-
-
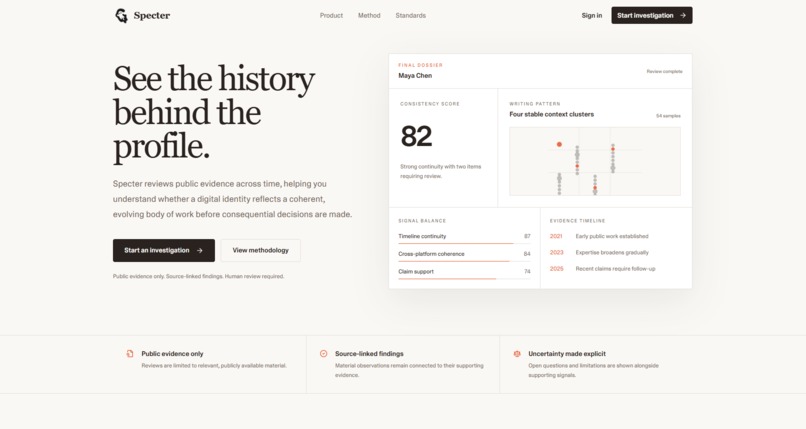
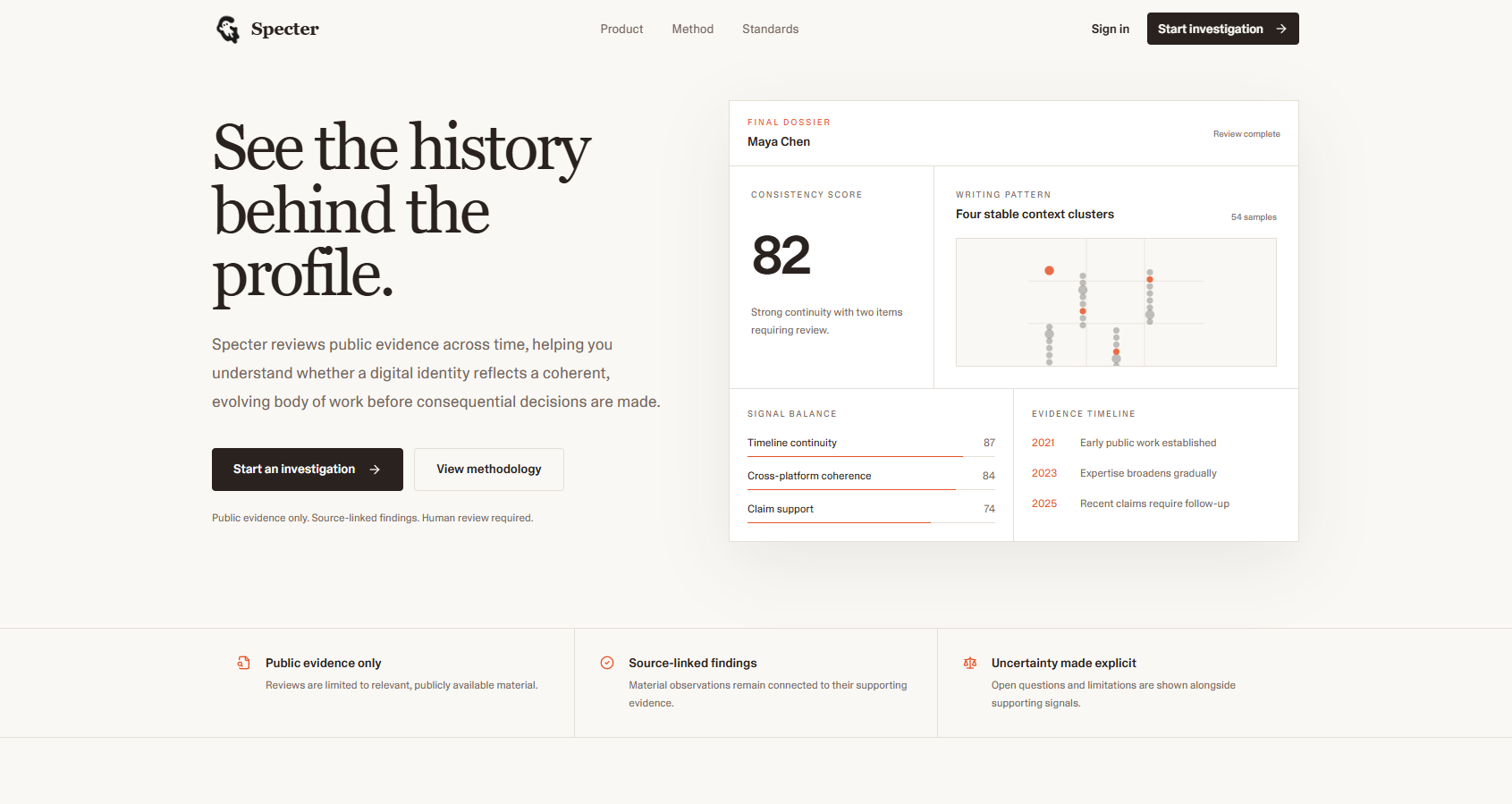
Landing Page
-
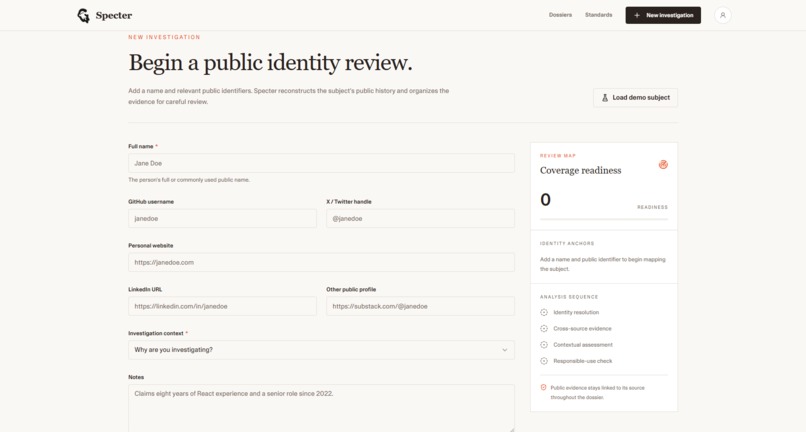
