-
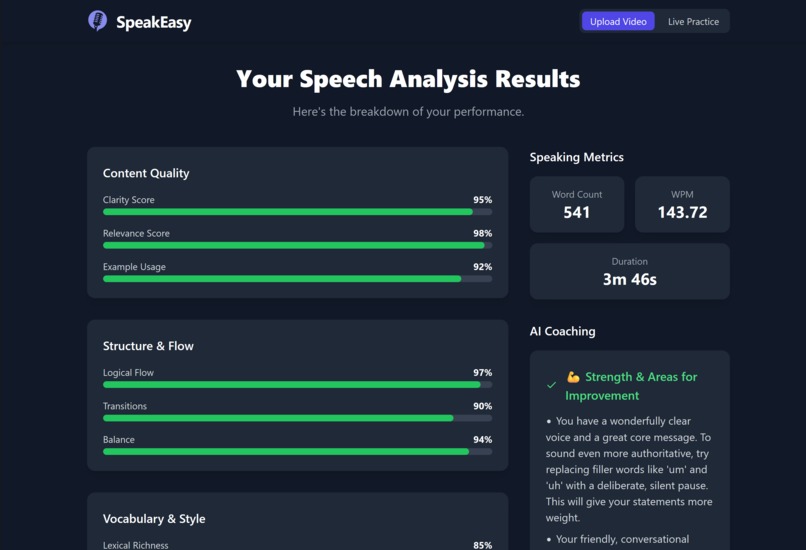
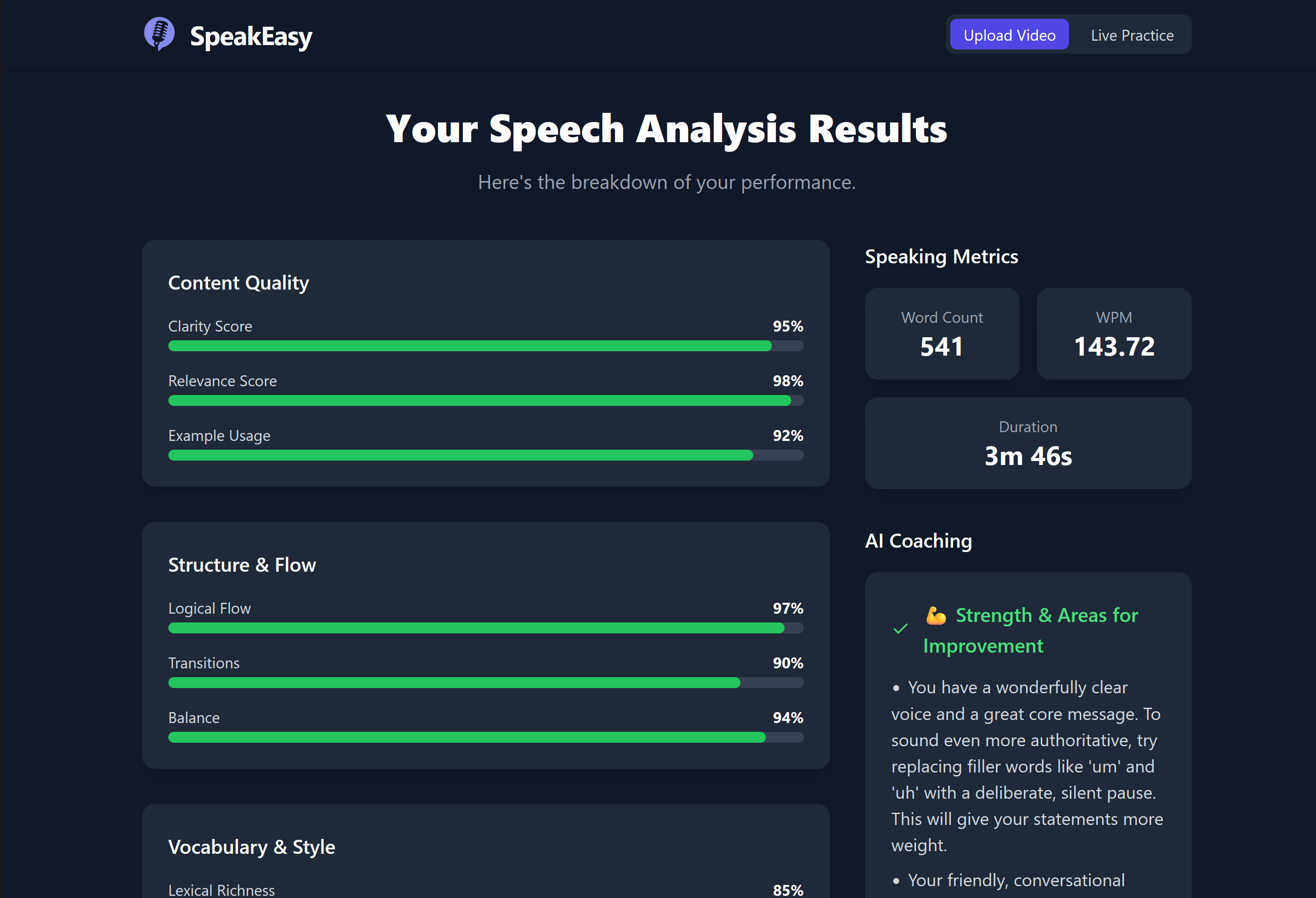
The results after analyzing a TEDtalk.
-
