-
Hmmm... That's an interesting concept. Tell me more!
-
That's interesting. How does it work in practice?
-
Let's record something.
-
Oh, it worked!
-
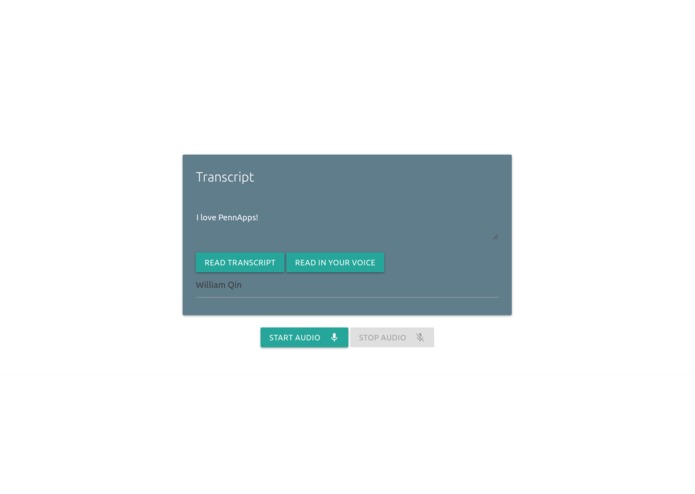
Hey, this field is editable?
-
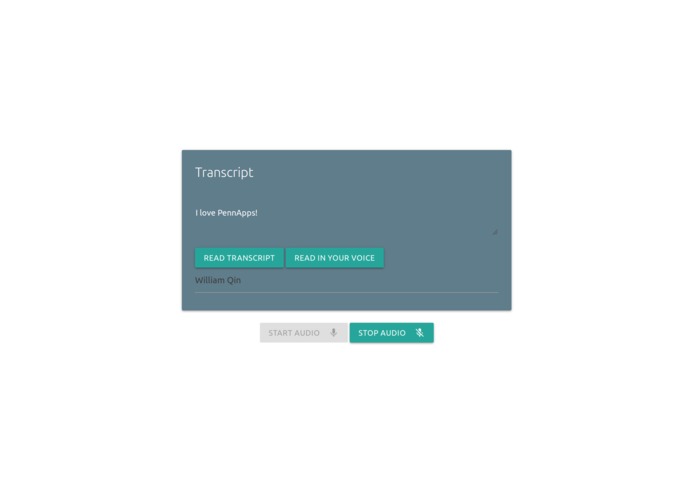
Okay, let's record some audio, to train the thing on my voice. Luckily I only have to do this the first time.
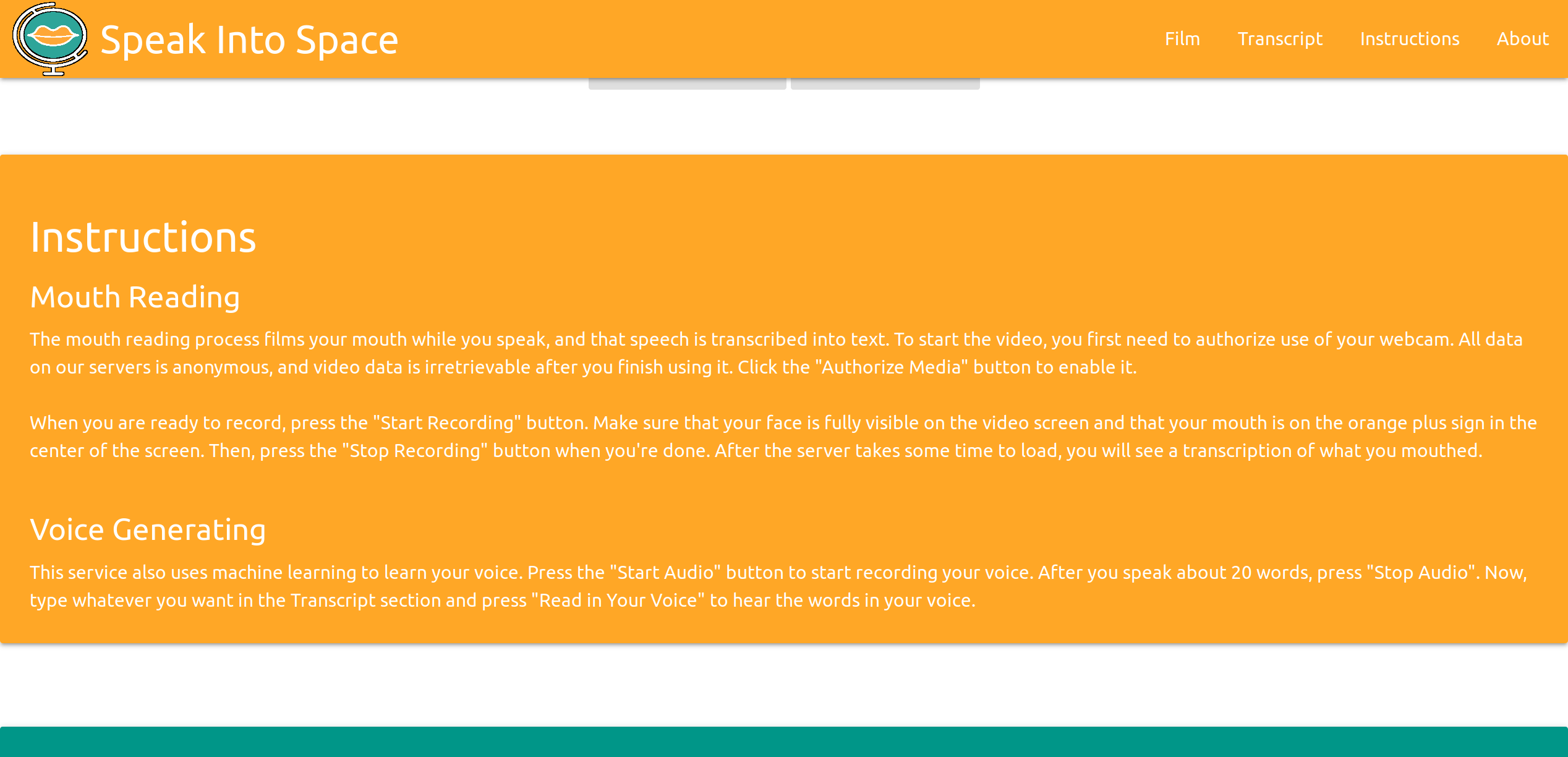
Inspiration
There are thousands of people worldwide who suffer from conditions that make it difficult for them to both understand speech and also speak for themselves. According to the Journal of Deaf Studies and Deaf Education, the loss of a personal form of expression (through speech) has the capability to impact their (affected individuals') internal stress and lead to detachment. One of our main goals in this project was to solve this problem, by developing a tool that would a step forward in the effort to make it seamless for everyone to communicate. By exclusively utilizing mouth movements to predict speech, we can introduce a unique modality for communication.
While developing this tool, we also realized how helpful it would be to ourselves in daily usage, as well. In areas of commotion, and while hands are busy, the ability to simply use natural lip-reading in front of a camera to transcribe text would make it much easier to communicate.
