
Inspiration
We were driven by the realization that effective communication is at the heart of every personal and professional interaction. Speech is not just about what you say. It's about how you say it. Yet millions struggle with speech anxiety, lack objective feedback, and fear judgment. They also lose opportunities, not due to a lack of skill, but due to the lack of the ability to properly express themselves. We saw an opportunity to harness AI and data visualization to bridge the gap between intent and delivery—especially for people with speech anxiety and autistic individuals—by providing real-time, personalized insights to build confidence and clarity.
What it does
SpeakViz is an AI-powered web platform that:
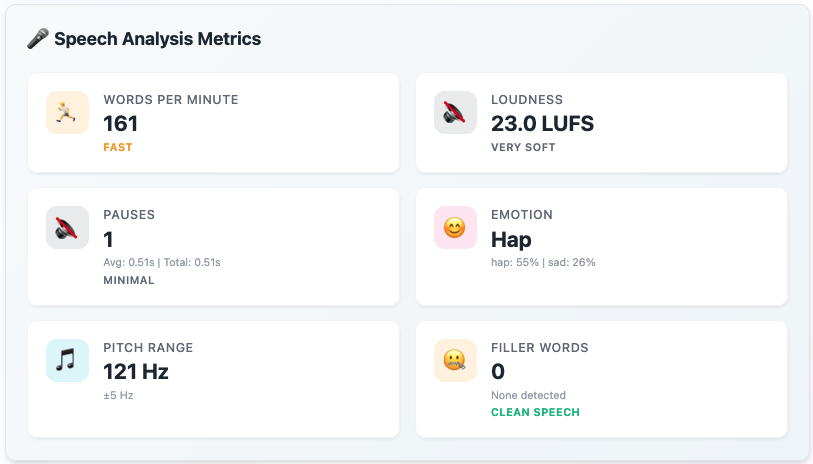
