-
-
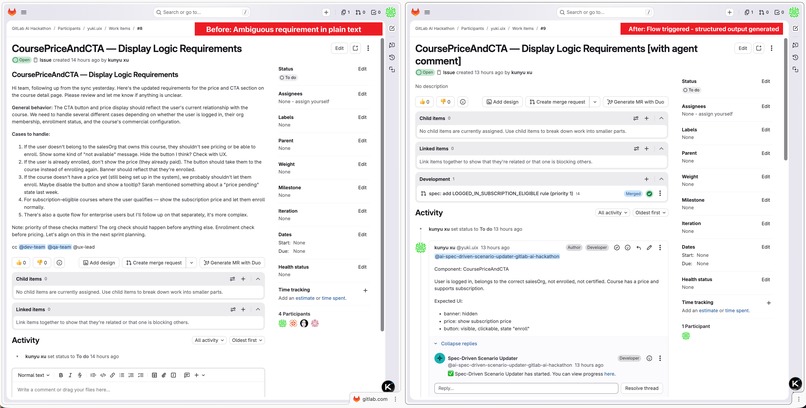
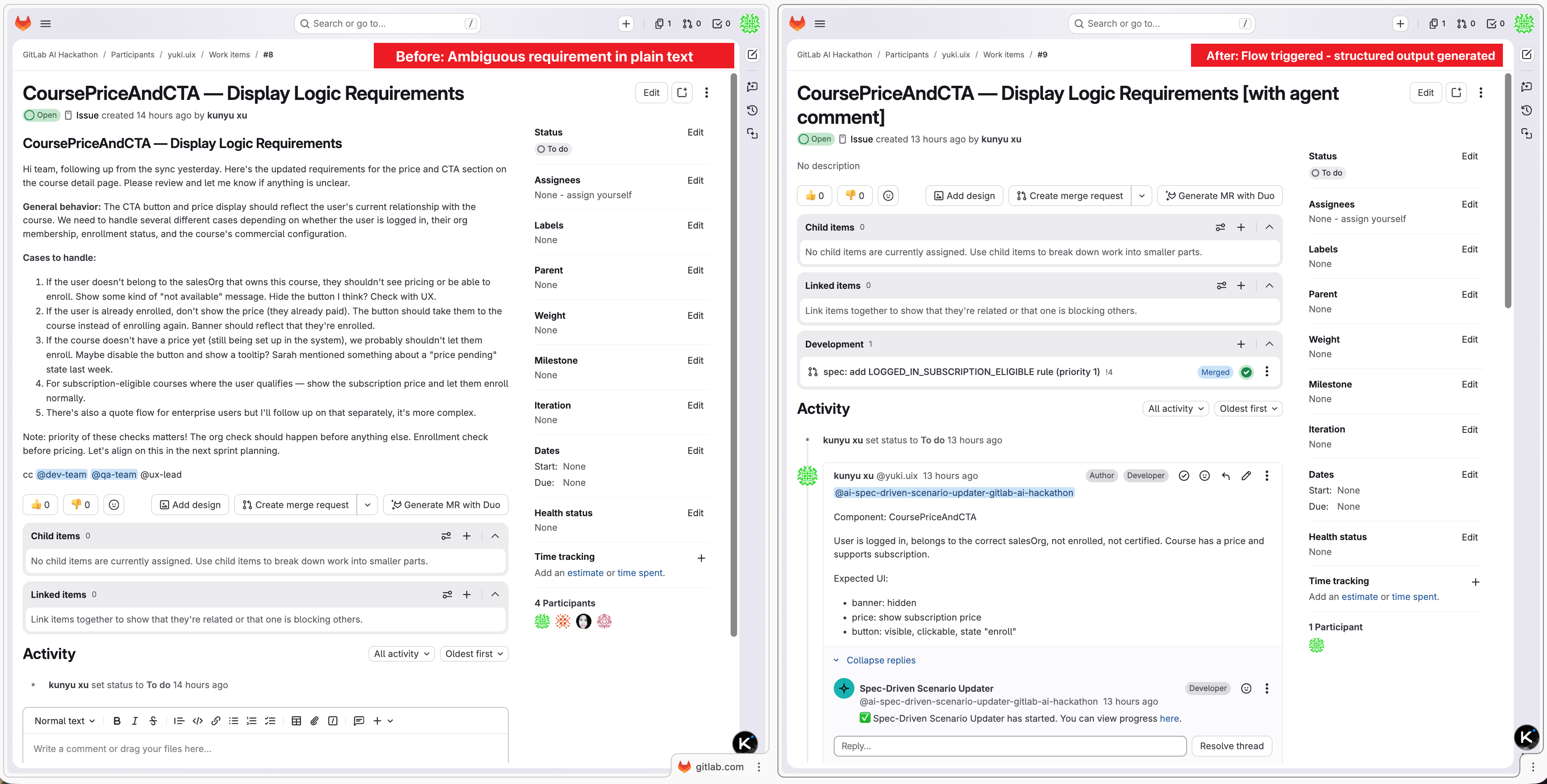
Before: scattered requirements. After: flow triggered, structured