-
-
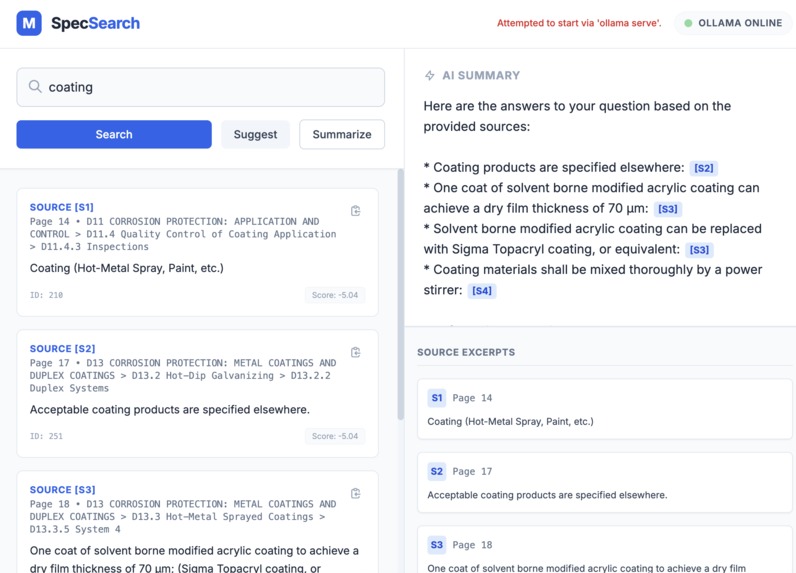
example key word search 1
-
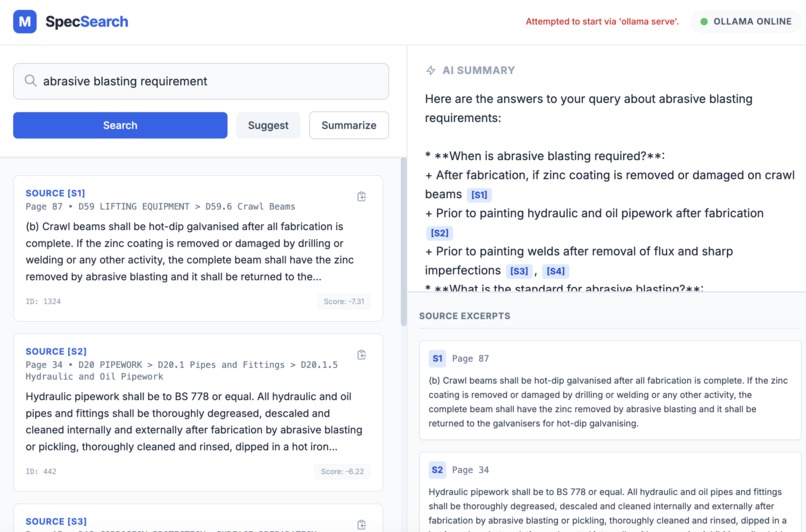
example key word search 2
-
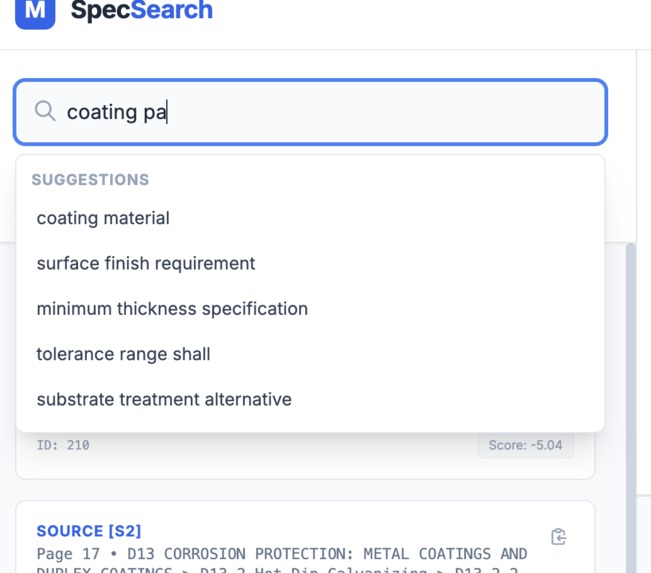
LLM suggested query
-

link to Original Document Entry

About the Project
Inspiration
This project was inspired by a very practical problem: searching large, confidential technical documents.
