-
-

SpeakEZ Logo
-
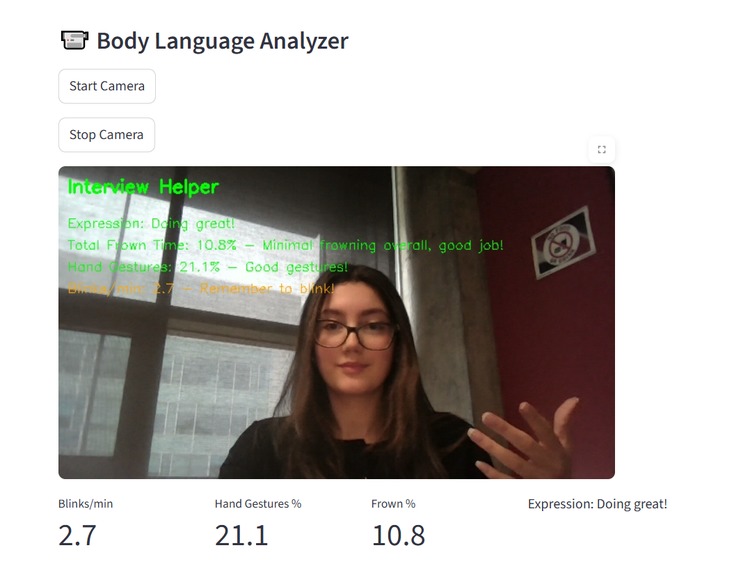
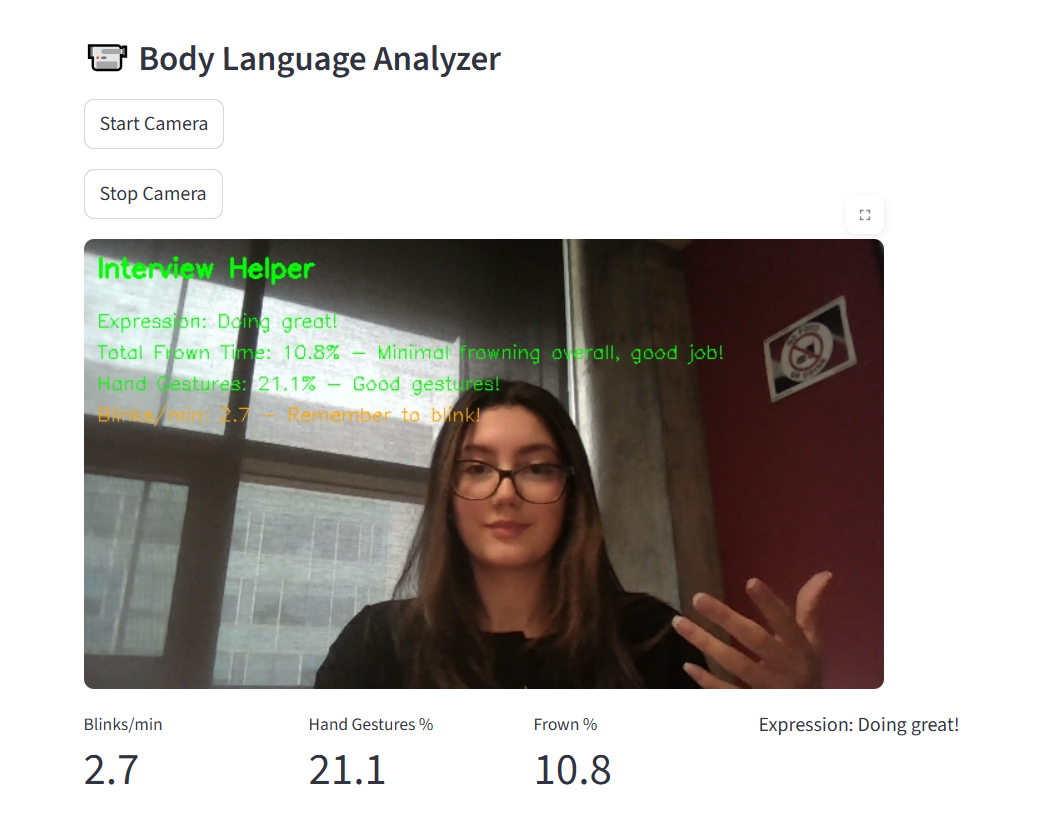
UI SpeakEZ
-
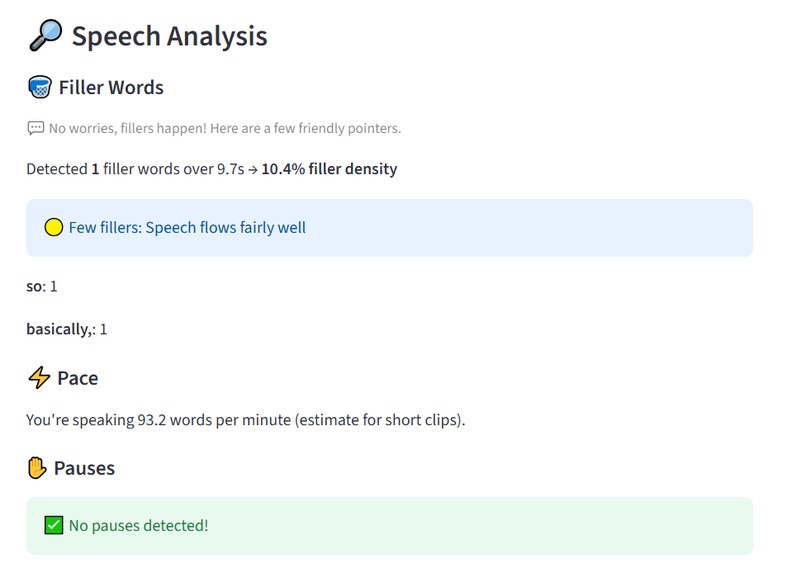
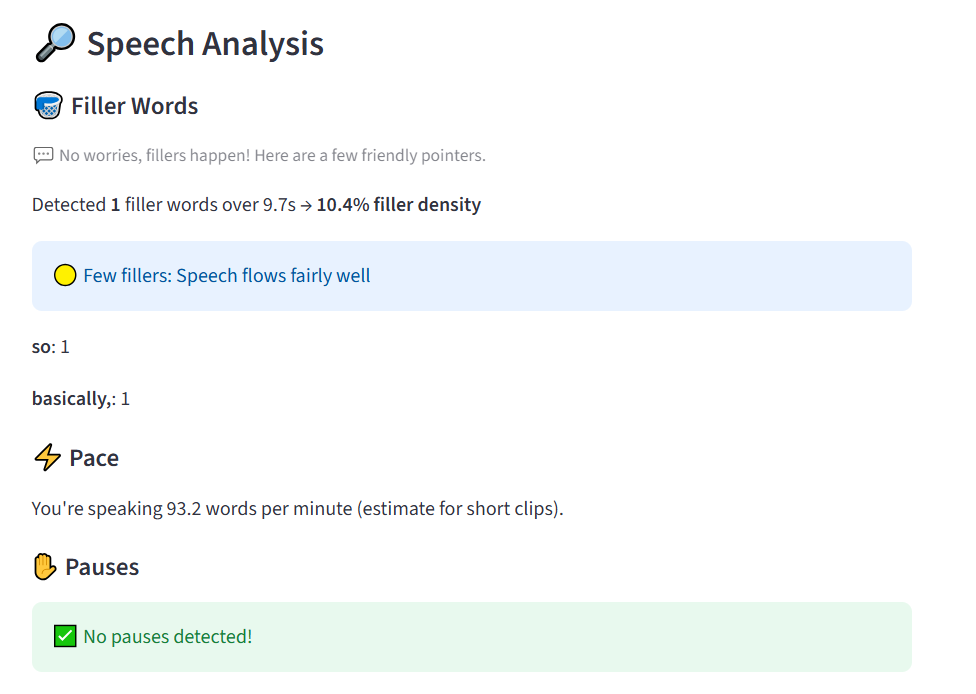
Speech Analysis SpeakEZ