What it does
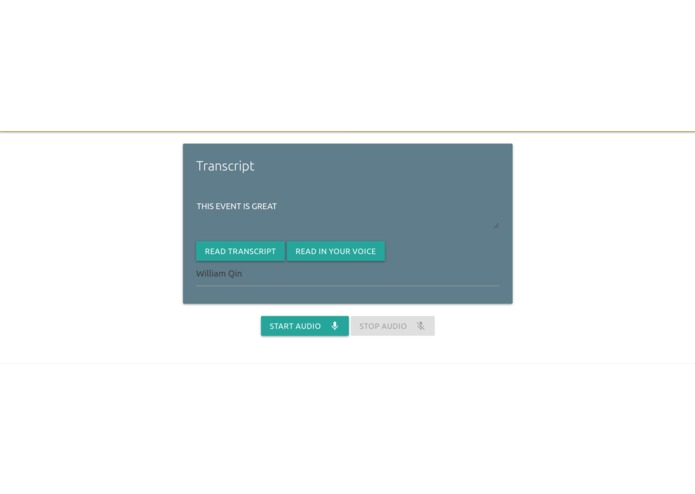
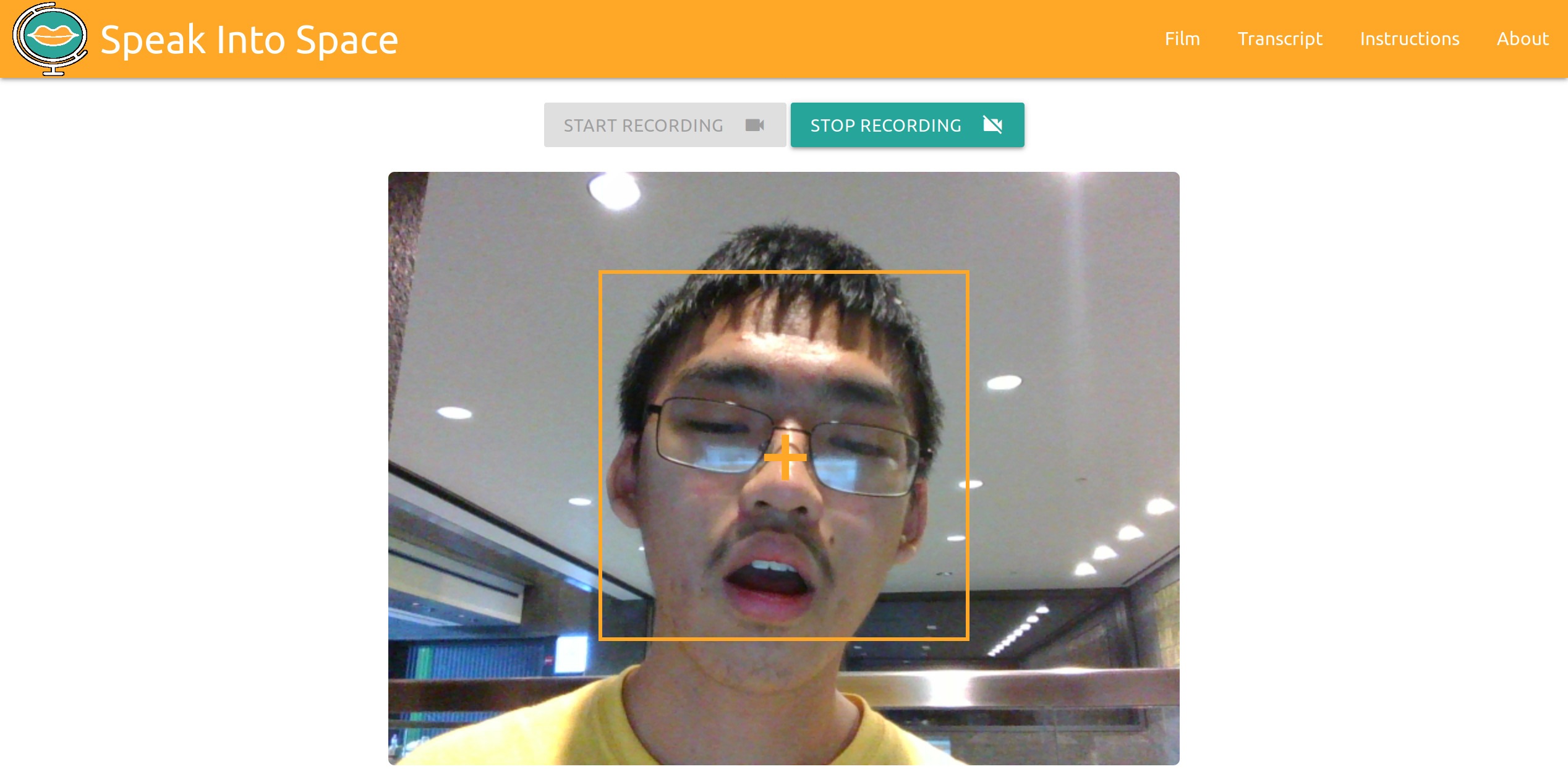
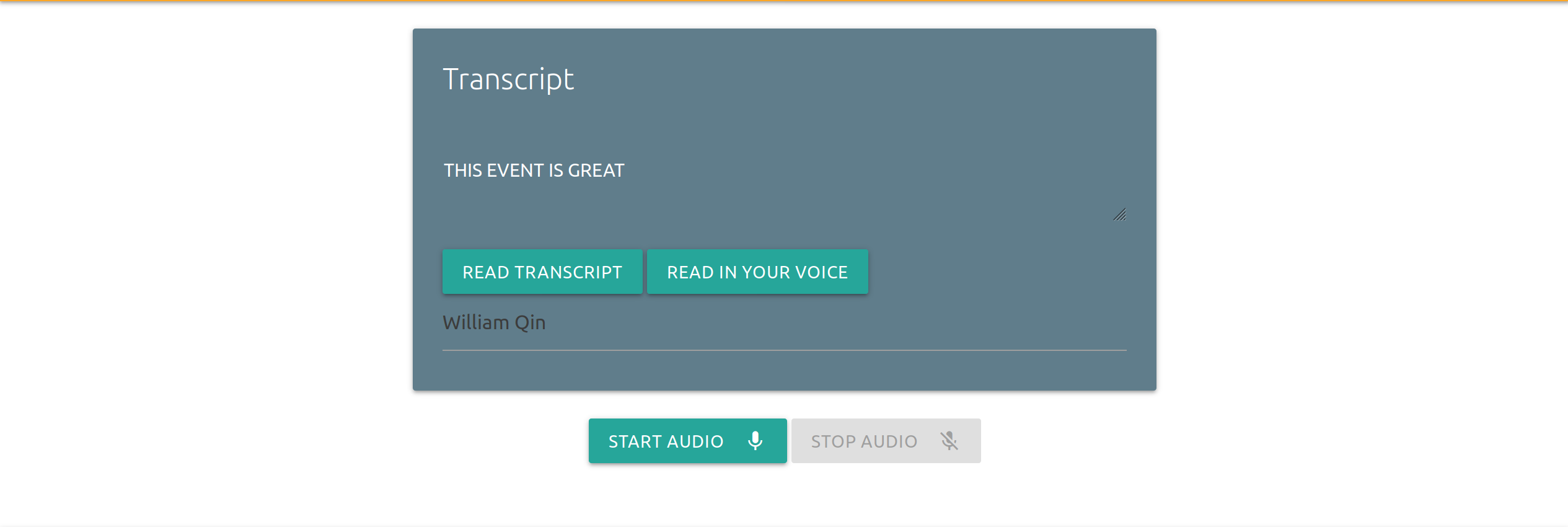
The Speakinto.space website-based hack has two functions: first and foremost, it is able to 'lip-read' a stream from the user (discarding audio) and transcribe to text; and secondly, it is capable of mimicking one's speech patterns to generate accurate vocal recordings of user-inputted text with very little latency.