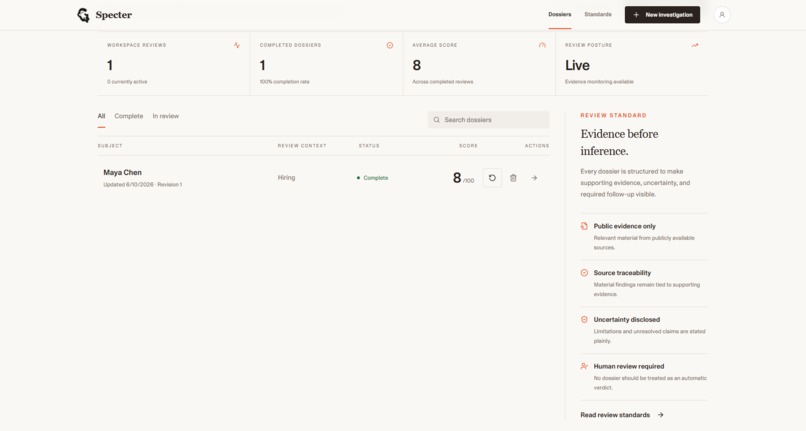
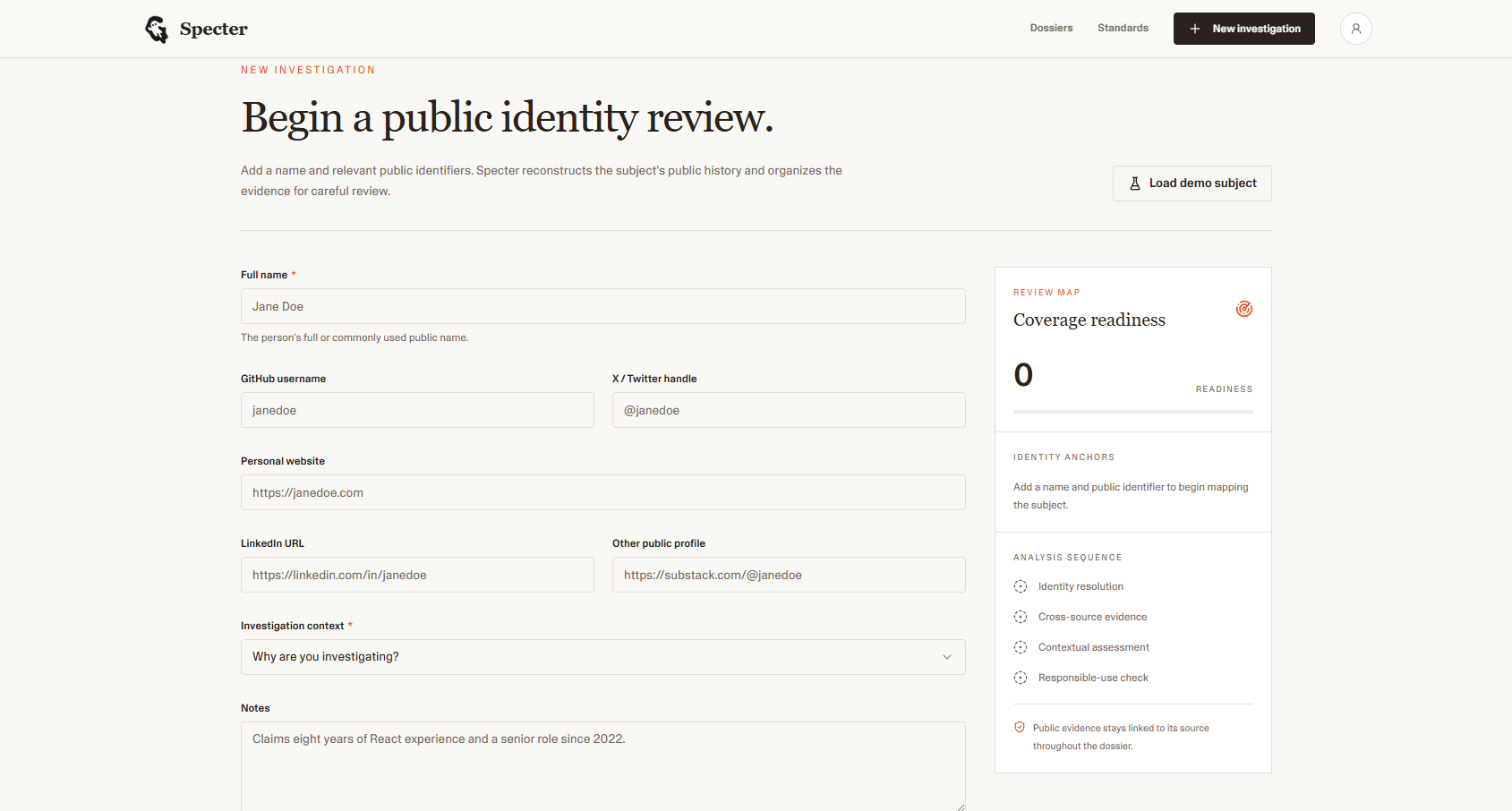
Investigation Page
-
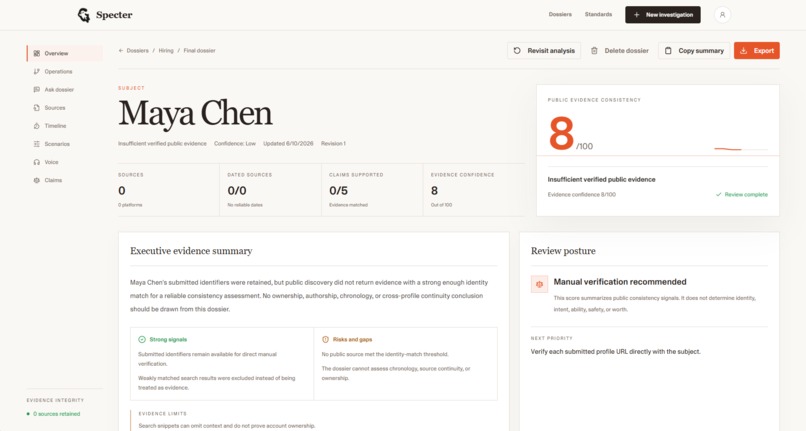
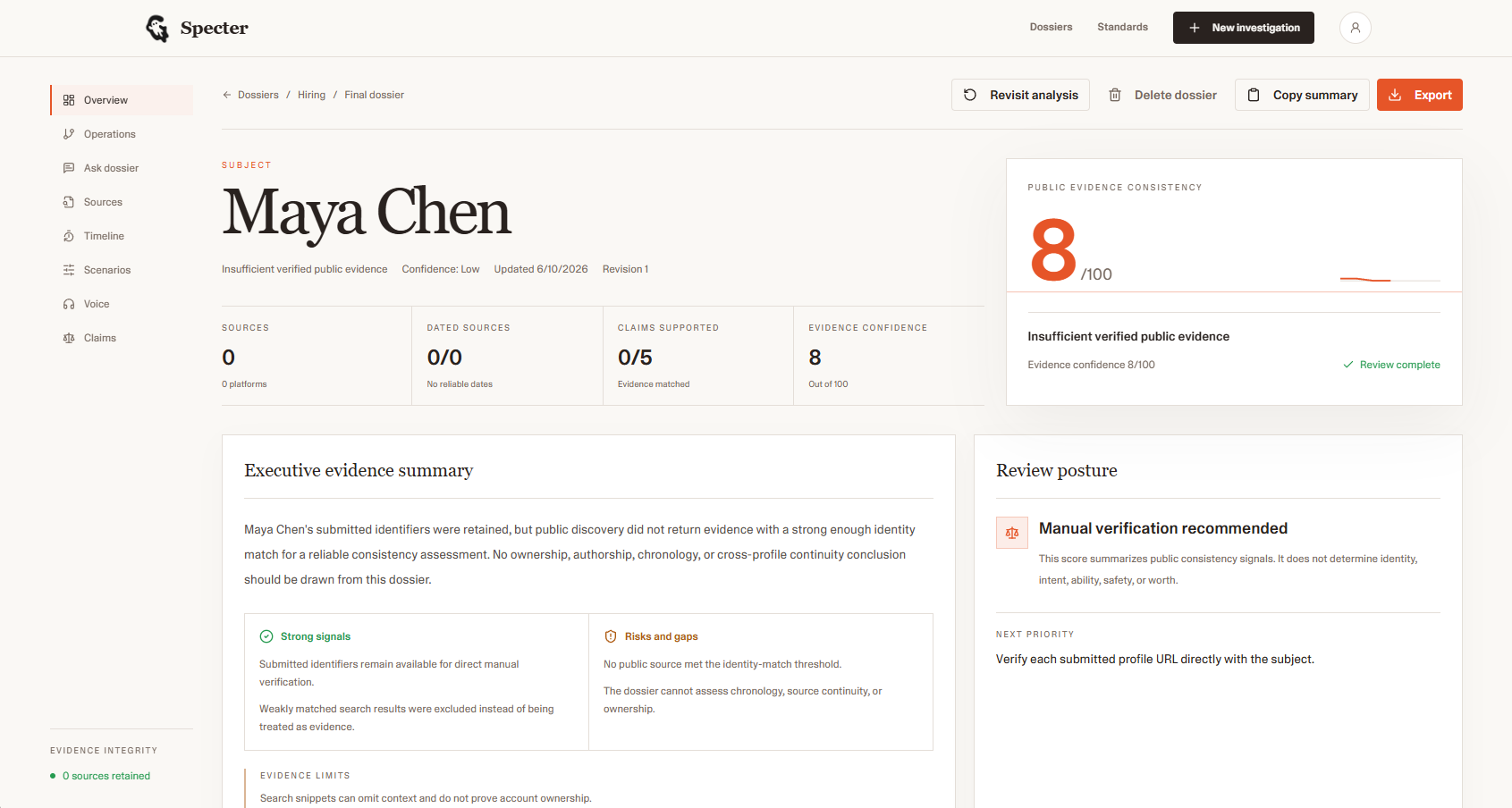
