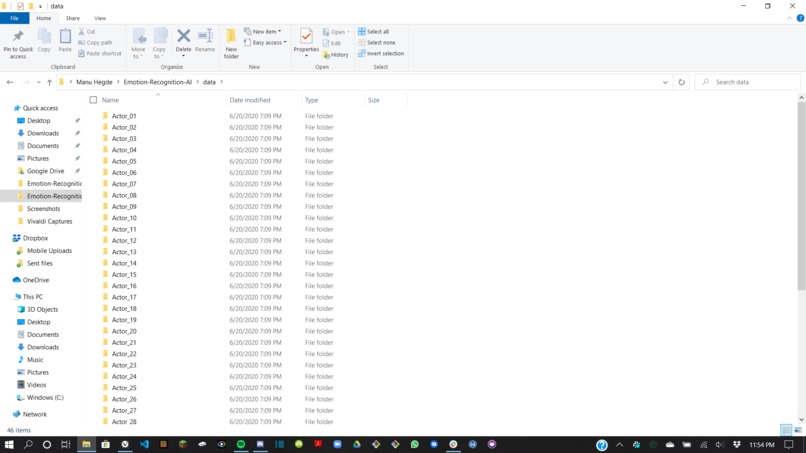
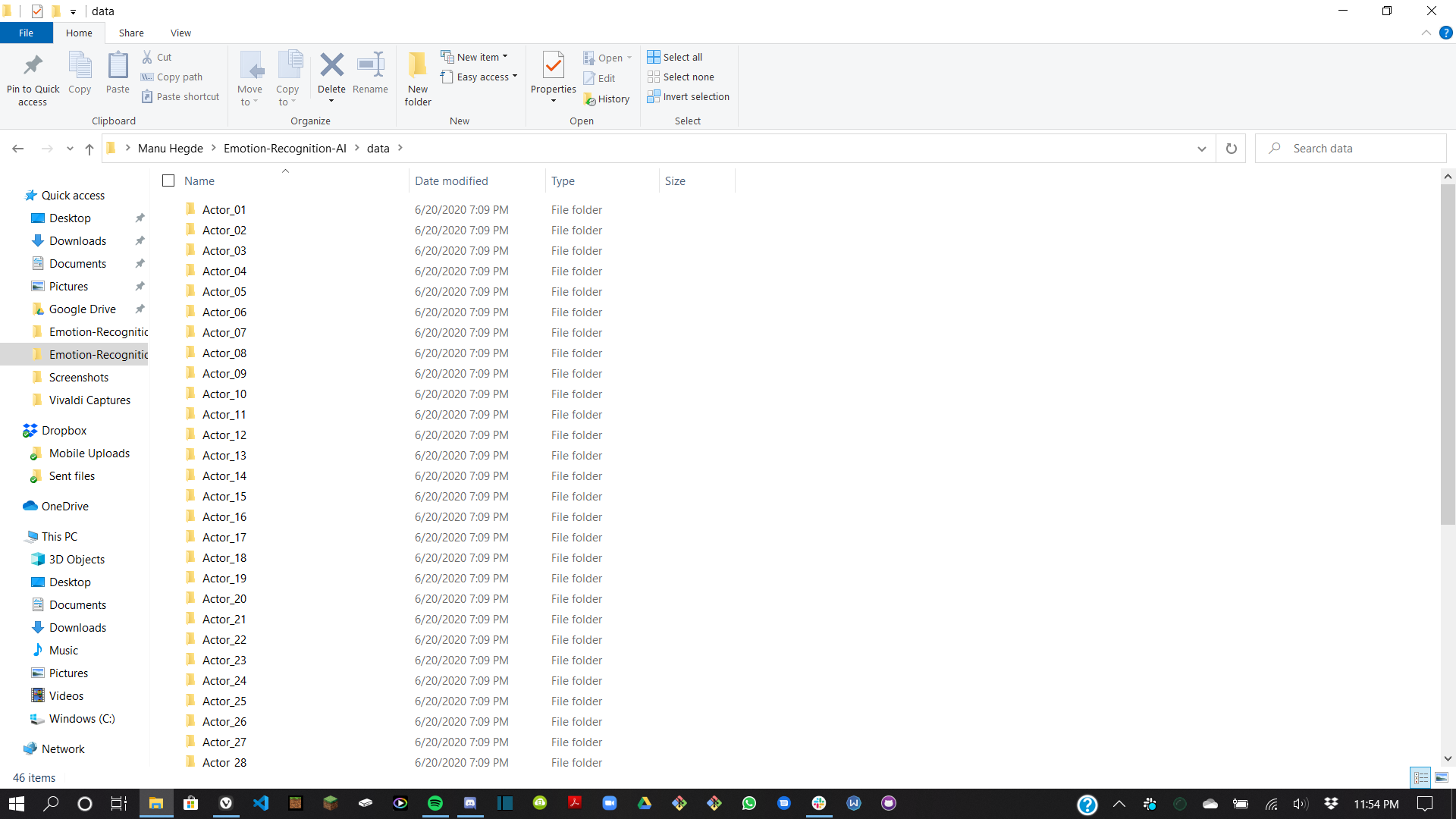
Dataset used to train model. Contains 48 actor folders with audio files within

Inspiration
We were inspired to create this project after looking into Artificial Intelligence (AI) and Machine Learning (ML), more specifically chatbots and virtual assistants. When looking into these concepts, many online resources cited virtual assistants such as Siri, Google Assistant, and Alexa as excellent examples of AI and ML. However, when diving into this field, we discovered that what many of these assistants and chatbots suffer from when communicating to users is emotion. These bots struggle with relating to the user and understanding what they’re feeling, which leads to less effective bots and worse user experiences. Furthermore, we realized that identifying emotions are extremely important during human-to-human interactions, as emotions can help determine the urgency of situations for crisis and hotline services, allowing for more effective organization of clients. By creating software that analyzes audio input and determines the emotion exhibited with ML, improves over time with more user inputs, and can be applied and overlaid to many applications, we can allow virtual chatbots and assistants to be more effective and empathetic towards customers, as well as allow human-to-human interactions to be more succinct and productive. With virtual assistants becoming essential parts of our lives in the near future, this technology is more needed than ever.