output generated in under 2 minutes.
-
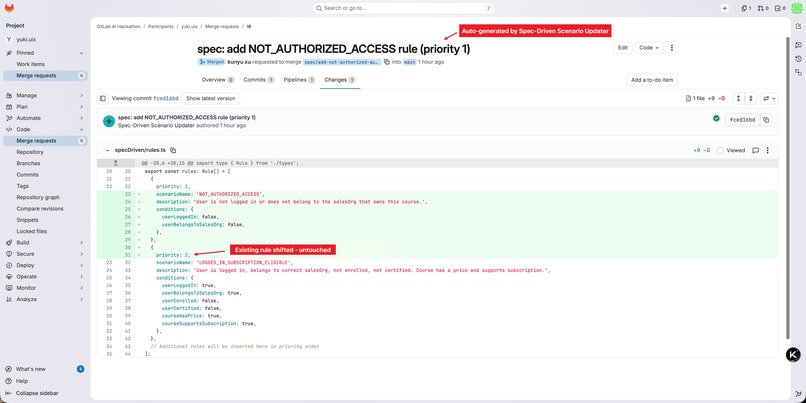
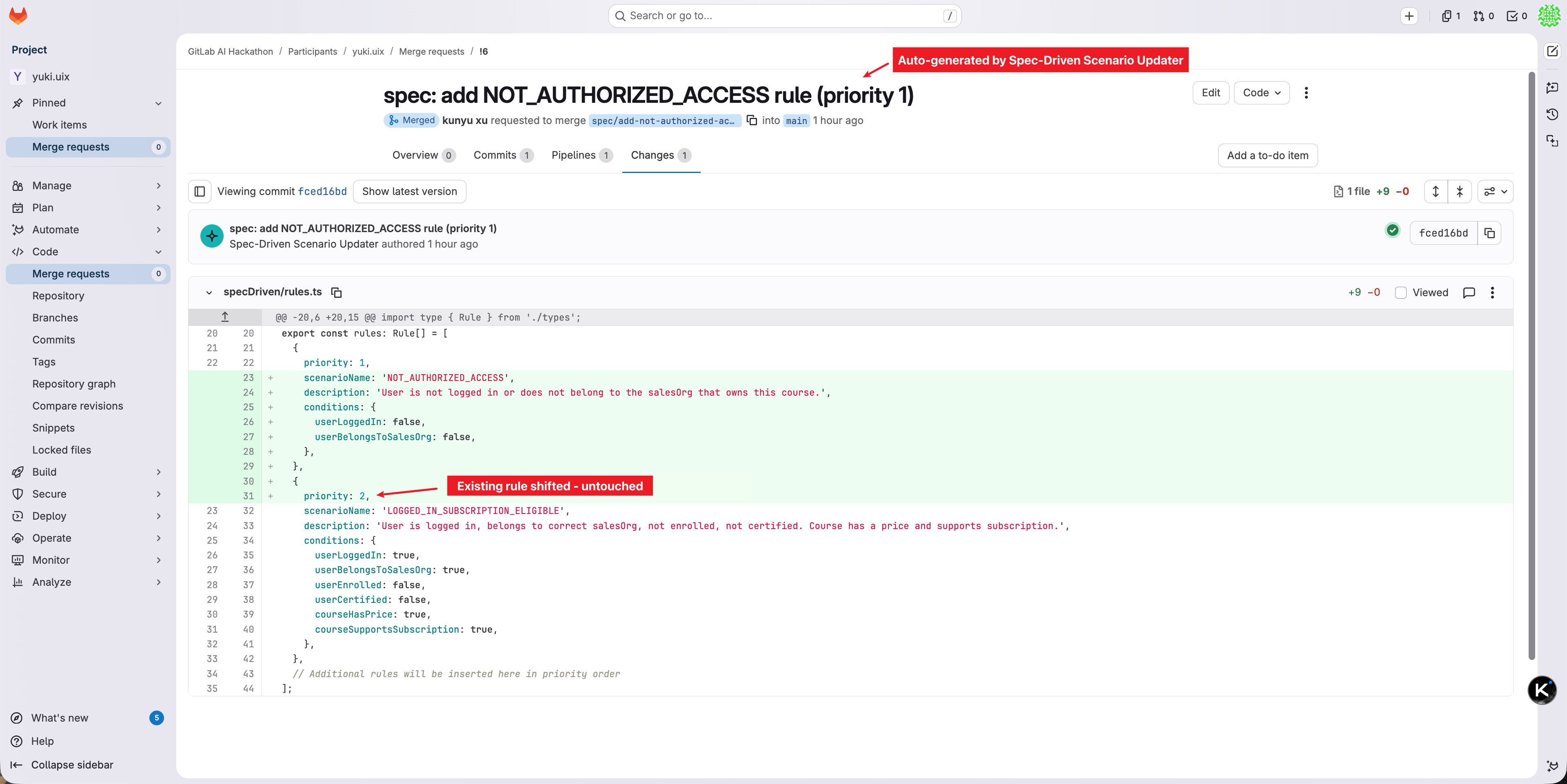