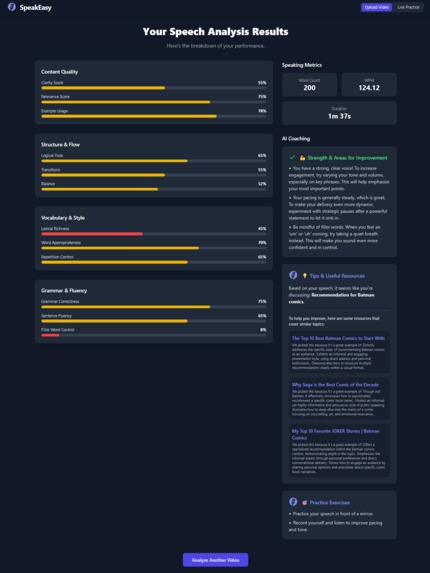
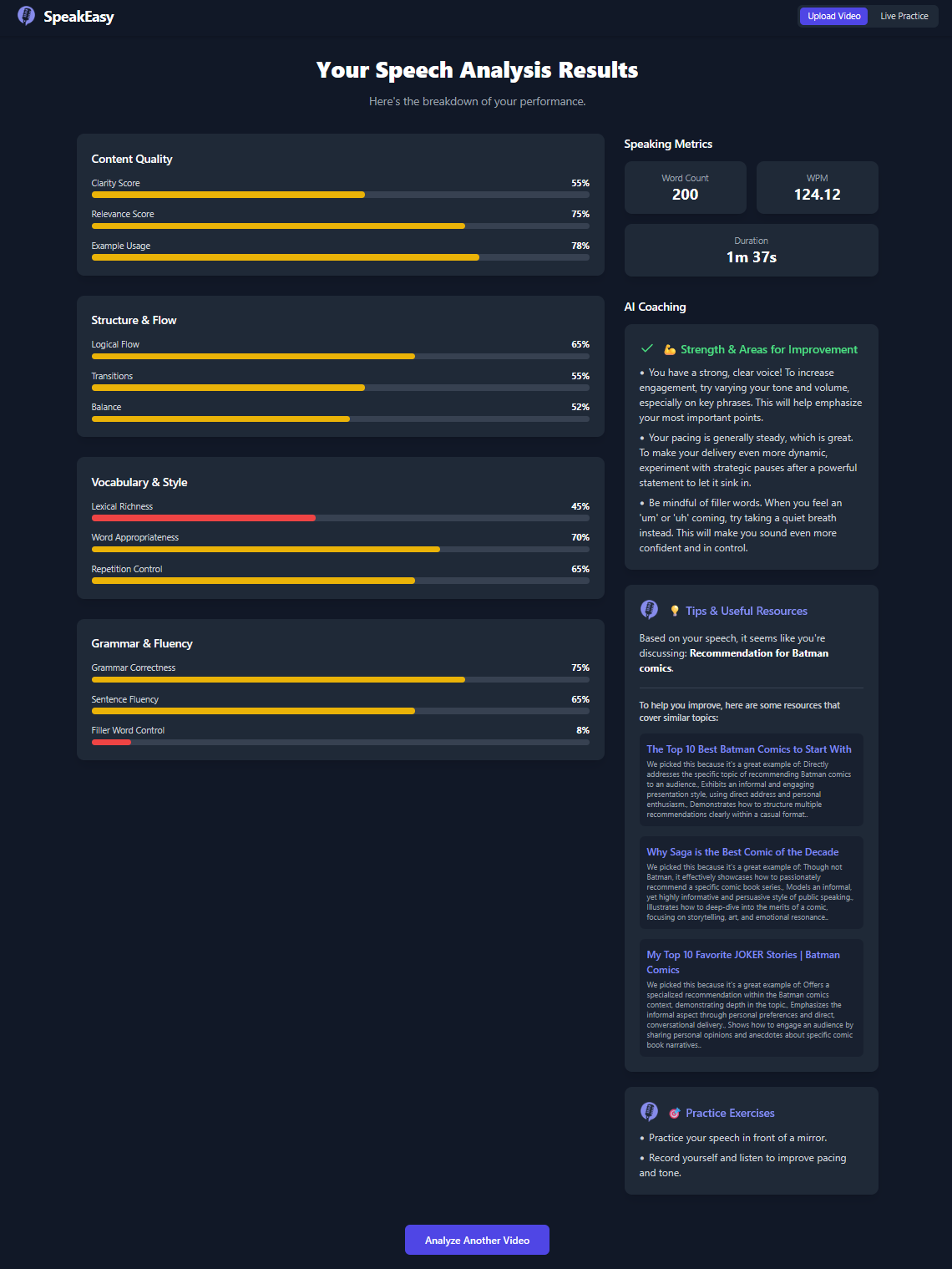
These are the full results of submitting a mediocre ramble about