Inspiration
Over 150 million Japanese speakers are learning English, and pronunciation is consistently cited as their number one frustration. Sounds like R/L, TH, and V/B simply do not exist in Japanese phonology, making them extraordinarily difficult to acquire by ear alone.
Traditional pronunciation tools give learners a generic score or play a stranger's voice as the "correct" version. But hearing someone else say the word doesn't help you understand what YOUR mouth should do differently. The perceptual gap between your voice and a stranger's voice adds noise to the learning signal.
The core insight behind SpeakMirror is simple: what if you could hear yourself speaking perfect English? By cloning the learner's own voice and generating native-quality pronunciation with it, the gap between "what I sound like" and "what I should sound like" becomes immediately, viscerally obvious.
What it does
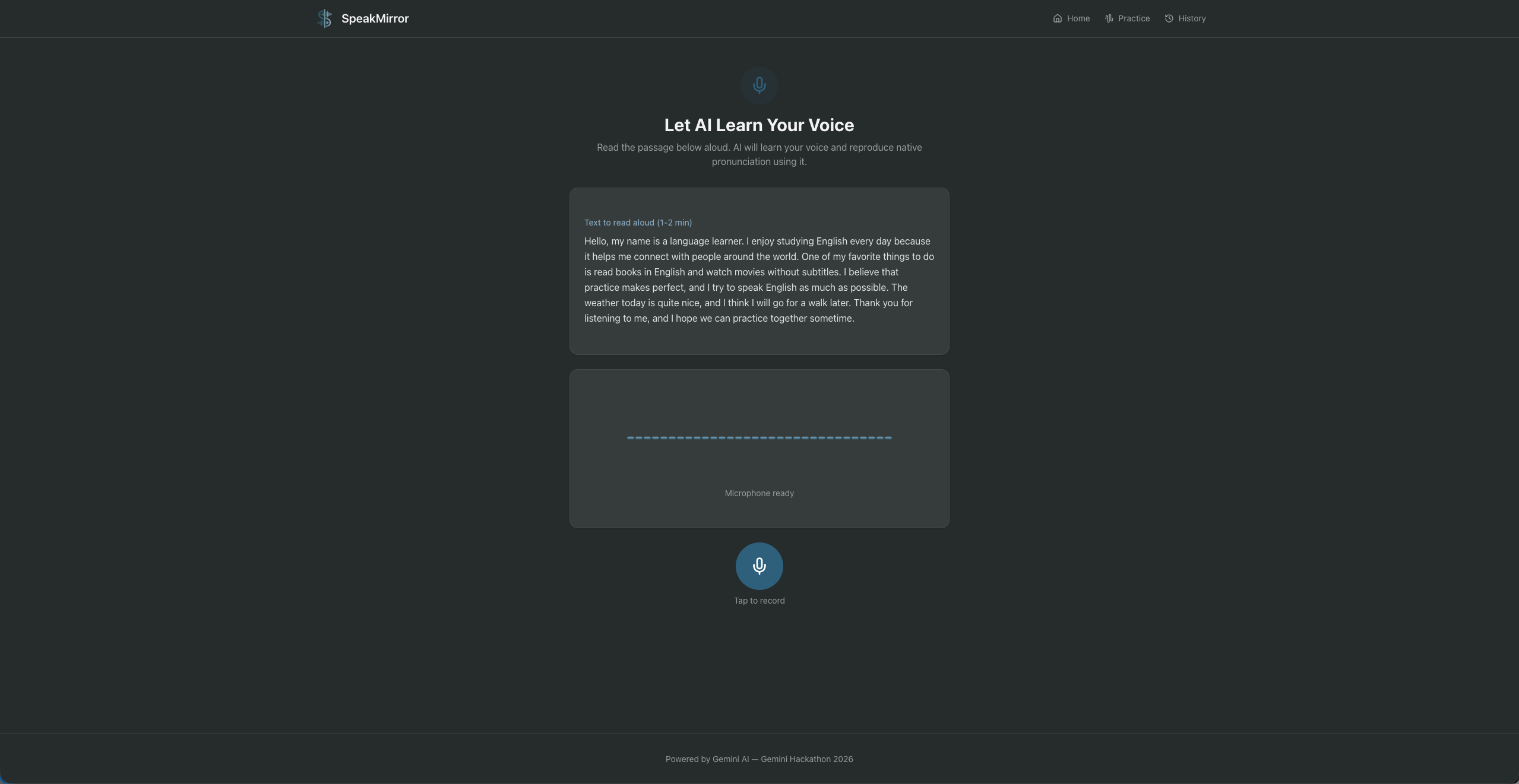
SpeakMirror is an AI-powered pronunciation coach that lets Japanese English learners hear their own voice speak perfect English.
- Voice Setup: Users read a short English passage aloud for about one minute. SpeakMirror creates an instant clone of their voice using ElevenLabs.
