-
-
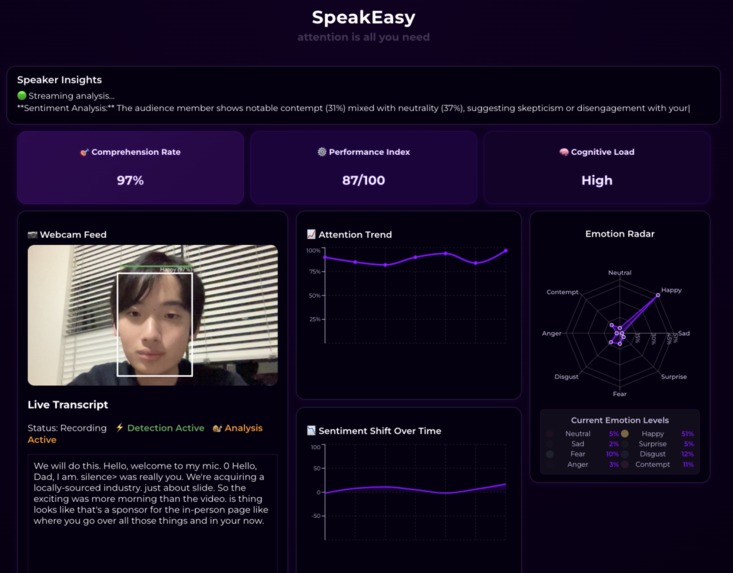
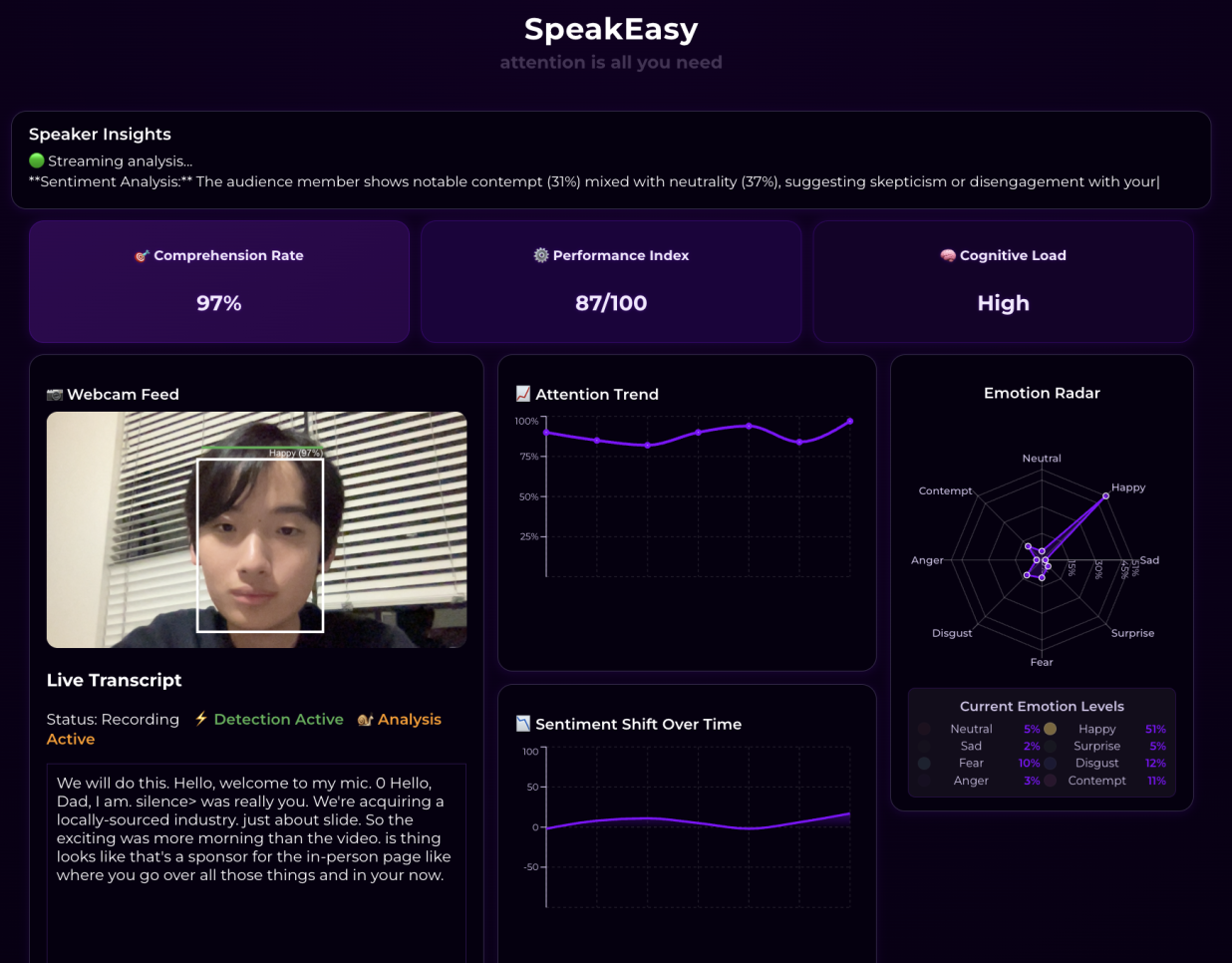
analytics dashboard
-
-
As college students, we’ve all been to lectures where the professor doesn’t realize their audience is completely lost, where we leave the building with more questions than answers and feel confused and frustrated.
Similarly in professional settings, the brightest ideas can be undermined by subpar pitches and unclear explanations. The result of such scenarios are missed opportunities to close deals and students who gain little to nothing from lectures.
Attention drives impact; commanding it is a difficult skill. Whether you’re doing a simple project presentation for a class or hosting a Ted Talk, you need to read visual cues from the audience and respond in