
Verbatim
Dub, Discover, and Query any video in seconds.
GitHub »
Sonny Chen
·
Cindy Yang
·
Karthik Thyagarajan
·
Pranav Neti
About The Project
Whether it’s educational lectures, news reports, or social media content, viewers often struggle with long-form videos in languages they don’t understand. Existing solutions offer subtitles, but they fail to capture the natural experience of watching a speaker.
Our Solution
Verbatim is an intelligent platform that takes any video, summarizes it for quicker consumption, translates it into multiple languages, and then recreates the speaker’s lip movements to match the new audio—delivering a seamless, localized experience.
Built With
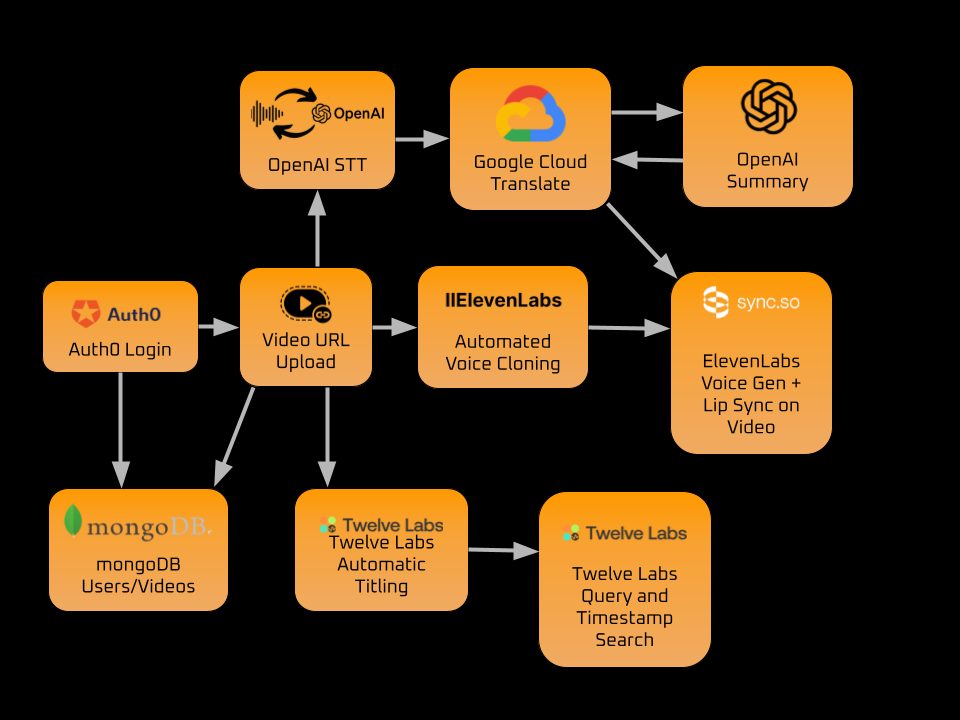
Speech-to-Text (STT) – OpenAI Whisper
Function: Converts spoken content from a video into a text transcript.
How It Works: Whisper is a multi-lingual, neural-network-based automatic speech recognition (ASR) system. It uses a large transformer model trained on diverse datasets to deliver accurate transcription across multiple languages.
Translation – Google Cloud Translation API
Function: Translates the transcribed text into different languages.
How It Works: Uses Google’s neural machine translation (NMT) model to deliver fast, context-aware translations across 100+ languages.
Summarization – OpenAI GPT
Function: Reduces long transcripts into concise summaries while preserving the main ideas.
How It Works: GPT models use transformer-based language models to analyze and compress long-form content into digestible summaries. You can fine-tune the length and detail of the summary.
Lip-Sync Generation (Sync.so API):
Function: Animates a speaker’s face to match the translated and summarized text.
How It Works: Sync.so uses deep learning to generate realistic lip movements that match the audio. It can be used to create localized versions of videos in multiple languages.
User Q&A Interface – TwelveLabs API
Function: Allows users to ask questions about the video content and receive context-aware responses.
How It Works: TwelveLabs stores vector embeddings of the video and speech in the video as context, allowing real-time semantic search and natural conversation.
MLH Technologies
MongoDB
MongoDB was used to store user data, video metadata, and generated content. It was also used to store the video transcript, summary, and translations.
Auth0
Auth0 was used for user authentication and authorization. It was used to secure user data and ensure that only authenticated users could access the platform.
Contact
Sonny Chen - chen5021@purdue.edu
Cindy Yang - cwyang@umich.edu
Karthik Thyagarajan - kthyagar@purdue.edu
Pranav Neti - pneti@purdue.edu
Built With
- auth0
- google-cloud
- mongodb
- next.js
- openai
- tailwind
- vercel





Log in or sign up for Devpost to join the conversation.