my favorite Batman comics. The resources are all clickable links.
-
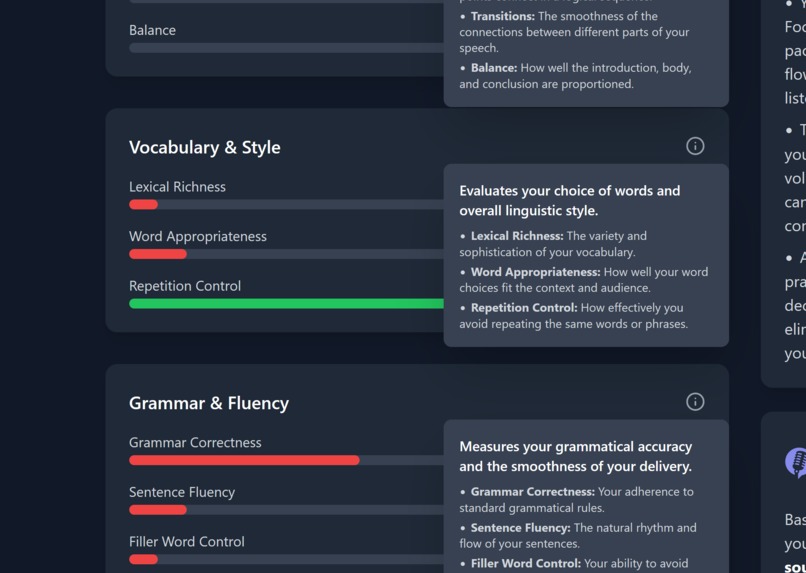
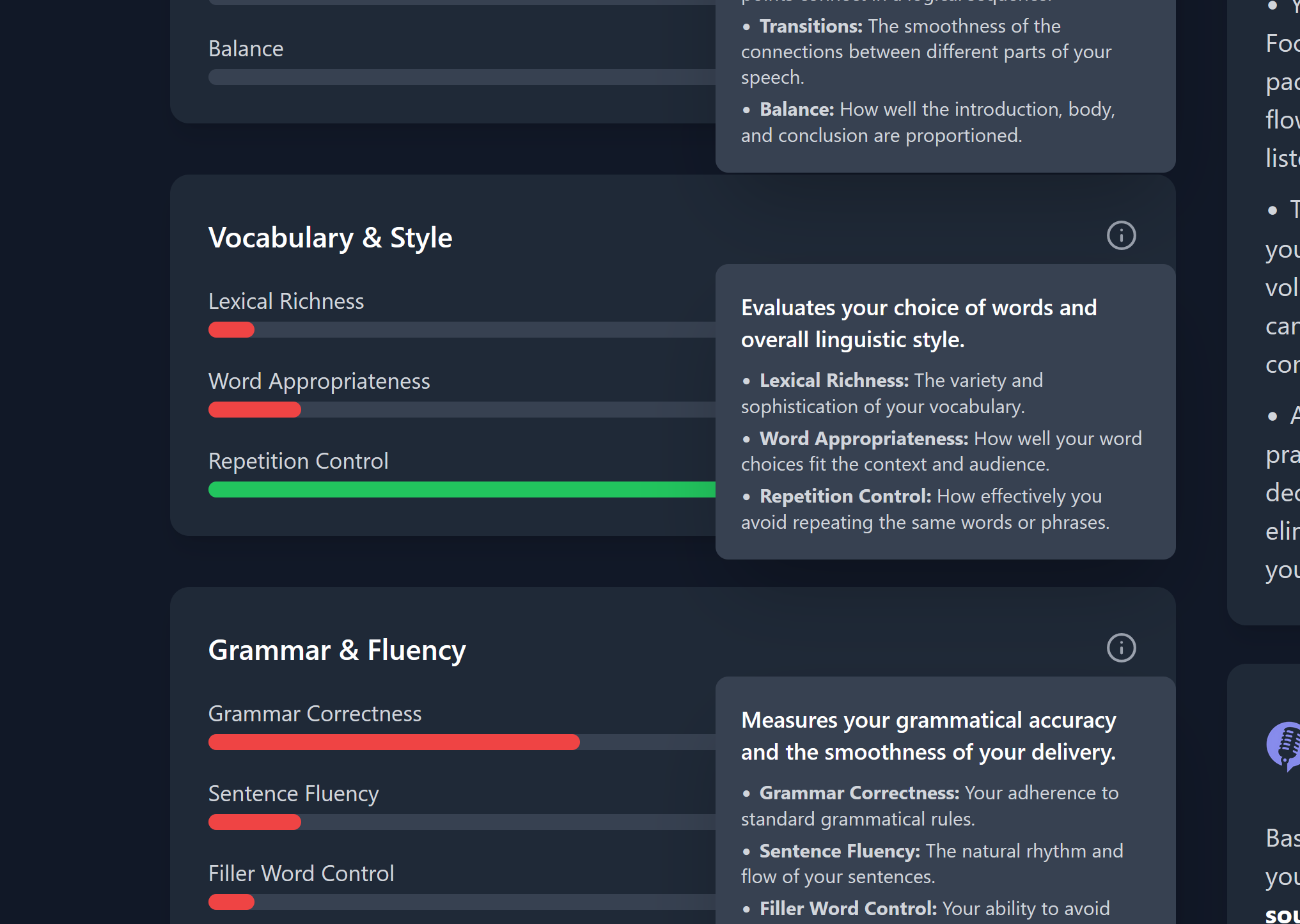
If you're confused about any metric, don't sweat! Click the information button for a helpful breakdown of each category.