- Analyzes your speech in real time using the OpenSmile (Praat) library to extract metrics like speaking speed, volume, pitch variation, emphasis, stutters, fillers, and pauses, and a machine learning model to detect the speaker's emotion by taking in all the metrics as features.
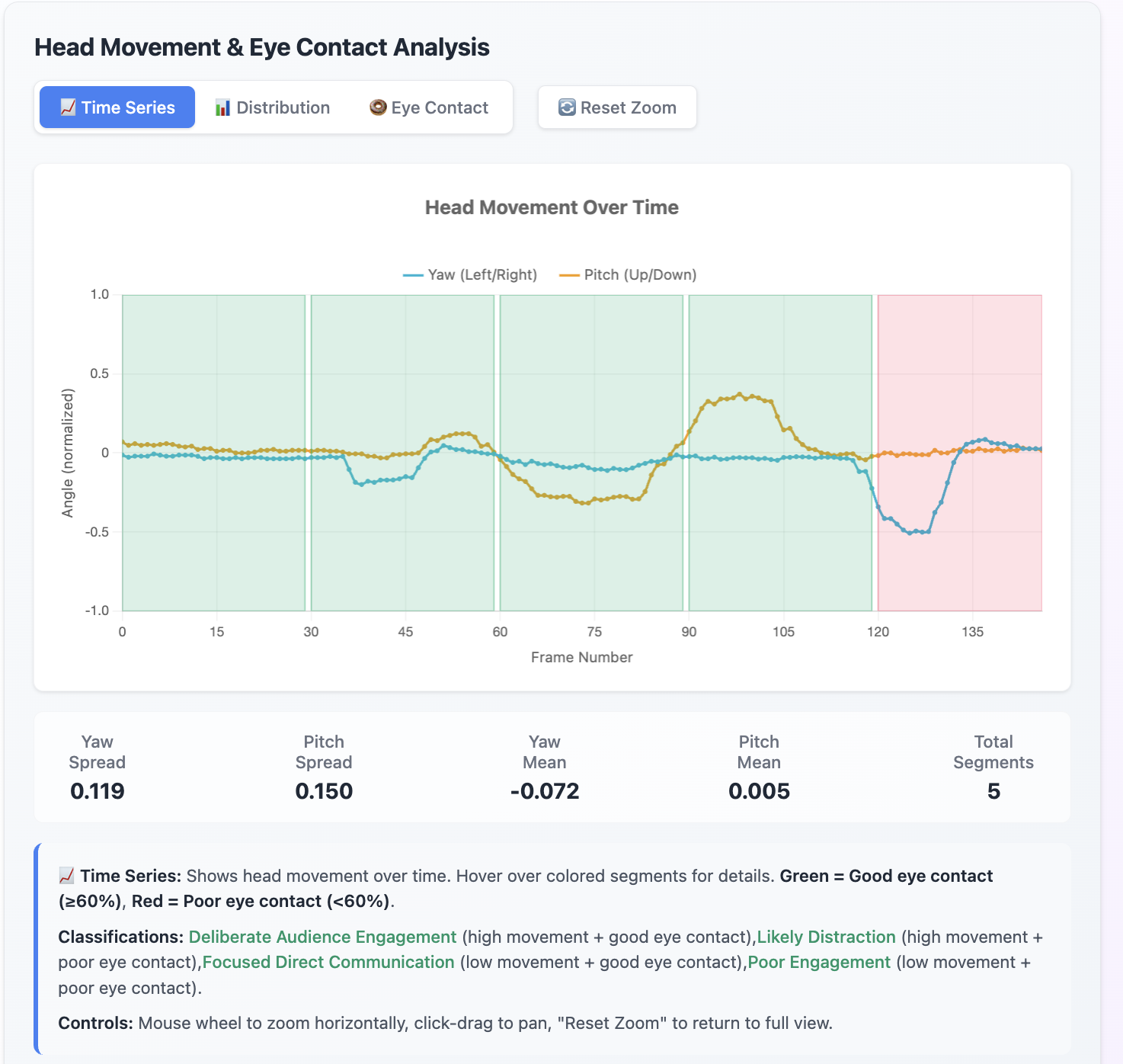
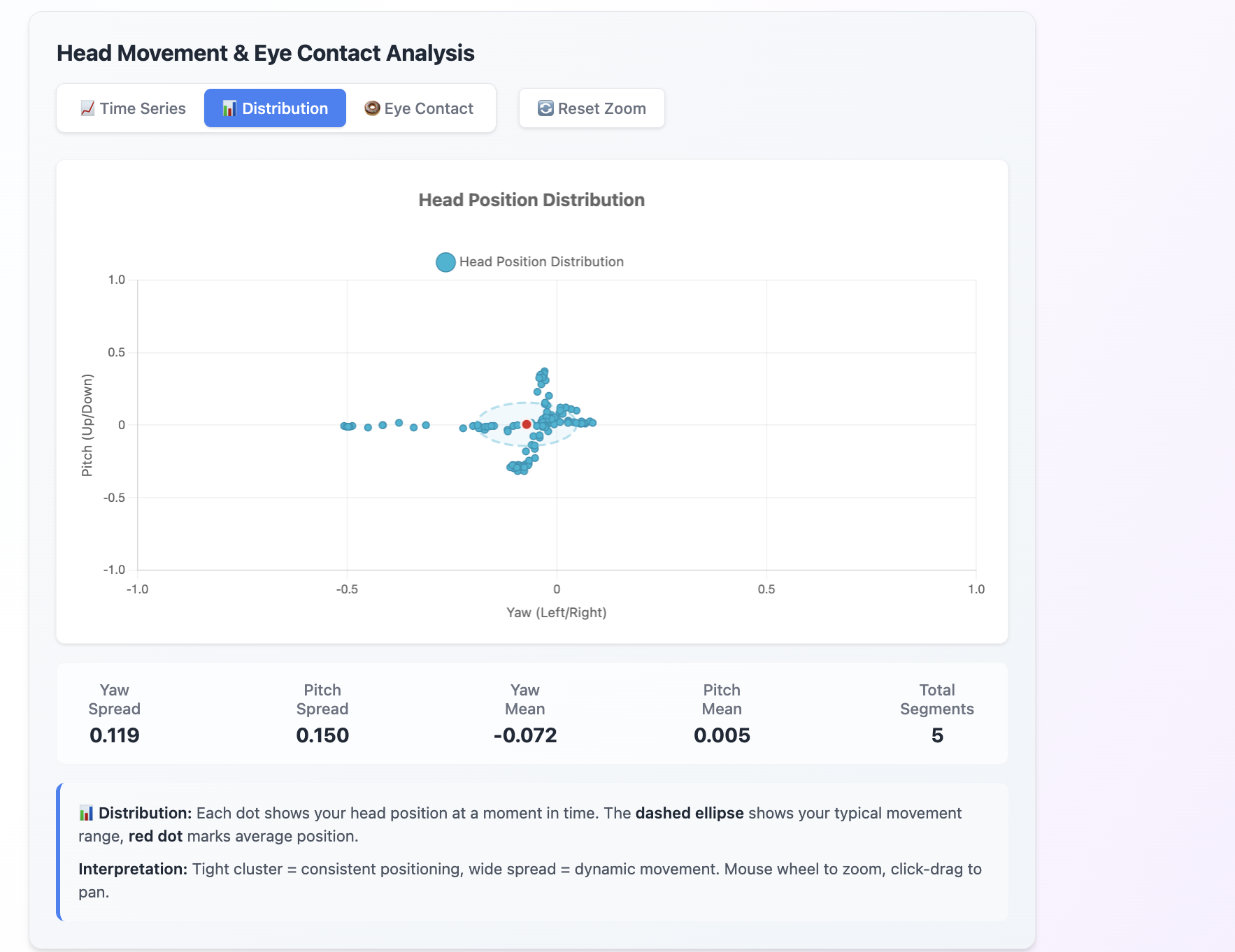
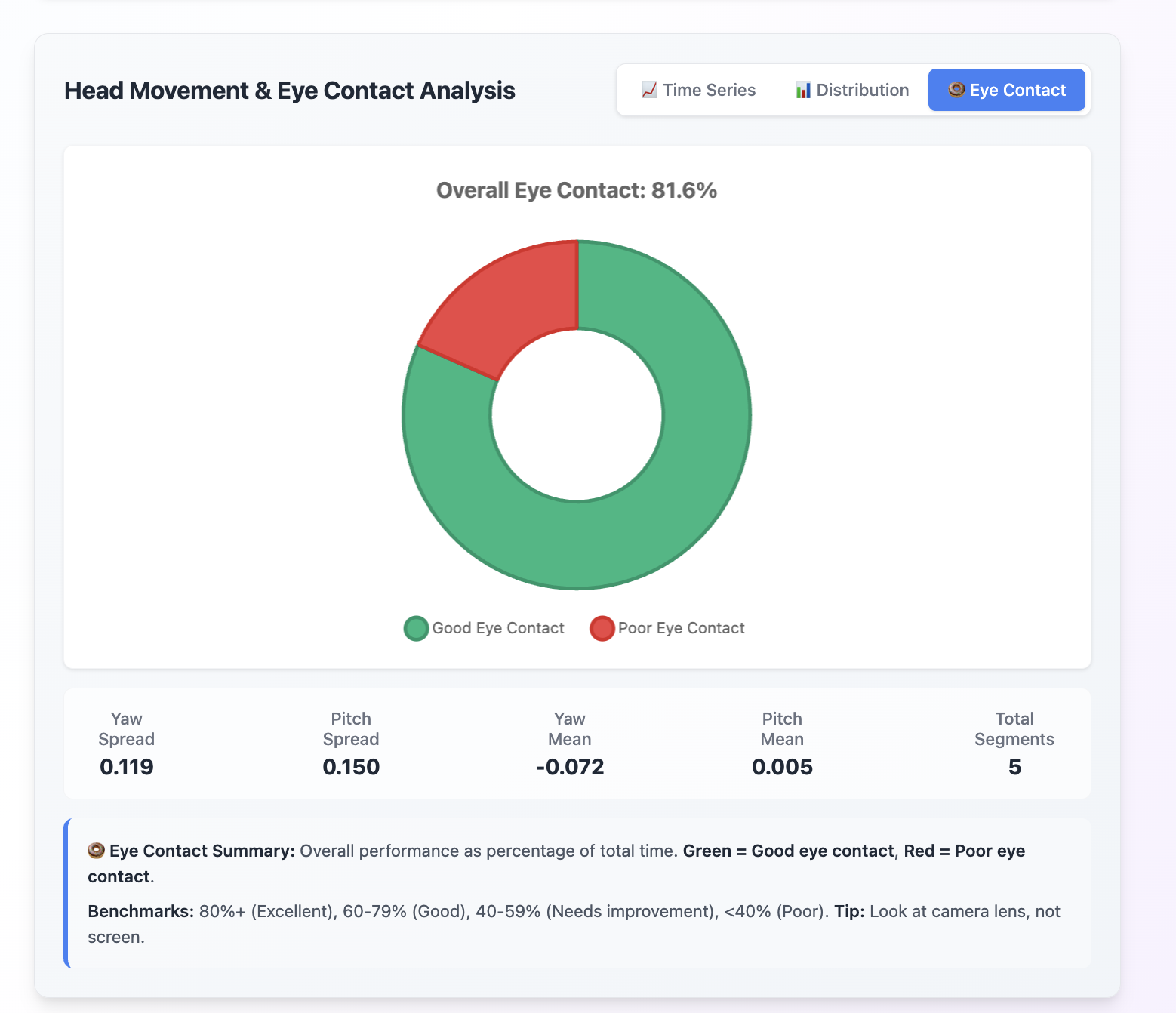