real time to effectively engage your listeners. Dynamically adjusting tone, phrasing, and content on the fly is a crucial yet formidable skill to obtain, and even the most skilled speakers often struggle to address the audience in its entirety.
Such struggles motivated us to build SpeakEasy, an AI agent that gives you detailed audience analytics and live feedback based on reactions while you speak, so you can give more engaging and responsive presentations.
What it does
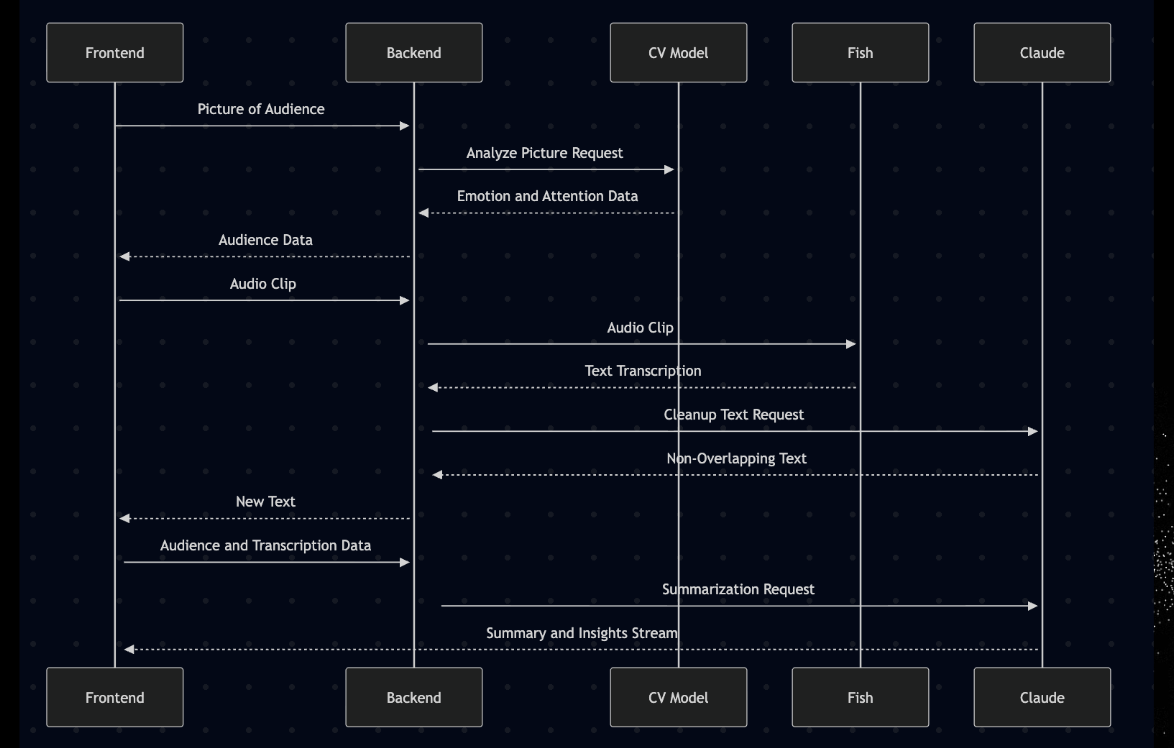
SpeakEasy is an AI agent that gives you detailed analytics and actionable insights into how engaged your audience is. Using computer vision, the webcam feature continuously analyzes each audience member’s emotional state and attention level through sentiment