-
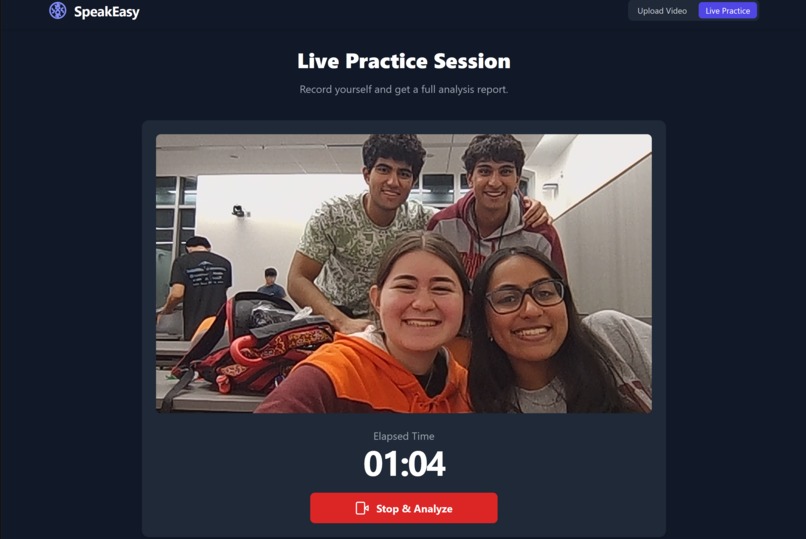
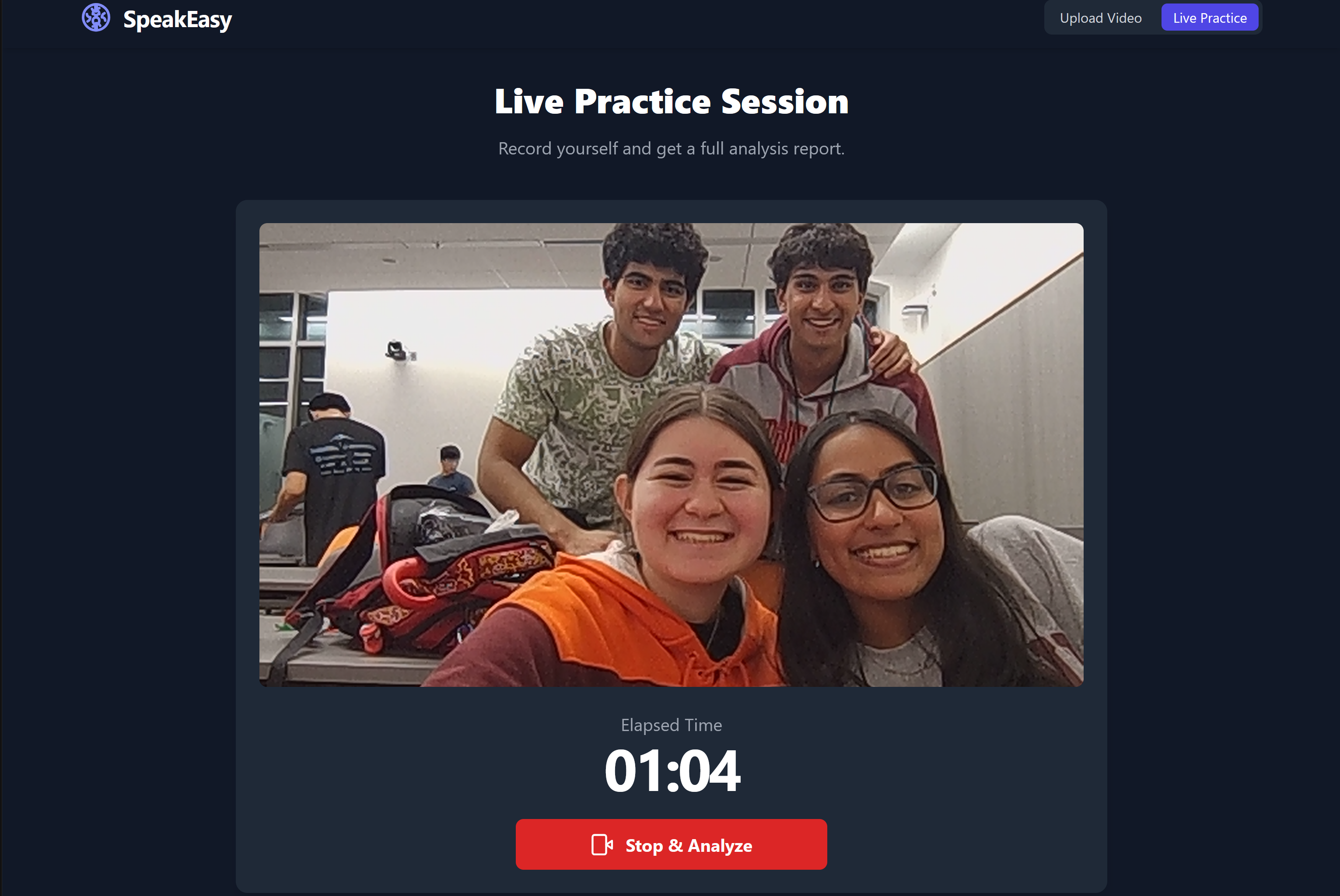
Meet the team! This is the live video practice mode.
-
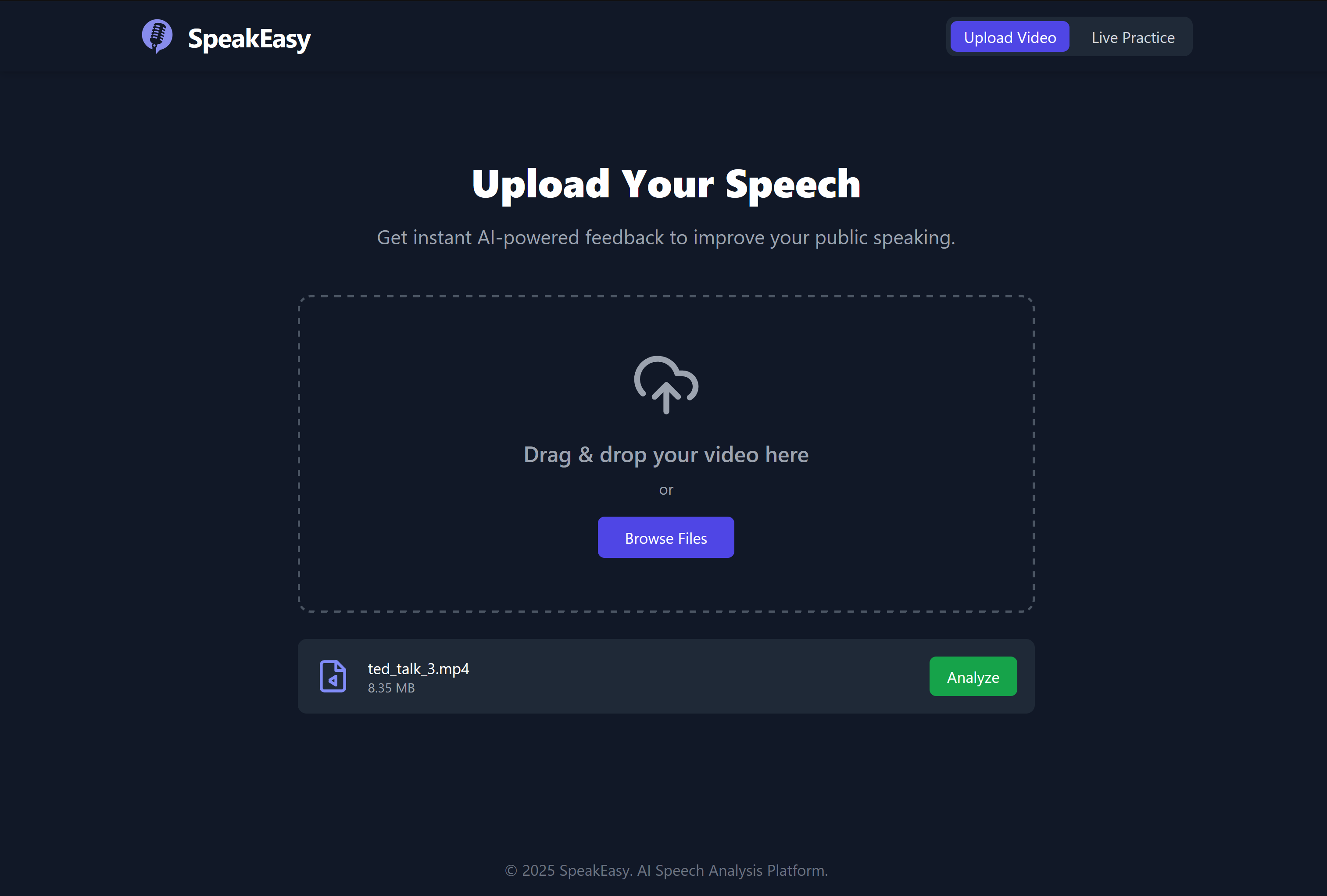
Video uploading interface.
-
Analyzing a submitted video.
"SpeakEasy-- it shouldn't be hard!"
SpeakEasy is a platform that provides AI-driven feedback to help anyone improve their public speaking. It analyzes uploaded or live video and audio to assess clarity, structure, vocabulary, grammar, tone, pacing, and overall delivery. The platform generates actionable insights, highlights strengths, and suggests targeted practice exercises, making it especially helpful for non-native speakers, neurodivergent individuals, or anyone facing communication barriers.
Inspiration
Public speaking remains one of the most common sources of anxiety, and access to personalized coaching is especially limited for non-native speakers and neurodivergent individuals. Traditional methods (classes, workshops, or generic AI chatbots) often overlook the unique challenges these groups face, such as language fluency, nuanced pronunciation, processing differences, or