New rule inserted at correct priority. Existing rule shifts down. Nothing rewritten. Changes go through MR, never directly to main.
-
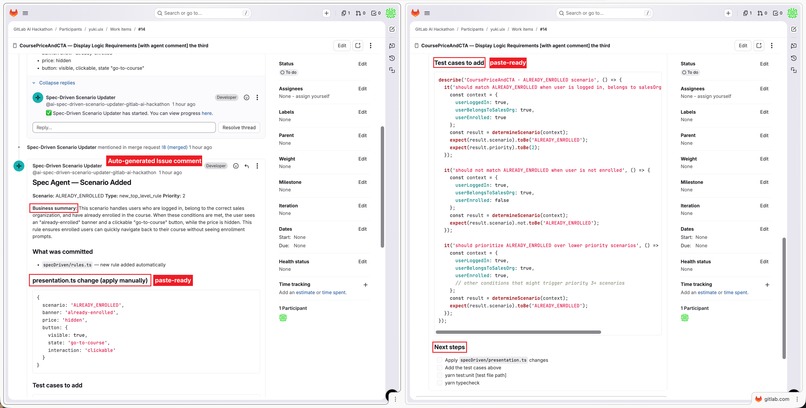
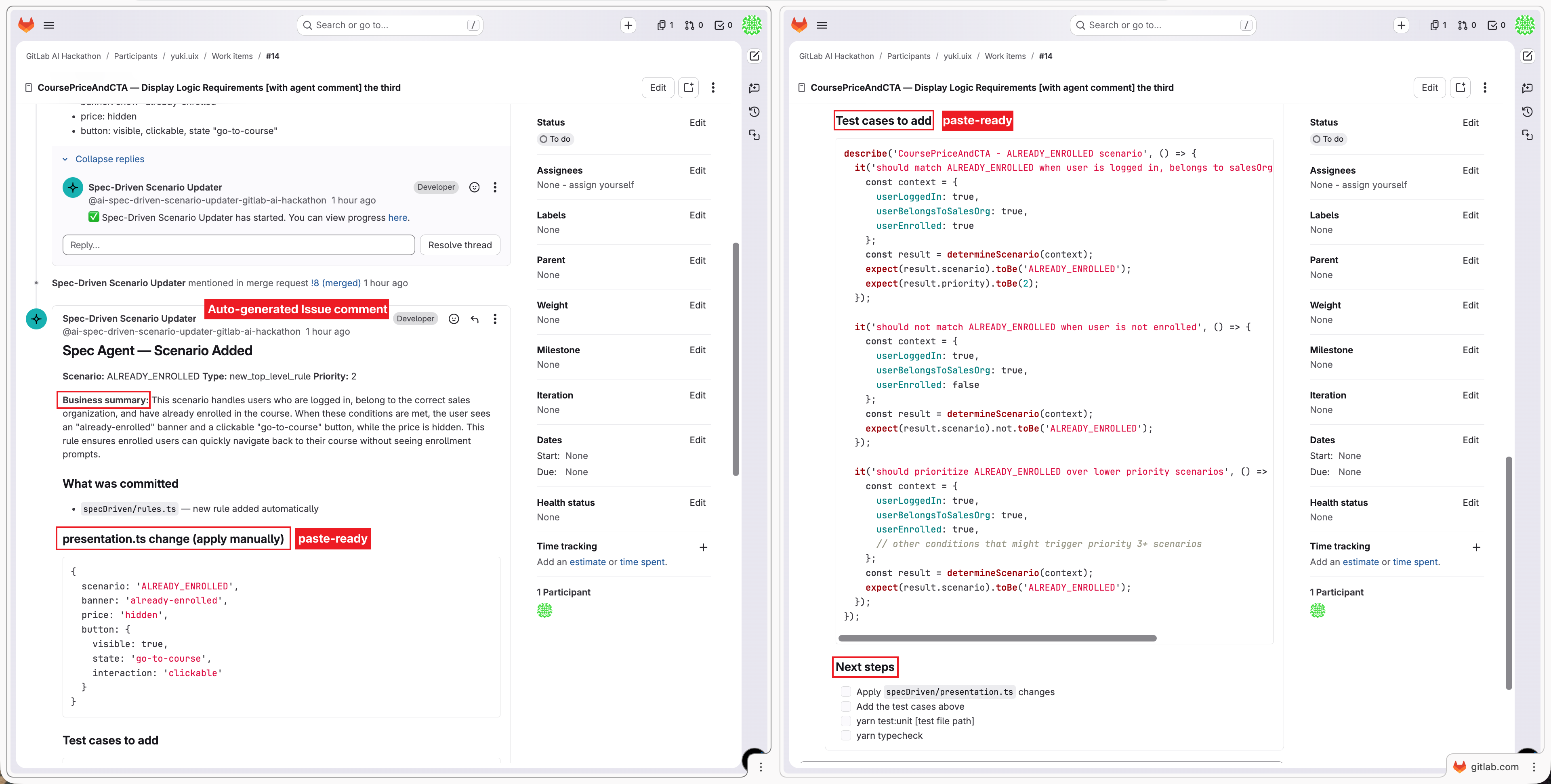
One reply: business summary, presentation.ts snippet, and Jest test cases — all auto-generated.
