-
-
Home Page
-
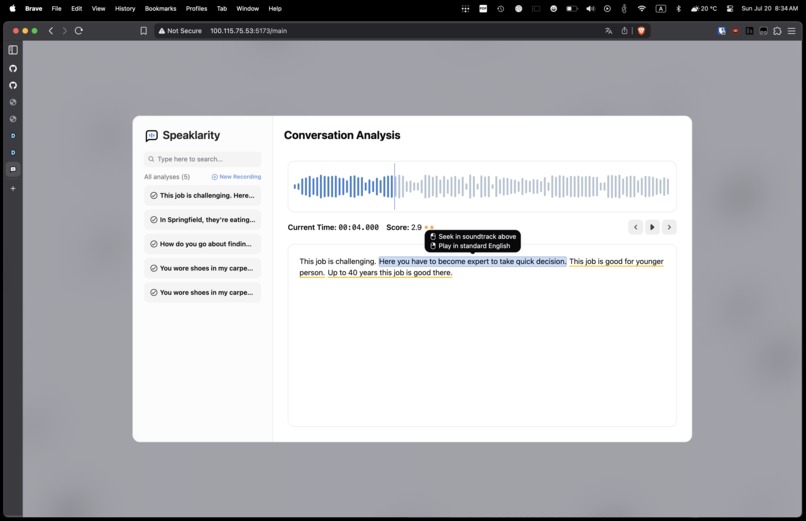
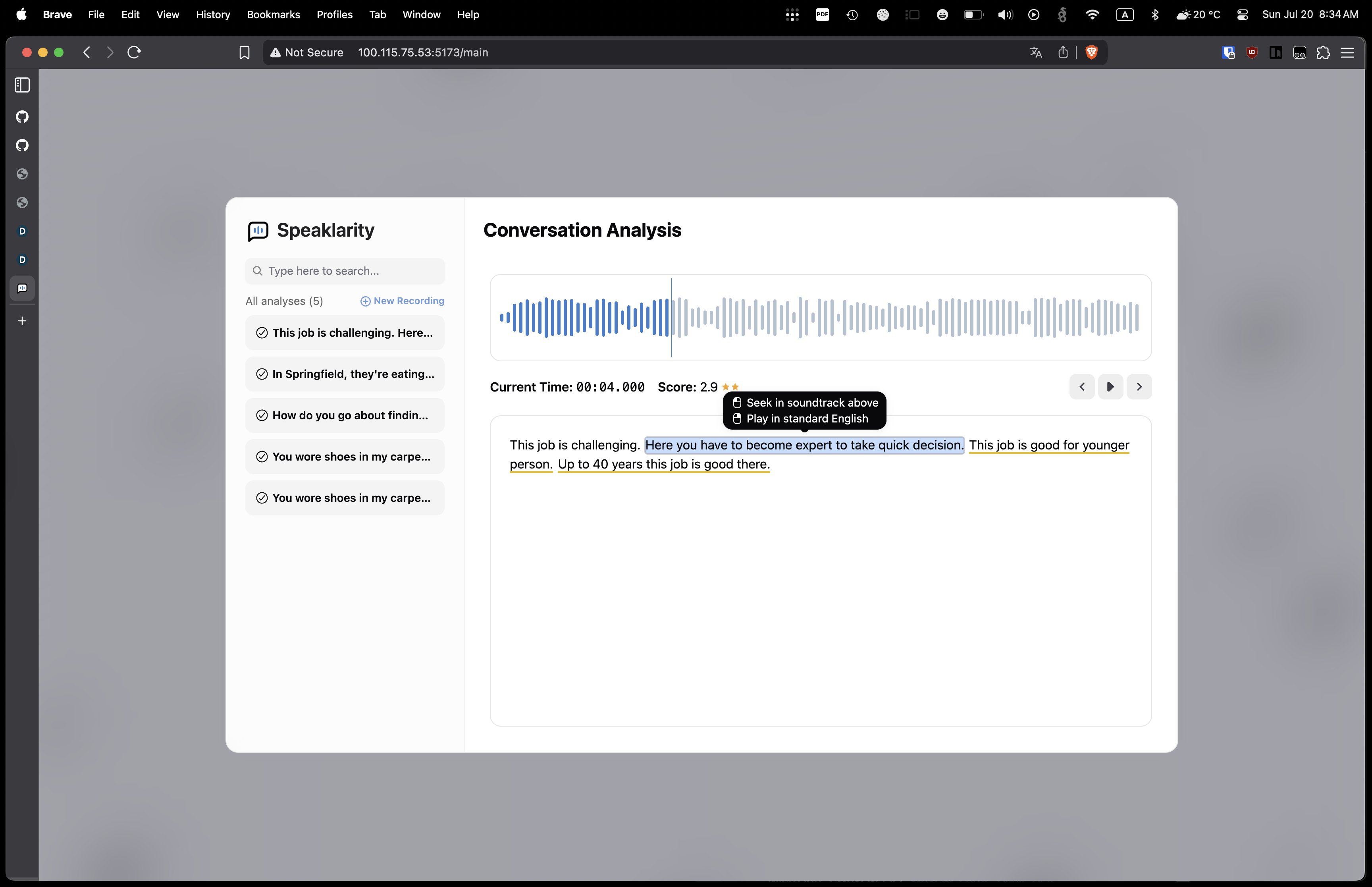
Conversation Analysis
-
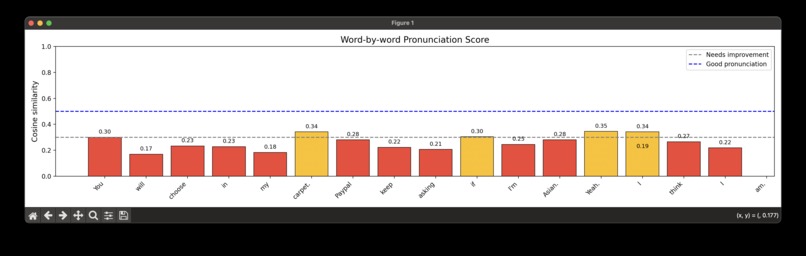
Word-by-word Pronunciation Score


Inspiration
This project is deeply personal to us because as non-native English speakers, one of the biggest challenges we faced upon arriving in Canada and continue to encounter in our daily lives is effective communication. Struggles with grammar, phonetics, and pronunciation have shaped our experiences growing up, often making it difficult to fully express ourselves or connect with others. Through this project, we want to address a challenge that is not just ours, but shared by many, especially in a country as diverse and multicultural as Canada. With immigration continuing to enrich Canadian society, we saw a need for a tool that offers personalized and constructive feedback to help individuals improve their spoken English skills. Our goal is to empower users with greater confidence and clarity in their communication, one conversation at a time.
What it does
Speaklarity is an interactive language learning tool designed to help users refine their oral English skills through feedback analysis. The website will record your conversations and transcribe them into text. From there, Speaklarity is able to analyze the user’s accent, grammar, and phonetics to identify areas for improvement.
- Accent: Using Whisper for transcription and WavLM for embedding-based scoring, Speaklarity evaluates pronunciation accuracy word-by-word by comparing users' speech with native references.
- Grammar: Leveraging Google’s Gemini API, the tool analyzes sentence structure, tense usage, and word choice to provide context-aware grammar corrections.
- Phonetics & Feedback: Key errors are underlined in the transcript, and users can hover to receive tailored tips. AI-generated audio corrections via gTTS allow users to hear and mimic native-like speech.
How we built it
On the backend, we used Python with the Flask framework to handle API endpoints, audio processing, and feedback generation. For transcription and forced alignment, we locally deployed OpenAI’s Whisper model, which converts user speech into text while preserving precise word-level timestamps. To evaluate pronunciation, we extracted acoustic embeddings from user audio using Microsoft’s WavLM and compared them to native references using vector similarity. Grammar analysis was powered by Google’s Gemini API, which provided context-aware corrections for each sentence. To support auditory learning, we integrated gTTS to synthesize corrected speech in a native accent. Additional tools like FFmpeg and librosa were used for audio normalization, segmentation, and visualization. Together, these backend components created a scalable, privacy-preserving system capable of detailed linguistic analysis.