Detailed Analysis
-
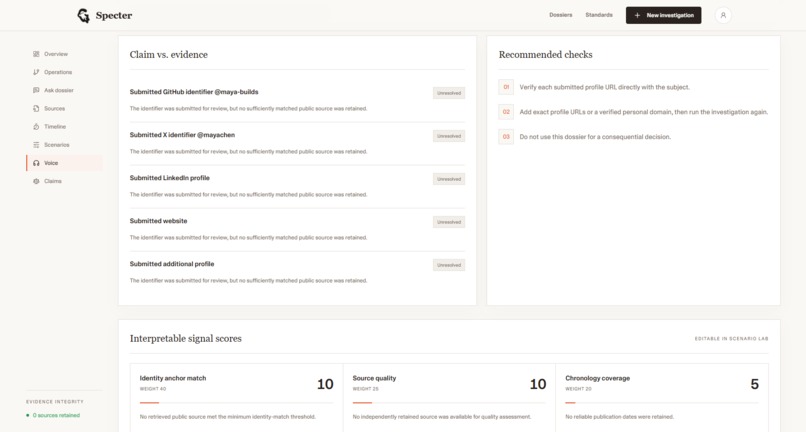
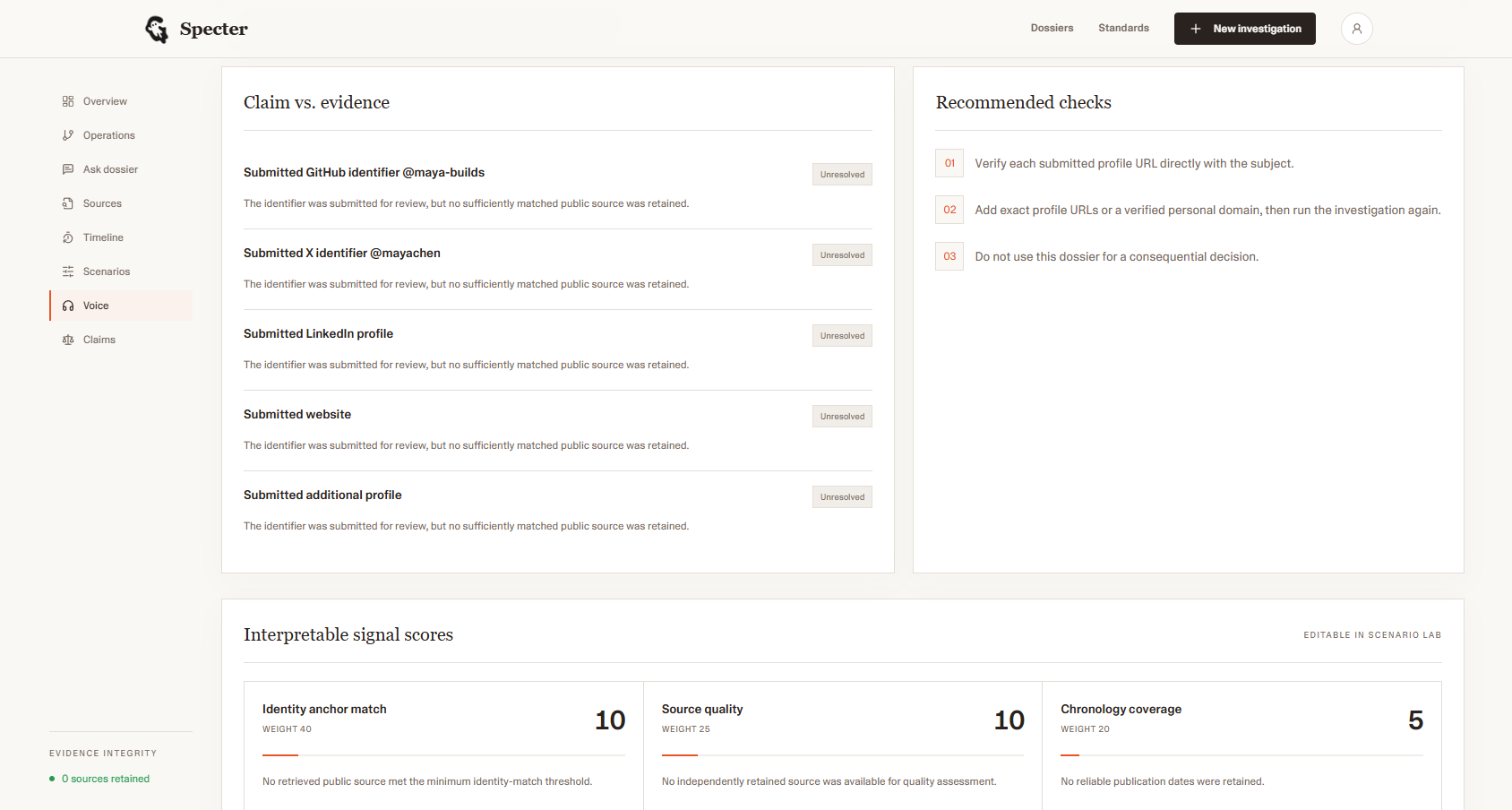
Claims V/S Evidence
-
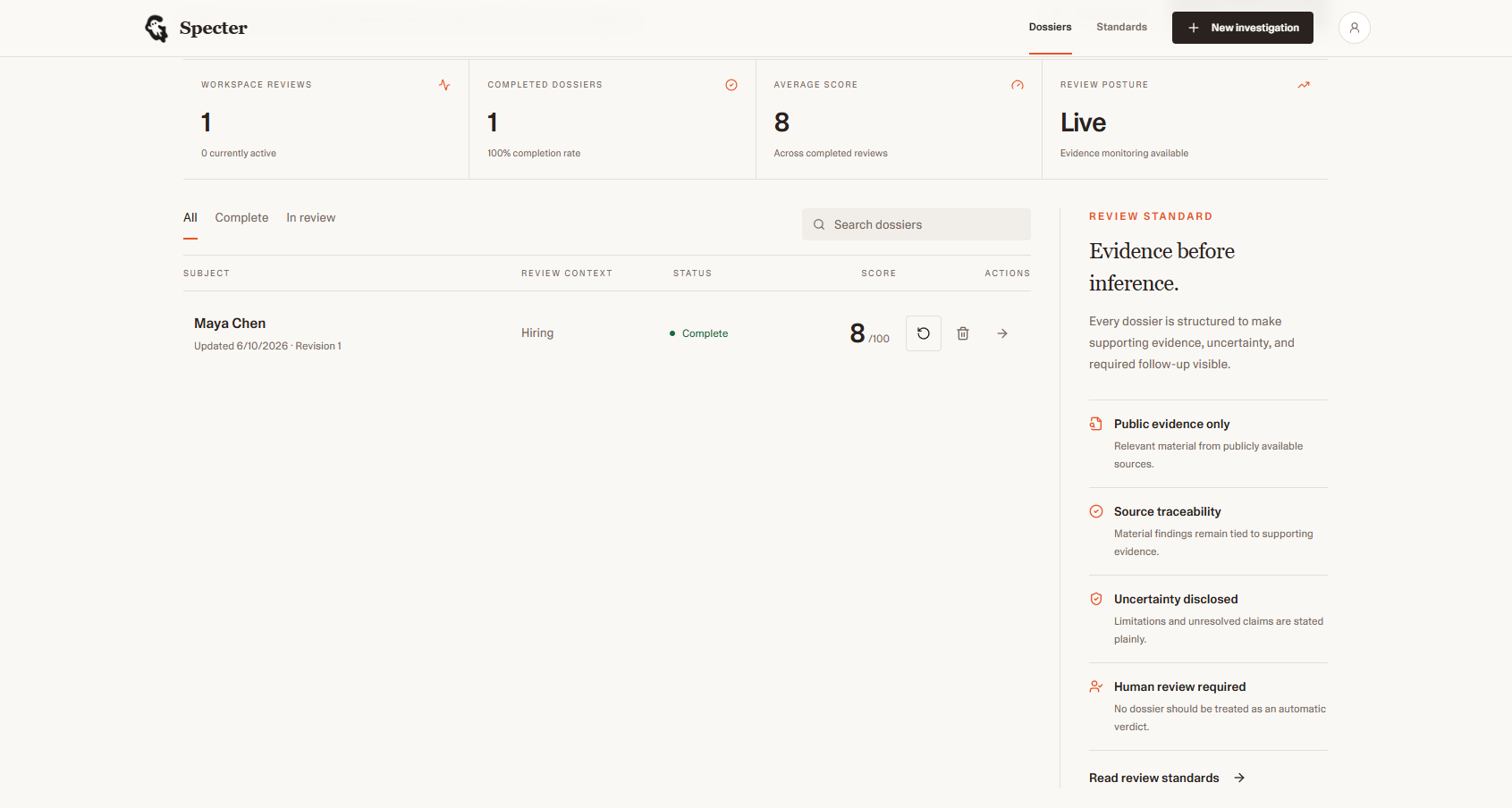
All your Investigation
Specter - Public Identity Intelligence for Reviewers Who Need Evidence, Not Guesses
What Inspired This
The problem that started everything: you're about to hire someone, back a founder, or publish a story about a public figure. You search their name, find a few links, and make a call. That's it. There's no systematic way to collect, score, and revisit the public record, just vibes and whatever shows up on the first page of search results.