-
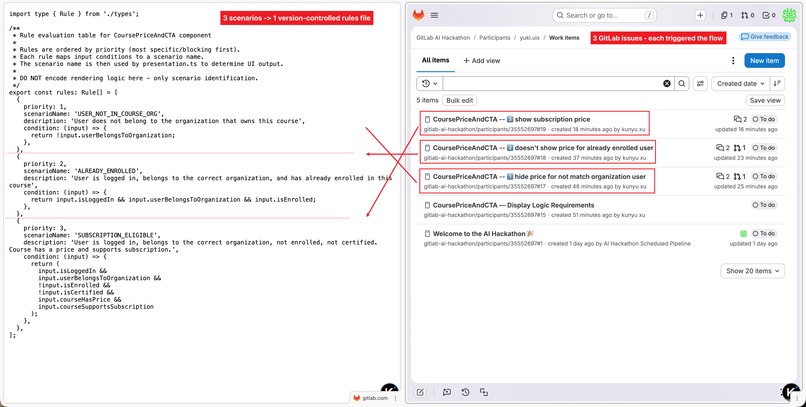
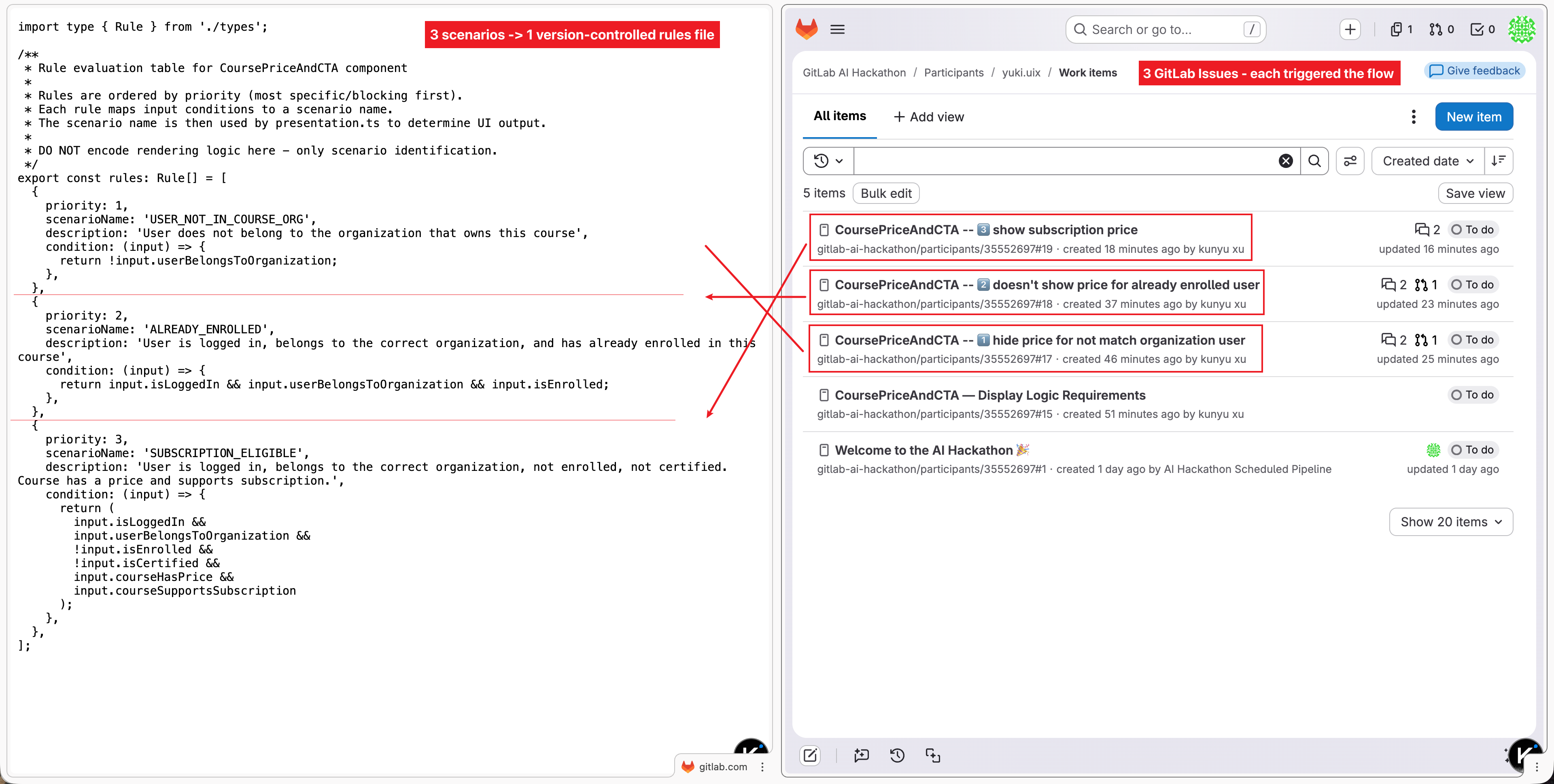
Three Issues. Three descriptions. One version-controlled rules file. No manual editing required.