Engineering standards and specifications often span hundreds or thousands of pages, and finding the exact clause that answers a question can be slow, error-prone, and frustrating. Existing “chat with your document” tools are usually cloud-based, opaque, and unsafe for sensitive material. I wanted a system that works entirely locally, prioritizes traceability over fluency, and behaves more like an internal engineering tool than a chatbot.
What I Built
I built a fully on-prem Retrieval-Augmented Generation (RAG) system for mechanical engineering specifications.
At a high level, the system:
- Parses structured PDFs into hierarchical sections and paragraph-level clauses
- Indexes the content using hybrid retrieval:
- BM25 keyword search via SQLite FTS5
- Semantic vector search using sentence embeddings
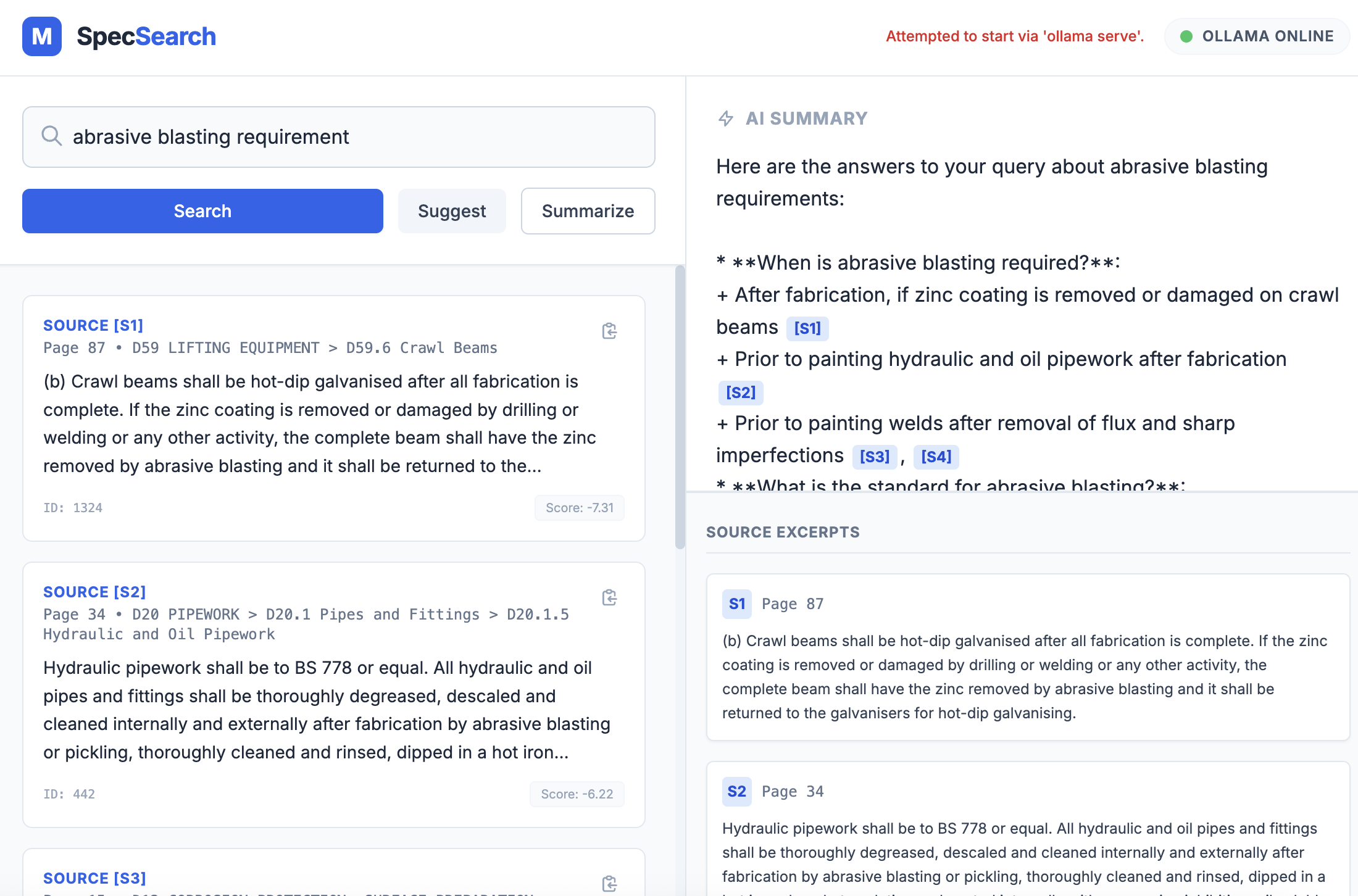
- Returns exact source paragraphs with section paths and page numbers
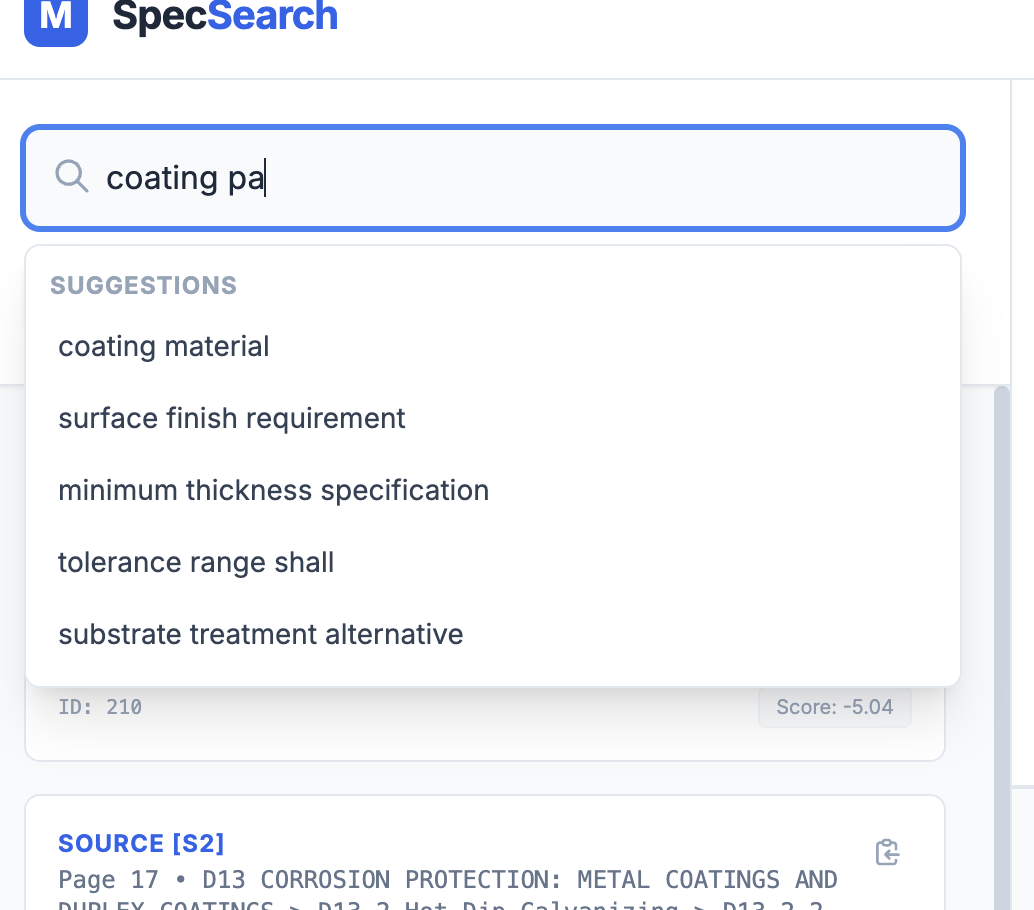
- Optionally uses a local LLM (Llama 3 via Ollama) to:
- Suggest improved search queries
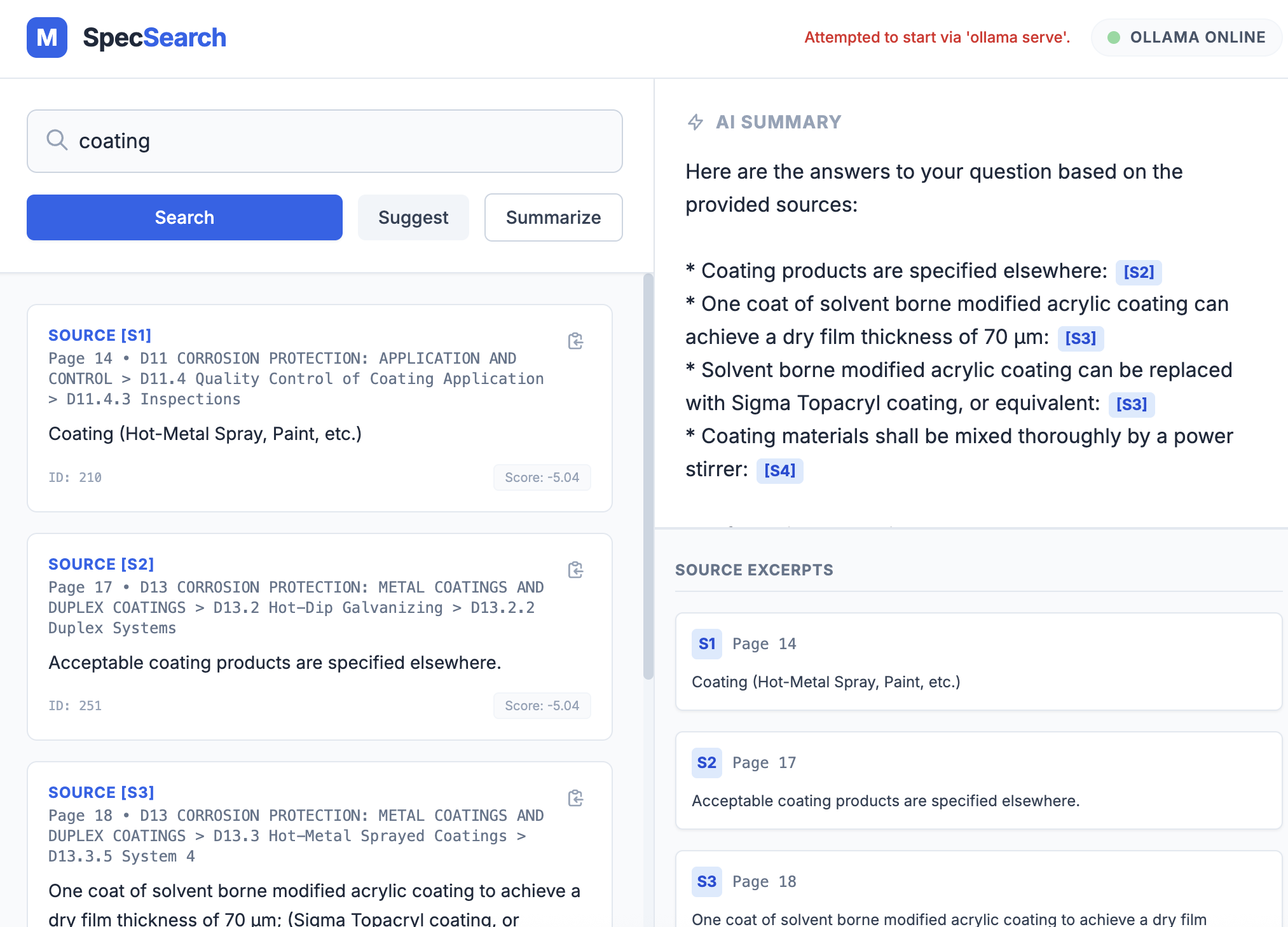