analysis and gaze detection. Simultaneously, our platform is capable of live transcription of the speaker’s words through Fish Audio, providing valuable context when giving speaker insights. Live sentiment analysis and transcription data is then integrated through a Claude-based agent that informs you which people seem confused, which parts of your speech were poorly received, and what you can do to regain your audience’s attention. A multitude of analytics present further fruitful information regarding the presenter’s performance and the crowd’s reaction over time.
How we built it
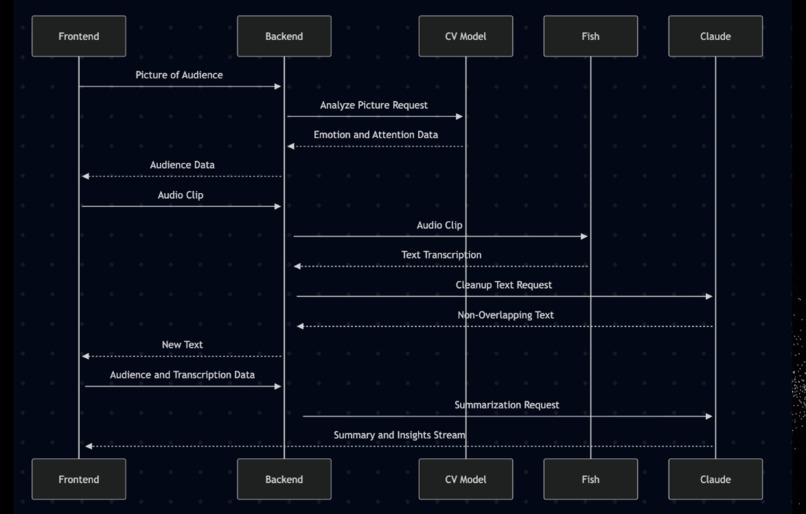
SpeakEasy is built on a FastAPI backend and React frontend that processes real-time video and audio streams through a dual-pipeline architecture.