Inspiration
Interviews can be stressful, especially when you feel unprepared or unsure how confident you sound or look. We wanted to build a supportive AI tool that helps people practice speaking naturally by answering real interview questions tailored to their needs, so they can feel confident and prepared for real conversations.
What it does
SpeakEZ is an AI-powered interview coach that analyzes both speech and body language to provide instant, constructive feedback. It detects filler words, evaluates tone and emotion, and assesses visual cues like smiles or hand gestures, giving users clear insights to improve confidence and clarity.
How we built it
- OpenAI Crisper Whisper for speech-to-text and filler word detection.
- Trained a custom Random Forest Classifier on RAVDESS audio data from Kaggle to detect confident (1) vs. nervous (0) tone.
- OpenCV and MediaPipe for gesture and facial expression analysis.
- HR Interview Questions dataset from Kaggle used for random generation according to the user's Experience Level and Question Type preferences.
- Streamlit for the user interface, where users record responses and view instant feedback.
Challenges we ran into
- Speech-to-text accuracy: We first used Vosk for transcription but it couldn’t detect filler words like “um” or “uh,” since they weren’t in its dictionary. We wrote custom code to extract these before switching to a Crisper Whisper variant which was better.
- Body-language tracking: We had to experiment with multiple OpenCV and MediaPipe libraries to measure gestures, blinks, and facial movement, and learned how to integrate Gemini API features for analysis.
- Real-time audio processing: We initially aimed for live feedback during recording, but the audio input was muffled or missing frames, so we pivoted to recording first, then analyzing post-response.
- Model integration: We learned how to train our own confidence-detection model and successfully connect it with other components inside Streamlit.
Accomplishments that we're proud of
- Integrating all components into one functional Streamlit app
- Successfully trained a confidence detection model with good accuracy using real speech data
- Built a working Streamlit app that gives instant, multimodal interview feedback
- Collaborated effectively under time constraints
What we learned
- How to record, process, and analyze audio and video data
- How to fine-tune OpenCV and MediaPipe for gesture and facial recognition
- How to preprocess and extract features from audio data using Librosa
- How Random Forests can interpret emotional tone through audio features
- How to connect multiple ML components within an interactive Streamlit UI
What's next for SpeakEZ
- Working on real-time microphone input and feedback to truly simulate the interview experience
- Ethical AI & privacy: secure user accounts, transparent feedback, and responsible data use
- Adding personalized progress tracking and goal suggestions, multilingual and accessibility support for inclusive communication
- Increasing accuracy with more data for the confidence model and more movements in OpenCV










Log in or sign up for Devpost to join the conversation.