- Generate strictly grounded summaries with explicit citations
The frontend exposes this through a simple search interface with buttons for Search, Suggest, and Summary, plus direct links to open the source PDF at the correct page.
What I Learned
This project taught me several important lessons:
- Parsing matters more than models: Retrieval quality depended far more on correct paragraph reconstruction, section hierarchy, and noise removal than on LLM choice.
- Vector search alone is not enough for standards and specifications; exact terms, numbering, and “shall” clauses require traditional keyword search.
- Grounding and citations are critical for trust. A system that can say “not found in the document” is more valuable than one that always answers.
- Running LLMs locally introduces operational concerns (process lifecycle, availability, graceful degradation) that cloud APIs hide.
- Simple, explicit system design often beats complex “agentic” abstractions for reliability and auditability.
Challenges
Some of the main challenges included:
- PDF structure variability: Headings, wrapped lines, headers, and footers required custom heuristics to avoid polluting the text.
- FTS5 integration details: Correctly joining full-text search results back to the original rows via
rowidwas subtle but essential. - Preventing hallucinations: The LLM had to be constrained to only summarize retrieved content and fail safely when evidence was missing.
- Local LLM availability: The system needed to function even when the LLM was offline, requiring clear fallback paths.
- End-to-end integration: Connecting parsing, indexing, retrieval, LLM inference, API endpoints, and frontend interactions into a coherent, demoable system. the frontend was build with Gemini3 API in gemini studio
Outcome
The result is a compact but realistic internal tool: a private, auditable search engine for technical standards.
It demonstrates how modern retrieval and language models can be applied responsibly in engineering and compliance contexts—without sacrificing security, correctness, or traceability.
Built With
- fastapi
- fts
- github
- next.js
- ollama
- python
- react
- scikit-learn
- sentencetransformer
- sqlite
- uvicorn

Log in or sign up for Devpost to join the conversation.