- Practice: Users select a pronunciation category (R/L, TH, V/B) and record themselves saying a word. Two things happen in parallel:
- Gemini 3 Flash analyzes the raw audio and delivers specific, actionable coaching tips in Japanese — not generic scores, but real advice like "curl your tongue back for the R sound."
- ElevenLabs generates the ideal native pronunciation in the user's own cloned voice for side-by-side comparison.
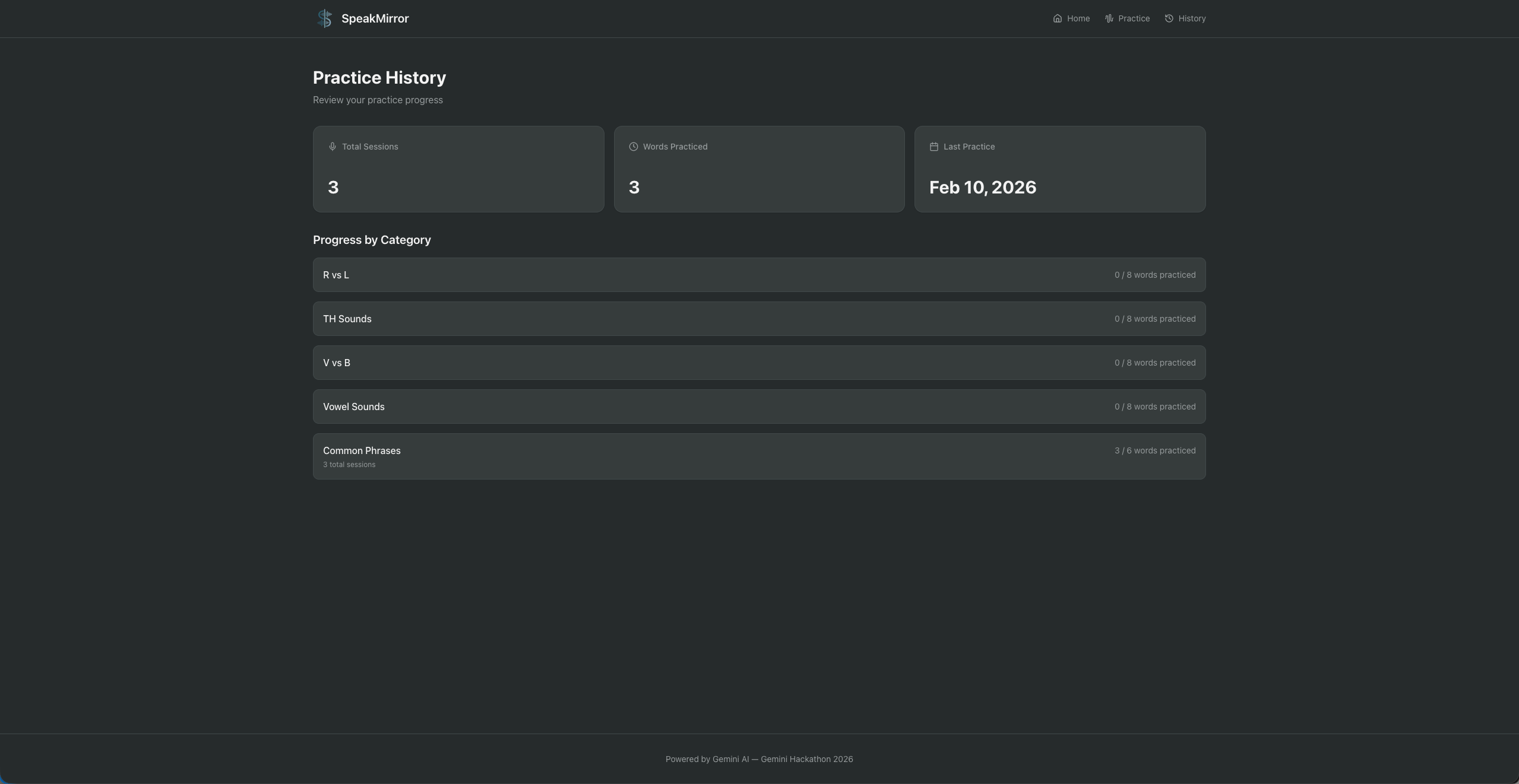
- Showcase: After practicing several words, Gemini generates a natural English monologue incorporating the words the user has mastered, read aloud by their voice clone — reinforcing pronunciation in natural context rather than isolated word drills.
How we built it
SpeakMirror is a full-stack web application built with Next.js 16, React 19, TypeScript, and Tailwind CSS 4, leveraging two AI services in parallel:
Gemini 3 Flash (Multimodal Audio Analysis): Raw audio is sent directly to Gemini as an inline data part — no speech-to-text preprocessing. This preserves acoustic nuances that a transcript would lose, such as aspiration, tongue placement artifacts, and vowel length. Gemini returns specific, actionable coaching advice rather than an abstract score.