Specter exists to replace that process with something reviewable, evidence-backed, and honest about what it doesn't know.
What Specter Does
Specter turns a name, a handle, a GitHub username, and a LinkedIn URL into a *versioned evidence dossier,* a structured report that:
- collects public sources across GitHub, X, LinkedIn, and personal websites
- scores the consistency of that footprint against multiple deterministic signals
- surfaces source-linked claims, contradictions, and open questions
- supports revisits with full revision history so you can see how the public record changes over time
- lets you ask the dossier questions and get evidence-based answers
- briefs you in a private voice conversation with a configured AI investigator
The score isn't an AI guess. It's a weighted average across seven deterministic signals: timeline depth, growth continuity, writing evolution, expertise match, activity burst anomaly, cross-platform coherence, and fingerprint diversity. Evidence drives the number, not a prompt.
How It Was Built
SpacetimeDB as the Operating Core
The most unconventional decision in the architecture was making SpacetimeDB serve as everything except the frontend. There is no REST API layer, no Express server, no separate secrets manager. SpacetimeDB holds the investigation state in durable tables, owns every external provider call, keeps all API keys in a private provider_config table that only the publishing identity can write to, and handles rollback when discovery fails.
The frontend speaks directly to SpacetimeDB over a WebSocket. When the browser calls runInvestigation, the SpacetimeDB module fires Nimble queries, scores the results, issues a Tower receipt, and returns a complete dossier JSON, all without a single API key ever touching browser memory.
This produced a genuinely different security boundary: the only environment variables prefixed with VITE_ are the SpacetimeDB URI and database name. Nimble, RunPod, Tower, and ElevenLabs keys exist only as rows in a database table on the server side. A compromised browser build reveals nothing about any provider.
Nimble for Live Web Discovery
Nimble powers the actual evidence collection step. For each investigation, SpacetimeDB fires up to three targeted queries against sdk.nimbleway.com/v1/search using identity anchors; the user supplies the subject's name, GitHub username, X handle, and website domain. Results come back as structured sources with URLs, titles, and snippets.
The interesting experiment here was building an identity-anchor scoring system on top of the raw Nimble results. A result's URL, title, and snippet are tested against every anchor. If the GitHub handle appears in the URL, the username appears in the snippet, the domain matches the known website, and points accumulate. Sources below a minimum identity match score of 45 are discarded before they ever reach the dossier. This meant Nimble's results went from "broadly relevant web content" to "traceable evidence specifically about this person." The difference in dossier quality was immediately visible.
I also experimented with query targeting: instead of sending one big query for the subject's full name, Specter issues separate queries, one for technical footprint (name + GitHub), one for professional record (name + LinkedIn), and one for writing and content, and deduplicates by URL before scoring. More focused queries, sharper results.
RunPod for Evidence-Bounded Reasoning
RunPod provides the inference layer for the "Ask this dossier" and voice Q&A features. When a reviewer asks "What are the main evidence gaps?" or "Which claims need the most verification?", Specter calls RunPod's serverless endpoint with the dossier JSON as a bounded context.
The configuration: primary model qwen3-32b-awq, fallback model granite-4-0-h-small. Both are passed via the private SpacetimeDB config table. The fallback fires automatically if the primary is unavailable or returns a malformed response.
The important constraint I held throughout: RunPod never touches the scoring pipeline. The consistency score, all seven signal scores, and the evidence classification come from deterministic code in the SpacetimeDB module. RunPod is only invoked when a human asks a natural-language question and an evidence-grounded answer is needed. This keeps the core dossier reproducible and auditable regardless of model availability.
Tower for Audit Receipts
Tower (api.tower.dev) receives a workflow receipt after each completed investigation. The payload, built in integrations/tower/investigation_complete.py, carries the investigation ID, subject name, context type, source count, and consistency score with a UTC timestamp.