Inspiration
Every enterprise frontend team has this problem. Nobody talks about it.
In a real-world frontend project, a single course detail page had to handle 8 state dimensions — 4 user states and 4 course states — resulting in up to 256 possible UI combinations. The business logic controlling banners, pricing display, and CTA buttons was described four separate times: by the BA in a requirements document, by UX in Figma annotations, by the developer in TypeScript hooks, and by QA in plain-text test case files.
None of these formats were compatible. When a requirement changed, all four roles had to re-sync in a meeting. The real logic lived in collective memory — not in code, not in any single file anyone could point to.
This is the Specification Gap. And it exists in every enterprise frontend team dealing with complex conditional UI logic.
The inspiration came from an unexpected place: architectural CAD drawings. A building's structural drawing is read by architects, structural engineers, contractors, and clients — each extracting what they need — but the drawing itself is one file. Change it once, everyone works from the updated version. We wanted to build the equivalent for UI state logic.
What it does
Spec-Driven Scenario Updater is a GitLab Duo Flow that turns natural-language UI scenario descriptions into structured, version-controlled TypeScript spec rules — directly inside your GitLab workflow.
A developer (or BA, or QA) describes a UI scenario in plain English inside a GitLab Issue by mentioning the flow. The flow then:
- Reads the existing
specDriven/rules.tsfrom the repository - Parses the scenario — classifying it as a gate condition (access control), user state condition (enrollment, certification), or course state condition (pricing, subscription) — and determines the correct priority placement relative to existing rules
- Commits the updated
rules.tsto a feature branch, inserting the new rule at the right priority position without touching existing rules - Opens a Merge Request to main for human review — changes never go directly to the main branch
- Posts a structured comment back to the Issue containing: a plain-English business summary,
presentation.tscode to apply manually, ready-to-use Jest test cases covering the new scenario, adjacent scenario regression, and fallback behavior, plus a next steps checklist with the MR link
Over time, the repository accumulates a single specDriven/rules.ts file that captures the full business logic — built incrementally, one scenario at a time, from natural language.
How we built it
The flow is built on the GitLab Duo Agent Platform using a four-component pipeline:
read_existing_rules (DeterministicStepComponent) — reads specDriven/rules.ts from the repository deterministically. If the file doesn't exist yet, returns a NO_RULES_FILE_FOUND signal that triggers first-rule creation logic downstream.
scenario_parser (AgentComponent) — receives the user's natural language description and the existing rules file. Outputs structured JSON classifying the scenario type and determining priority placement using a four-tier hierarchy: gate conditions → user state conditions → course state conditions → fallback.
spec_generator (AgentComponent) — generates the complete updated rules.ts content, commits it to a feature branch (spec/add-[scenario-name]-rule), then opens a Merge Request to main with a structured description.
post_comment (AgentComponent) — posts the full structured summary to the triggering Issue, including business summary, presentation.ts snippet, Jest test cases, and next steps checklist.