ElevenLabs (Voice Clone + TTS): The user's voice sample is cloned via Instant Voice Clone (IVC). The voice ID is stored in localStorage and reused for all subsequent TTS generation with the Multilingual v2 model.
Parallel Processing: The analyze endpoint runs Gemini coaching and ElevenLabs TTS concurrently via Promise.all, cutting response time roughly in half and keeping the practice loop tight and engaging.
Model Fallback Chain: To handle API instability, we implemented a multi-model fallback chain with exponential backoff retry logic. The system tries gemini-3-flash-preview first, then falls back through gemini-2.0-flash, gemini-2.0-flash-lite, and gemini-1.5-flash.
| Layer | Technology |
|---|---|
| Framework | Next.js 16 (App Router) |
| UI | React 19 + Tailwind CSS 4 + Radix UI |
| Language | TypeScript 5 |
| AI (Audio Analysis) | Gemini 3 Flash (multimodal) |
| AI (Voice Clone + TTS) | ElevenLabs IVC + Multilingual v2 |
| Audio Capture | MediaRecorder API (audio/webm;codecs=opus) |
| State | localStorage + sessionStorage |
| Deployment | Vercel |
Challenges we ran into
The Pivot: The original concept was a video-based pronunciation scorer that would analyze lip movements. Early prototyping revealed this approach was both technically fragile (webcam quality varies wildly) and pedagogically shallow (a numeric score doesn't tell you how to improve). We pivoted to the voice-clone + listen-compare model, which turned out to be far more compelling.
Browser Audio Format Constraints: The MediaRecorder API produces audio/webm;codecs=opus, but Node.js Buffer objects don't directly convert to Blob for the ElevenLabs SDK. The fix was wrapping the buffer with new Uint8Array(buffer) — a small detail that cost real debugging time.
Gemini API Availability: During development, gemini-3-flash-preview occasionally returned 503 errors. Rather than showing users a failure screen, we built the multi-model fallback chain so the app remained functional with graceful degradation.
Keeping the Feedback Loop Fast: Pronunciation practice is only effective if the feedback loop is tight. Users lose motivation if they have to wait more than a few seconds. Running Gemini analysis and ElevenLabs TTS in parallel was essential to keeping response times under 3 seconds.
Accomplishments that we're proud of
- The voice cloning experience: Hearing your own voice speak perfect English is genuinely surprising and motivating. User testing showed this is far more effective than hearing a generic TTS voice.
- Real-time multimodal coaching: Sending raw audio directly to Gemini 3 Flash and getting specific, actionable coaching tips back — all within a few seconds — feels like magic.
- Resilient architecture: The multi-model fallback chain meant we never had a demo-breaking outage, even when individual Gemini preview models had downtime.
- Clean parallel processing: The
Promise.allpattern cuts response time in half without adding significant complexity, making the practice flow feel responsive rather than tedious. - Full pivot execution: We completely changed our approach from video-based scoring to voice-clone coaching mid-project and delivered a polished result.
What we learned
Multimodal AI changes the architecture. Being able to send raw audio directly to Gemini eliminated an entire STT preprocessing step and preserved acoustic information that would have been lost in transcription. The model understands audio natively — that's a fundamental shift from the "transcribe first, analyze second" paradigm.
Self-referential feedback is a powerful motivator. Hearing your own voice speak perfect English is far more motivating than hearing a generic TTS voice. The psychological effect of recognizing yourself in the "correct" version makes the gap feel achievable rather than intimidating.
Graceful degradation matters. Preview APIs can be unstable. Building a fallback chain from day one meant we never had a demo-breaking outage, even when individual models had downtime.
Parallel API calls are worth the complexity. The difference between sequential and parallel processing was the difference between a 6-second and a 3-second feedback loop — and that 3 seconds made the practice flow feel responsive rather than tedious.
Simple state management is underrated. Using localStorage for progress and sessionStorage for ephemeral practice results kept the architecture lean. Not every app needs a database on day one.
What's next for SpeakMirror
- More languages: Expand beyond Japanese speakers to support Korean, Chinese, Spanish, and other learners who struggle with English pronunciation.
- Pronunciation scoring: Add quantitative scoring alongside qualitative coaching tips, using Gemini's audio analysis to track improvement over time.
- Spaced repetition: Integrate a spaced repetition system that resurfaces words the user struggled with at optimal review intervals.
- Mobile app: Build a native mobile experience with offline support for practicing on the go.
- Conversation practice: Extend from single-word drills to full sentence and conversation practice, with real-time pronunciation feedback during natural dialogue.
- Progress analytics: Add detailed dashboards showing improvement trends across phoneme categories, practice streaks, and mastery milestones.
Built With
- elevenlabs
- gemini3
- next
- react
- tailwind
- typescript
- vercel

Log in or sign up for Devpost to join the conversation.