Inspiration
Public speaking can be intimidating, especially when addressing judges or an audience in high-pressure situations. We were inspired to create SpeakEasy because we personally struggled with speaking confidently in such settings. Our goal was to develop a tool that helps individuals improve their speech delivery by providing real-time feedback on body language and speech patterns.
What it does
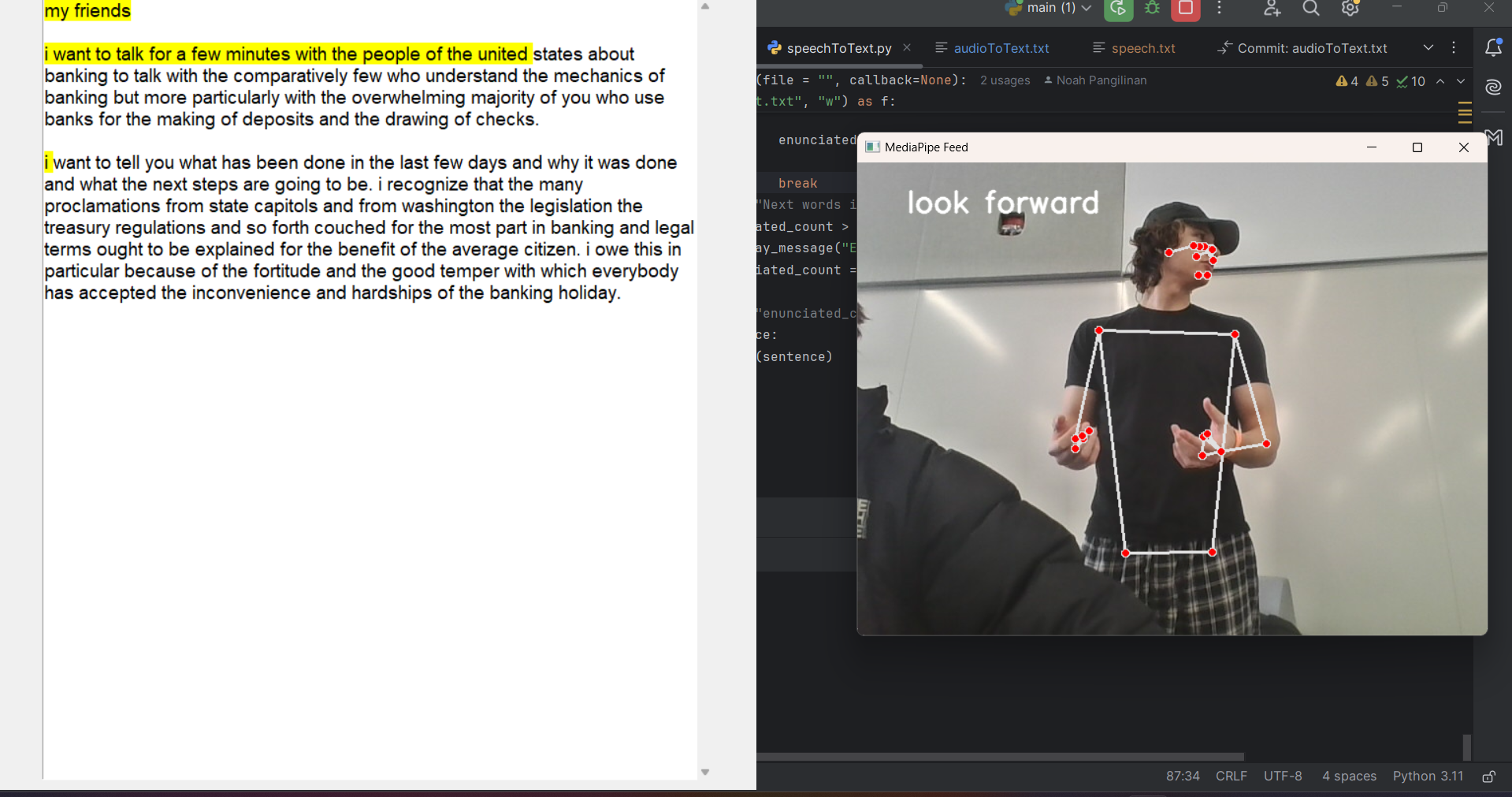
SpeakEasy is an AI-powered public speaking assistant that analyzes both audio and body language to provide users with real-time feedback on their performance. Using VOSK for speech recognition and MediaPipe for body language tracking.
How we built it
We built SpeakEasy using:
VOSK for real-time speech-to-text conversion and analysis of speech patterns.
MediaPipe for body language tracking and gesture recognition.
Python and Tkinter for the graphical interface and real-time visualization.
Threading and optimized calculations to ensure smooth performance while analyzing multiple inputs simultaneously.
Challenges we ran into
One of the biggest challenges we faced was efficiently processing audio and video data in real-time. Performing calculations on every frame while ensuring smooth performance required optimizing our code and balancing system resources. We also encountered difficulties in synchronizing speech analysis with body language tracking to provide cohesive feedback. Debugging and refining our highlight functionality for tracking speech within the text was another major hurdle.
Whats next for SpeakEasy
We plan to enhance SpeakEasy by:
Improving the AI feedback system with deeper speech and gesture analysis.
Adding more detailed metrics, such as filler word detection and tone analysis.
Developing a mobile version for more accessibility.
Expanding language support to help speakers in multiple languages.
Refining the interface to provide even more intuitive feedback and visualizations.

Log in or sign up for Devpost to join the conversation.