- Tracks facial expressions & head movements via the Human.js library, using a 3D face mesh and 468 facial landmarks to detect eye contact, and overall head movement (yaw and pitch)
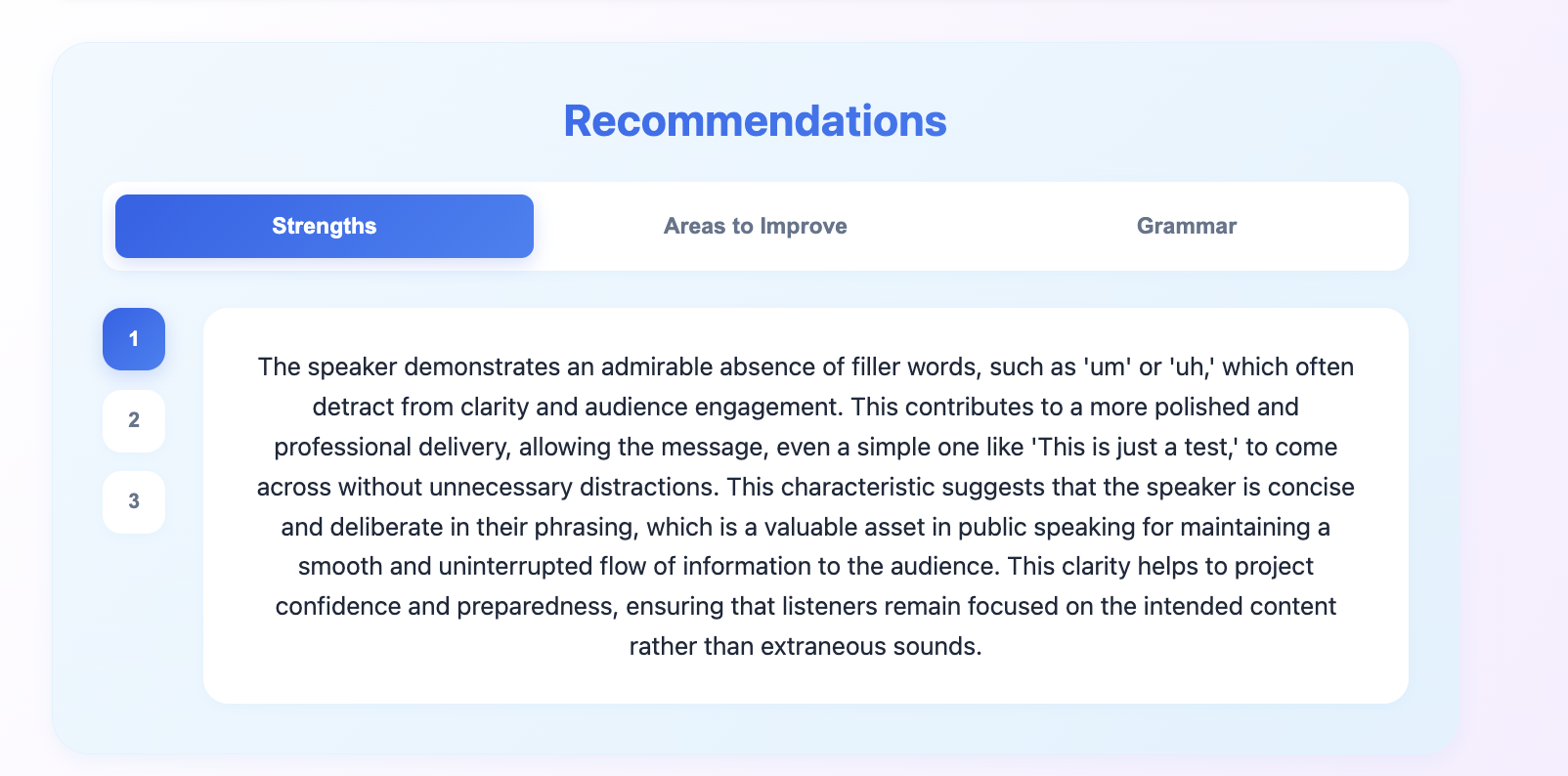
- Transcribes & interprets content with Whisper and Gemini 2.5 Flash to surface theme emphasis, emotional tone, and actionable feedback through strengths, areas to improve, and grammar corrections.