sensory and cognitive load. Without tailored guidance, speakers can struggle to understand how to improve pacing, clarity, tone, or structure in ways that work for their specific needs.
This platform addresses these gaps by providing structured, multimodal feedback that considers each speaker’s unique profile. It evaluates transcript, audio, and video metrics, offering concrete, actionable insights on clarity, grammar, vocabulary, rhythm, and delivery style. Users receive personalized examples, targeted exercises, and encouragement that support meaningful progress, making public speaking more accessible, effective, and confidence-building for those who are often underserved by traditional coaching approaches.
The system measures a wide variety of transcript, audio, and video metrics, including:
- Transcript & content: clarity, relevance, logical flow, transitions, and structure.
- Vocabulary & style: lexical richness, word appropriateness, repetition metrics.
- Fluency & grammar: grammar correctness, sentence fluency, and filler-word density (with timestamps).
- Length & pacing: word count, words-per-minute, and normalized length score.
- Audio/video delivery: clarity, pronunciation, tone, pacing, and engagement.
- Rhetoric & impact: rhetorical devices, call-to-action strength, and emotional valence.
These metrics feed the program’s recommendations and the aggregated overall score used to prioritize practice tasks.
What it does
SpeakEasy turns a short uploaded talk into an actionable coaching session:
- Audio → text: Extracts audio from video with
ffmpegand transcribes it with Whisper. - Text analysis: Gemini infers context (specific topic, general theme, format), retrieves three relevant public-speaking examples, and grades the transcript across clarity, structure, vocabulary, grammar, and rhetoric.
- Audio analysis: Gemini generates 5–7 targeted keywords; YouTube Data API fetches short reference talks;
yt_dlpdownloads audio; Gemini compares user audio to references on clarity, pronunciation, pacing, tone, and filler words. - Multimodal coaching: The user’s video and audio are uploaded to Gemini, which generates a structured, empathetic report highlighting strengths, targeted improvements, and 1–3 short practice tasks.