The way I wired this in was deliberate: Tower gets called after the dossier commits, but the finishVoiceSession reducer also logs to the operation trail. If Tower is unreachable or returns an error, the investigation does not fail; it just records an audit_skipped operation status. The philosophy was: Tower proves the workflow ran, but the dossier doesn't need Tower's blessing to exist.
I also wrote the Towerfile to declare the full investigation workflow intake, discovery, scoring, and audit receipt so Tower can represent the full operational shape of the system, not just a ping at the end.
ElevenLabs for the Voice Investigator
The voice integration was the most technically layered piece. Here's how it works:
- The browser calls a SpacetimeDB procedure to get a short-lived conversation token. The ElevenLabs API key never leaves the server.
- The browser opens a WebRTC session to ElevenLabs using only that token.
- The moment the connection is established, Specter fires
sendContextualUpdatewith the full dossier serialized as JSON subject name, consistency score, signals, claims, sources, concerns, and recommendations. - The agent configured in the ElevenLabs dashboard (named "Spectre Dossier Investigator") uses a custom system prompt that enforces evidence-grounded answers: cite source titles, disclose when the record is incomplete, never declare the subject authentic or deceptive as a verdict, and separate observed facts from inference.
The fallback when ElevenLabs is not configured (or in demo mode): Web Speech Synthesis. Specter selects a soft English female voice by scanning available voices for names like "Samantha", "Aria", or "Victoria", then uses it to read the dossier briefing at 0.92x rate. It's not a replacement for the real thing, but it meant the voice section worked end-to-end from day one without waiting on token setup.
Name.com, The Domain
The production deployment is based on ghost.reviews, a domain registered through Name.com. The name itself is part of the product story. A ghost review is what you get when there's no public record to validate a claim, and Specter's job is to find out whether the ghost is real. DNS records on Name.com point the domain to Vercel, where the SPA is deployed.
The Demo Mode Experiment
One of the stranger things I built was a fully functional offline demo mode that requires zero API keys. When VITE_DEMO_MODE=true, every investigation goes through investigationStore.ts, a deterministic local engine that seeds evidence sources, signals, claims, embeddings, and timeline events from the subject's name and anchors using a simple hash function. The investigation stages animate in real time using a timer, the writing fingerprint scatter plot renders with seeded cluster coordinates, the scenario score lab lets you drag weights and watch the score change, and the timeline playback steps through events.
This turned out to be critical for the hackathon: judges and reviewers can see the full product in every section, every interaction, without a single environment variable configured. The live mode and demo mode share identical UI components and types; only the data source differs.
Challenges
The SpacetimeDB HTTP gateway was the hardest boundary to get right. External HTTP calls from within a WASM module don't behave the way you'd expect from a Node.js server. The Nimble request format, header requirements, and response shape all had to be handled inside a Rust module with no debugger. Testing the provider pipeline meant repeatedly publishing the module and inspecting logs, not just printing to the console.
The rollback logic for revisits took longer than expected. The invariant I wanted: a revisit that fails discovery must restore the previous complete dossier and not leave the investigation in a permanently broken state. Getting the commit/rollback sequence right captures the previous state, marks running, attempts discovery, on success atomically replaces, and on failure restores the required careful ordering inside a single reducer.
ElevenLabs convai_write permission was a surprise. The signed-token endpoint for starting a conversation requires Conversational AI write permissions on the API key, even when the agent was configured entirely through the dashboard. This isn't documented prominently and costs real debugging time.
What I Learned
Building this pushed me to think seriously about where trust boundaries actually live in a product. The temptation is always to put everything in environment variables and call it "server-side." But when SpacetimeDB is both the database and the API server and the secrets store, you get a genuinely different model: the browser can be fully audited and contains nothing sensitive, and all provider integrations are measurable, logged operations that leave a trail.
The other thing: deterministic scoring holds up surprisingly well. The seven signals I defined, timeline depth, growth continuity, writing evolution, expertise match, burst anomaly, cross-platform coherence, and fingerprint diversity, cover the failure modes I actually care about (sudden credential inflation, identity recycling, fabricated publication histories) without requiring a model to hallucinate a verdict. RunPod handles the conversational layer; the score stands on its own.

Log in or sign up for Devpost to join the conversation.