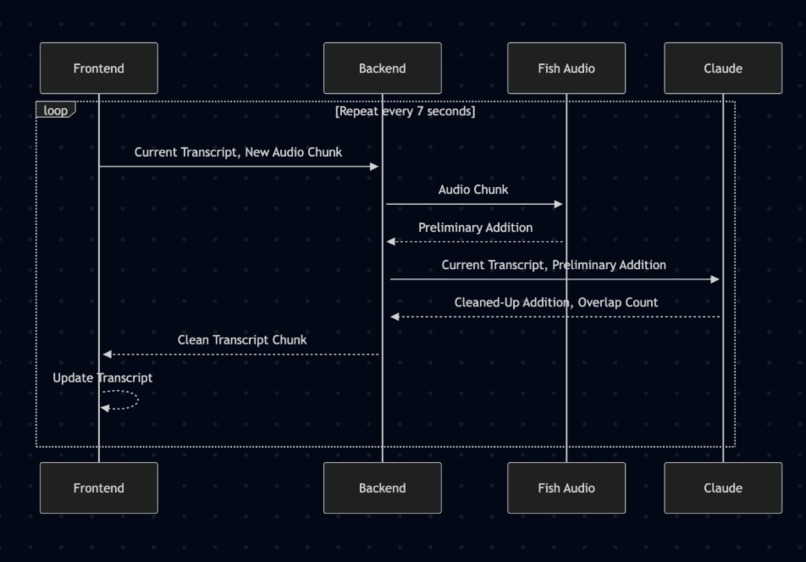
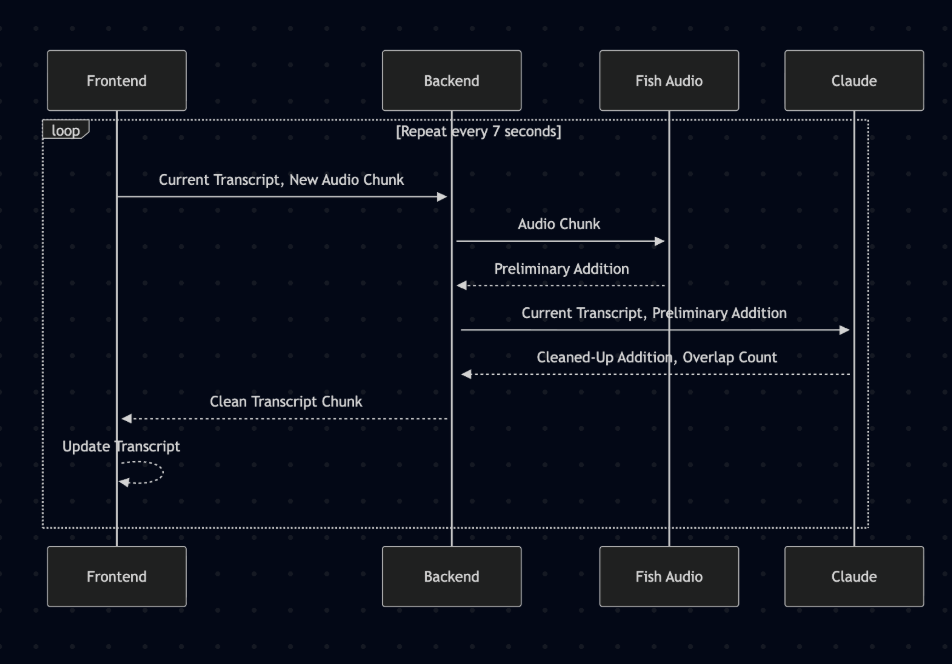
The core of our speech processing relies on Fish Audio's advanced ASR system, which provides high-accuracy and low-latency speech-to-text transcription with overlapping audio chunks to ensure no words are missed. Fish Audio handles the complex task of converting continuous speech into text, which is then integrated into our custom post-processing AI pipeline that refines the transcripts for accuracy and coherence while removing overlapping words.
The visual analysis pipeline uses OpenFace integrated with RetinaFace for face detection and a multitask learning model for emotion and gaze analysis. We implemented a dual-speed processing system that provides fast face detection every 200ms and detailed facial emotion analysis every 7 seconds.
Gaze analysis and emotion analysis are implemented by augmenting the model with linear heads to extract gaze and classify a probability distribution over 8 emotions. But what does it mean for people to be attending to something else? Since we have a head in our model that outputs gaze, defined by a yaw and a pitch, we can compute a unit vector that represents the direction of a person’s gaze.
Then, we can define a region of attention that represents what people should be attending to. In the case of SpeakEasy, the region of attention would be defined as the speaker, or a slideshow that he would be utilizing. Then, we can compute a unit vector that represents the direction from the person’s eyes to this region of attention. We can then take the cosine similarity between their gaze vector and the “true” vector, and scale this to [0, 1] to acquire a probability metric for attention.