- Visualizes performance dynamically with reactchartjs charts and time-stamped feedback so users can pinpoint exactly where and how to improve. Time-series line charts, doughnut charts, scatter plots, and more!
- Offers role-play scenarios & exercises tailored to contexts (e.g., interviews, presentations, social interactions) for targeted practice.
How we built it
- Front End: React + Next.js + Reactchartjs for interactive visualizations; Human.js for live facial analysis through the video stream.
- Audio Processing: OpenSmile API (python) and Parselmouth (python) to stream raw audio features and for offline batch processing.
- Speech-to-Text & AI: OpenAI Whisper for real-time transcription; Gemini 2.5 Flash for semantic analysis, emphasis detection, and coaching prompts.
- Back End & Data: We used FastAPI to turn our python backend for speech metric analysis into our own API to be used by the frontend.
- Deployment & Infrastructure: Frontend hosted on Vercel, Backend on our own built server, and all database operations handled by Supabase, to store raw metrics, processed analytics, and session history for progress tracking (where users can view, delete, and create new or old recordings).
Challenges we ran into
Multi-Stream Synchronization
Aligning real-time audio, video, and transcription streams without lag was technically complex.Objective vs. Subjective Feedback
Prompt engineering the prompts for Gemini 2.5-Flash that felt genuinely helpful, rather than just dumping numbers, required iterative tuning and a lot of work. Definitely was a huge challengeFacial Analysis
While this seems broad and an obvious pick, it must be mentioned. We had to completely overhaul our pipeline and change it from faceapi.js to the human.js library, for 3D face tracking, and coding out the logic and maths for detecting eye contact, and overall face and head movement was a hugely iterative process!
Accomplishments that we’re proud of
- Prototype Completion: Built an end-to-end proof-of-concept with reactchartjs visualizations, a python backend using FastAPI, OpenSmile and Parselmouth for speech metric analysis, Human.js for facial analysis, and Whisper and Gemini for transcription and AI-powered feedback + coaching.
- True fusion of CV + NLP: Combined real-time face-tracking and analysis (yaw/pitch/gaze) with Whisper-powered speech transcription and Gemini-powered AI coaching, and OpenSmile-powered speech metric tracking.
- Compelling Pitch Deck: Won positive reviews at the Diamond Challenge, showcasing our unique value proposition and go-to-market plan.
- Team learning wins!!: Neither one of us had touched human.js, FastAPI WebSockets, or Supabase Storage before this hack; now they’re all talking nicely together!!
What we learned
- Holistic Feedback Matters: Users engage far more when verbal analytics are paired with non-verbal insights and concrete, scenario-based exercises.
- Therapist Collaboration is Key: We did interact with one speech therapist (un-licensed, but experienced in the field), to gather feedback on the feedback and outputs we were providing the end user with.
- Iteration Over Perfection: Rapid prototyping and user testing helped us prioritize the features that deliver the most impact.
- Market Nuances: While many AI speech coaches exist, combining multi-metric analysis with facial tracking (3D face mesh, 468 facial landmarks) and LLM-driven interpretation creates a truly differentiated offering.
What’s next for SpeakViz
**Fine-Tuned LLM" Currently we are using the Gemini 2.5-Flash model through a Gemini API key for AI powered coaching, feedback, and recommendations, but we want to use our own fine-tuned model or build a RAG architecture tailored to the problem of speech coaching, so that we can generate even more meaningful and helpful feedback + recommendations.
Institutional Partnerships
Onboard therapy centers, schools, and corporate trainers to pilot our B2B licensing and gather large-scale usage data.Feature Expansion
Hopefully introduce multi-lingual support through 1 or 2 more languages, advanced phonetic modules, and therapist dashboards for in-depth progress monitoring.Certification & Accreditation
In the very far future, collaborate with communication experts to offer recognized credentials and enhance credibility in education and HR markets.
Built With
- cloudflare
- faceapi
- human.js
- javascript
- machine-learning
- next
- opensmile
- parselmouth
- python
- react
- react-chart-js
- supabase
- tensorflow
- transformers
- vercel
- whisper



Log in or sign up for Devpost to join the conversation.