What it does
Emotify allows you to record yourself saying whatever you want, and then run this audio through the feedforward artificial neural network (FANN) to see what emotion is detected. This FANN returns the emotion detected, and the user can submit feedback on whether the emotion returned was correct or not. Although it is hosted on a webpage right now, this FANN and model can be implemented with any software that requires the determination of emotions, with examples mentioned before such as chatbots, virtual assistants, and human-to-human interactions online. The final FANN and model that was trained and integrated into this application had a 95.26% accuracy.
How we built it
First, we developed the machine learning and neural network model using librosa, soundfile, and sklearn. Librosa and soundfile were the two python libraries used for analyzing our audio samples. Soundfile was used to interact with, read, and write to these files, and librosa was used for audio analysis. We used the Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) dataset, which contains over 2500 files by 24 actors and has been rated by 247 individuals 10 times on emotional validity, intensity, and genuineness. Looking through this dataset, we used librosa to look for three key values in each file: mfcc, chroma, and mel. Mfcc is the Mel Frequency Cepstral Coefficient and relates the power spectrum of the sound, chroma relates to the 12 pitch classes, and mel is the Mel Spectrogram Frequency. Using this data, we used librosa to find what we called features in each sound and then associated these features to the corresponding emotion. These features were essentially patterns found in the values mentioned above, and could be compared to input audio from the user to determine which emotion is most closely related.
The neural network model was developed using sklearn, and we used an MLPClassifier, or Multil-ayer Perception classifier. We trained this model with our parsed audio files, with the x-values representing the features found, with these features being the computed values mentioned above, and the y-values representing the associated emotion. We continuously used this data to train the model, and after tweaking with the batch size, we were able to create a model with 95.26% accuracy.
The rest of the project was relatively simple. To host this AI, we decided to make a simple web app using Flask and HTML/JavaScript. We built the system for the user to record themselves and be able to interact with recording, and then linked the front-end’s data to be fed through the neural network model. The result determined was shown to the user, and their feedback would be used to train the model to improve for future users.
Challenges we ran into
All the challenges we ran into were relating to one thing: the audio. Due to the way librosa is built, the audio given has to be consistent, and there are certain requirements for the parsing and extracting of features to work. One such issue was between monophonic (mono) and stereophonic (stereo) sound. To be able to compute the values of mfcc, chroma, and mel, the audio passed needed to be mono. However, depending on the input device used by the user, the audio could be stereo, and thus not be analyzed. However, we were able to find a solution provided by the librosa library itself and were able to convert between the two versions throughout the extraction process.
The second challenge was much vaguer and was never fully solved. This challenge was with audio quality. This was an issue we had been dealing with throughout the hackathon, and we were able to find a post where the librosa developers admitted there was no solution possible. Essentially, the way librosa is built, audio quality is very important. As soon as the quality goes down, so does librosa’s ability to find and calculate the features. This means that the model will be very accurate for our dataset (95.26%) due to its high quality, but do much worse due to lower quality sent from a user. However, there is no way to reliably increase the quality of the audio given, resulting in this challenge.
We had some challenges with Google Cloud, in terms of setting up the API and authorization, however, those were quickly and easily resolved.
Accomplishments that we are proud of
We are proud of how we were able to create a neural network model, as none of us had experience with artificial intelligence or machine learning beforehand. We were especially happy with the accuracy results, as seeing the model take in an audio file and output the correct emotion was very rewarding. We are also proud of learning about audio processing and analysis with librosa, as once again this was new to use but very rewarding once the computations and parsing were successful. Overall, we are proud of creating an applicable machine learning project.
What we learned
As mentioned before, we had no experience with this field of work before this hackathon, so we learned lots about artificial intelligence, machine learning, neural networks, and training these models. We learned a lot about these systems and how they are able to form connections, and audio processing to get to these connections was a big concept to wrap our heads around. However, the thing we learned that was most important is collaborating remotely. We have done hackathons before, however, we have always worked with others in the same physical space. Working remotely with others required lots of communication, organization, time management, and effort overall. Being able to do this while learning new concepts together will make us regard this hackathon as successful, regardless of the prize results.
What's next for Emotify
In the future, we would definitely be interested in expanding and trying to make this a professional product. Since we are analyzing audio clips, accessibility in terms of language should not be an issue. To expand, we would like to move to different platforms. Right now, it is simply a web application that returns the determined emotion, but we would want to make a full-fledged chatbot with relevant responses depending on the emotion of the user. We would want to polish up the code, and ensure it can be easily integrated with other programs of assistants, meaning we would want to develop an API with documentation. So not only would we want our own bot to use emotion recognition, but as mentioned before, our overall goal is to allow all other bots, virtual assistants, and other programs and services to overlay this model on top of their product. Overall, the future would mean expansion, in terms of applicability towards other platforms, and accessibility for other programs to implement this model.
Built With
- bootstrap
- css3
- flask
- google-cloud
- html5
- javascript
- librosa
- python
- recorder.js
- sklearn
- soundfile

Log in or sign up for Devpost to join the conversation.