At the end, Claude AI analyzes the combined audio transcripts and visual data to generate real-time presenter recommendations, all streamed directly to the dashboard via SSE.
Challenges we ran into
At first, Fish Audio’s transcription was missing spoken words because of small delays between the audio chunks we sent to it. In addition, the output was muddled by external noises that were causing the transcription to become inaccurate and incoherent. We solved this by including overlap between audio chunks that were passed into Fish Audio. The output would then go through a Claude-based post-processing layer to clean and assess coherence before displaying to the user, removing words that were recorded in the previous chunk as well as filler words and noise.
One challenge was being able to accurately and efficiently capture the sentiment and attention scores for each individual person detected in frame. Sentiment and attention are inherently complex attributes, making accurate detection quite difficult. However, we came up with a two step approach to handling both the efficiency bottlenecks and the accuracy issues:
In the first stage, we would rapidly run a large scale one-shot bounding box detection model for all the faces in frame. By running this algorithm independently of sentiment analysis and attention, we would be able to report bounding box detection much more seamlessly to the front end.
Then, once we had acquired the bounding boxes, we would crop the image to each individual face based on the predicted bounding boxes, and then feed that image into the model once again utilizing linear layers after a convolutional net to project sentiments and gaze, thereby allowing the model to analyze only one face at a time to produce more accurate results.
Another challenge was with the overall architecture of the project. We initially had a single large API route in the backend that would call Fish Audio, the computer vision model, and Claude all in the same place.
However, the latency this resulted in made SpeakEasy effectively useless, and we wanted different components of the dashboard to be able to update independently.
To fix this, we restructured the platform to have most of the logic on the frontend and split up the backend into several smaller API routes. When called on, each route replies with raw data, which is then filtered and displayed appropriately by each React component.
Accomplishments that we're proud of
Overall, we are incredibly proud of our final project, as we built a working multimodal, real-time system that unites computer vision, audio transcription, and language modeling into one cohesive pipeline.
Throughout the process of creating SpeakEasy, architecting the flow was one of the most difficult yet rewarding parts. With multiple moving parts, designing the system to integrate everything coherently was essential in realizing our vision for the platform.
We also take pride in the level of polish we achieved on both the frontend and backend. From designing an intuitive dashboard that visualizes real-time audience engagement to fine-tuning Fish Audio’s transcription pipeline and integrating Claude’s contextual reasoning, every piece was built with user experience and performance in mind.
Of course, none of this would’ve been possible without our teamwork and adaptability. We applaud ourselves for actively communicating our ideas, progress, and needs, as doing so has been crucial to our efficacy.
What we learned
We learned a lot about processing multimodal inputs through agentic workflows. LLMs are extremely powerful, but they still have core limitations that prevent them from being able to fully one-shot platforms with features as complex and intricate as SpeakEasy.
Throughout the hackathon, we operated with a philosophy that treats LLMs as a tool to be used rather than a black box to be thrown at everything. We integrated them in various parts of Speakeasy but maintained a strong non-LLM fundamental structure throughout.
What's next for SpeakEasy
We’d like to refine our algorithms and analytics to be more accurate by integrating data like intonation and other vocal cues to give more comprehensive feedback for the presenter. With dual-facing cameras, we could also give feedback on body language and hand gestures, significantly enhancing speakers’ stage presence. Moreover, we currently have analytics algorithms running in our CV end, which allows us to visualize heat maps and Voronoi diagrams over emotion and attention distributions in the audience which we plan to integrate with the front end to provide speakers with more comprehensible data.
Currently, the speaker receives feedback from observing the screen’s streamed advice, which may distract them and decrease the quality of their presentation. With Fish Audio’s text-to-speech capabilities, we can connect our current platform to earbuds so that the speaker can privately listen to recommendations.
Additionally, Fish Audio’s distinct emotion control in voice generation inspires us. We envision SpeakEasy to include a feature that directs your emotions by showing first-hand what you would and should sound like in order to hype up the crowd or command the audience, which is decided in response to overall attention and confusion in the audience.




Log in or sign up for Devpost to join the conversation.