On the frontend, we built a responsive, user-friendly web interface using React with TypeScript, styled with Tailwind CSS and HeroUI for a modern aesthetic. Users can record audio, view live transcriptions, and explore feedback through interactive visual cues, such as underlined errors and hover-to-reveal explanations. Framer Motion adds smooth transitions and animations, while React Router manages multi-page navigation. The app runs locally via Vite for rapid development and testing. This frontend design ensures that users—from language learners to professionals—can engage with their speech data in an intuitive, informative, and empowering way.
Challenges we ran into
- Accent evaluation: There are no APIs or established solutions for detecting and analyzing pronunciation accuracy. We overcame this by implementing a custom solution based on academic research using Whisper and WavLM.
- Word-level scoring: Ensuring accurate forced alignment and word-to-word comparison required careful embedding extraction, normalization, and similarity computation.
- Latency: Audio processing is computationally expensive, so we optimized pre-processing and chunk-level batching for speed.
Accomplishments that we're proud of
- We implemented a complete word-level pronunciation scoring system from scratch using open-source models.
- Integrated grammar correction with real-time, personalized feedback.
- Built a fully functional, visually appealing, and accessible frontend for users of all backgrounds.
What we learned
- Speech processing and embedding-based similarity scoring
- Real-time transcription and forced alignment
- Large language model integration (Gemini, Whisper)
- Cross-stack development and user-centred design
- And personally, we even improved our own pronunciation and grammar along the way.
What's next for Speaklarity
- Incorporation of real-time interaction features that allow users to receive immediate feedback as they speak to help make the learning process more intuitive and engaging
- Daily conversations exercises to promote consistent practice
- Automated daily reports that summarize user performance over time using meta-analysis
- Mobile app that allows Speaklarity to be more accessible for users to track their progress anywhere at anytime


Log in or sign up for Devpost to join the conversation.