How we built it
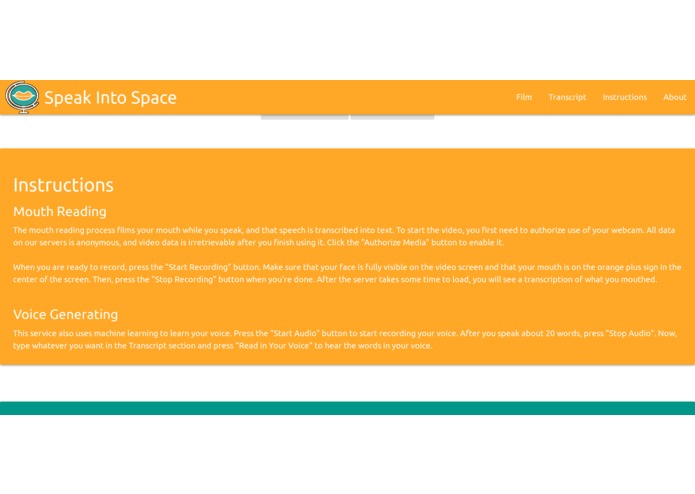
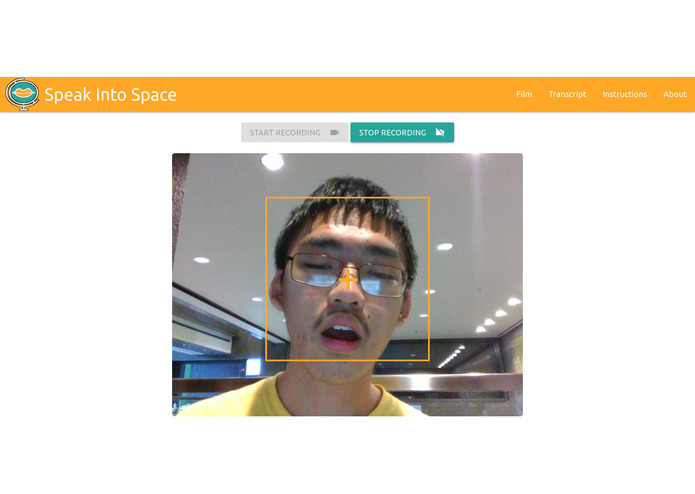
We have a Flask server running on an AWS server (Thanks for the free credit, AWS!), which is connected to a Machine Learning model running on the server, with a frontend made with HTML and MaterializeCSS. This was trained to transcribe people mouthing words, using the millions of words in LRW and LSR datasets (from the BBC and TED). This algorithm's integration is the centerpiece of our hack. We then used the HTML MediaRecorder to take 8-second clips of video to initially implement the video-to-mouthing-words function on the website, using a direct application of the machine learning model.
We then later added an encoder model, to translate audio into an embedding containing vocal information, and then a decoder, to convert the embeddings to speech. To convert the text in the first function to speech output, we use the Google Text-to-Speech API, and this would be the main point of future development of the technology, in having noiseless calls.
Challenges we ran into
The machine learning model was quite difficult to create, and required a large amount of testing (and caffeine) to finally result in a model that was fairly accurate for visual analysis (72%). The process of preprocessing the data, and formatting such a large amount of data to train the algorithm was the area which took the most time, but it was extremely rewarding when we finally saw our model begin to train.
Accomplishments that we're proud of
Our final product is much more than any of us expected, especially the ability to which it seemed like it was an impossibility when we first started. We are very proud of the optimizations that were necessary to run the webpage fast enough to be viable in an actual use scenario.
What we learned
The development of such a wide array of computing concepts, from web development, to statistical analysis, to the development and optimization of ML models, was an amazing learning experience over the last two days. We all learned so much from each other, as each one of us brought special expertise to our team.
What's next for speaking.space
As a standalone site, it has its use cases, but the use cases are limited due to the requirement to navigate to the page. The next steps are to integrate it in with other services, such as Facebook Messenger or Google Keyboard, to make it available when it is needed just as conveniently as its inspiration.
Built With
- amazon-web-services
- flask
- google-text-to-speech
- html5
- javascript
- materializecss
- opencv
- pytorch
- sklearn
- tensorflow





Log in or sign up for Devpost to join the conversation.