The spec file format uses TypeScript with as const satisfies Rule[] to preserve literal type precision, enabling downstream type checking and IDE autocompletion.
Challenges we ran into
GitLab Flow schema validation — the v1 schema has strict requirements around inputs format, toolset structure, unit_primitives, and the definition wrapper required by the hackathon platform. These were not fully documented in one place and required multiple iterations to get right.
File commit vs. MR creation — create_file_with_contents alone doesn't commit to a branch. The correct sequence required three separate tool calls: prepare file content, commit to feature branch, then open MR. Getting this sequence right took several debugging cycles.
Priority inference — the scenario parser initially placed gate conditions (like organization checks) at the wrong priority when existing rules were already present. This required strengthening the prompt with an explicit four-tier priority hierarchy to ensure blocking conditions always land at priority 1.
context:issue_iid availability — the issue_iid context variable was not reliably available as a named input. Solved by having the agent extract the IID directly from the goal context string, which includes Context: {Issue IID: X} in the trigger payload.
Accomplishments that we're proud of
End-to-end automation that actually works in production context — the flow was developed against a real enterprise codebase pain point, not a toy example. The 8-dimensional state machine used in demos is a simplified version of a real component.
The MR-as-safety-net design — making the flow open a Merge Request instead of committing directly to main was a deliberate security decision. Any team member can trigger the flow, but only maintainers can apply the change. This keeps humans in the loop for every spec decision while still removing the translation burden.
Priority inference across rule types — the flow correctly identifies whether a new scenario is a gate condition, user state, or course state, and inserts it at the right position relative to all existing rules, without reordering or modifying what's already there.
The Issue comment as a team artifact — the structured comment the flow posts back to the Issue is genuinely useful: the business summary is readable by BA and QA, the presentation.ts snippet is paste-ready for the developer, and the test cases cover regression scenarios that are easy to miss manually.
What we learned
Prompt engineering for structured output is harder than it looks — getting the scenario parser to reliably output valid JSON with correct priority placement required explicit examples, a strict four-tier hierarchy, and clear rules about what "gate condition" means in business terms, not just technical terms.
DeterministicStepComponent is the right tool for predictable file reads — using an AgentComponent to read a file introduces unnecessary LLM variability. The DeterministicStepComponent executes exactly one tool call with predetermined arguments, which is exactly what file reading requires.
The CAD drawing analogy is more than a metaphor — architectural training turned out to be directly applicable to this problem. The discipline of separating "what situation are we in" (rules.ts) from "what do we show" (presentation.ts) mirrors the architectural principle of separating structural drawings from finish drawings. The analogy helped clarify the design at every decision point.
GitLab Duo Agent Platform is genuinely capable for multi-step workflows — the four-component pipeline with conditional routing, tool access, and inter-component context passing handled a non-trivial workflow without requiring any external infrastructure.
What's next for Spec-Driven Scenario Updater
Automatically commit presentation.ts and test files — currently these are suggested in the Issue comment for manual application. The next step is having the flow commit them to the same feature branch as part of the MR, making the change fully self-contained.
Conflict detection — when a new scenario potentially overlaps with an existing rule, surface a warning in the Issue comment before opening the MR, prompting the team to clarify intent before merging.
Multi-component awareness — the current flow operates on a single component's rules file. Extending it to understand dependencies across components (e.g., a banner rule that affects both the detail page and a related listing page) would unlock cross-component consistency checking.
Bi-directional sync — generate the BA-readable scenario documentation and QA test case file automatically from the same rules source, closing the Specification Gap in all directions, not just the Dev direction.
AGENTS.md integration — use GitLab's AGENTS.md customization to let teams define their own component architecture, file paths, and priority hierarchies, making the flow portable across different codebases without prompt modification.
Built With
- ai-agent
- anthropic
- claude
- gitlab
- gitlab-duo
- typescript




Log in or sign up for Devpost to join the conversation.