The backend returns a structured JSON result: transcript, scores, context, examples, and coach feedback — explicitly tailored for ESL and neurodivergent learners.
How we built it
- Frontend: React (Create React App), Tailwind for styling.
- Backend: Python + Flask API (
/api/analyze,/api/health). - Media processing:
ffmpeg,moviepy,librosa,pydub. - Transcription: Whisper (
openai-whisperwith PyTorch). Model integration:
google-generativeai(Gemini) with three main modules:TextEncoder: context extraction, transcript grading, example retrieval.AudioEncoder: keyword generation, YouTube search/downloads, audio grading.Coach: multimodal feedback combining video, audio, and transcript.
Search & retrieval: YouTube Data API (search + videos endpoints) +
yt_dlp.
Gemini workflow (per /api/analyze request)
- Extract context → JSON
{specific_topic, general_topic, format}. - Grade transcript → JSON scores (0–1 for clarity, structure, vocabulary, grammar, rhetoric).
- Generate keywords → 5–7 precise search queries for YouTube API.
- Retrieve examples → 3 JSON objects
{title, summary, url, relevance}. - Grade audio → JSON rubric for clarity, pronunciation, pacing, tone, fillers.
- Coach feedback → Upload video/audio with
genai.upload_file(), call multimodal Gemini, delete uploads afterward.
Each analysis typically involves ~6 Gemini generate_content calls + 2 uploads + 2 deletes.
All prompts enforce strict JSON schemas, with fence-stripping and fallback parsing for stability.
Challenges
- Prompt brittleness: solved with schema-based JSON prompts and safe parsing.
- Privacy: uploading video/audio raises consent issues → added local-only fallback option.
- Cost & rate limits: mitigated by caching, smaller models for lightweight tasks, and graceful degradation.
- Noisy/low-volume inputs: pre-flight checks degrade gracefully to text-only analysis.
- Testing multimodal flows: solved by mocking
google.generativeaiin CI.
Accomplishments
- Built a complete multimodal coaching pipeline (video + audio + transcript).
- Designed robust JSON-first prompts + parsing to stabilize LLM integration.
- Hybrid retrieval: Gemini for semantic search, YouTube API for deterministic metadata,
yt_dlpfor reproducible reference sets. - Testable architecture — offline mocks for Gemini make unit/CI tests reliable.
- UX-first outputs: concise, encouraging, scaffolded feedback instead of generic critique.
What’s next
- Account support: the ability to log in and see past uploads.
- Privacy-first mode: full local analysis without uploads.
- Caching + throttling: to reduce cost and API strain.
- Progress tracking: save history, visualize growth over time, along with the ability to compare various iterations of the same speech.
- Multilingual/localized prompts: expand to more languages for further reach, more comprehensive assistance to non-native English speakers.
- Timestamped practice clips: embed short annotated exercises inside feedback.
Built With
- ai
- autoprefixer
- conda
- cpython-3.10
- craco
- css
- ffmpeg-(cli)
- ffmpeg-python
- ffmpeg-system-dependency
- flask
- flask-cors
- flask-rest-api-endpoints
- gemini
- gemini)
- generative
- google-generativeai-(google-generative-ai-/-gemini)
- html
- hugging-face-transformers
- isodate
- javascript
- json
- librosa
- libsndfile
- moviepy
- node.js
- npm
- numpy
- opencv-(cv2)
- pandas
- pip
- portaudio
- postcss
- pyaudio
- pydub
- python
- python-dotenv
- pytorch-(torch)
- pytorchvideo
- react
- react-scripts
- regex
- scikit-learn
- soundfile
- tailwind-css
- testing-library/jest-dom
- testing-library/react
- testing-library/user-event
- torchaudio
- torchvision
- tqdm
- web-vitals
- whisper-(openai-whisper-/-whisper)
- yt-dlp







Log in or sign up for Devpost to join the conversation.