-
-

Home Page
-
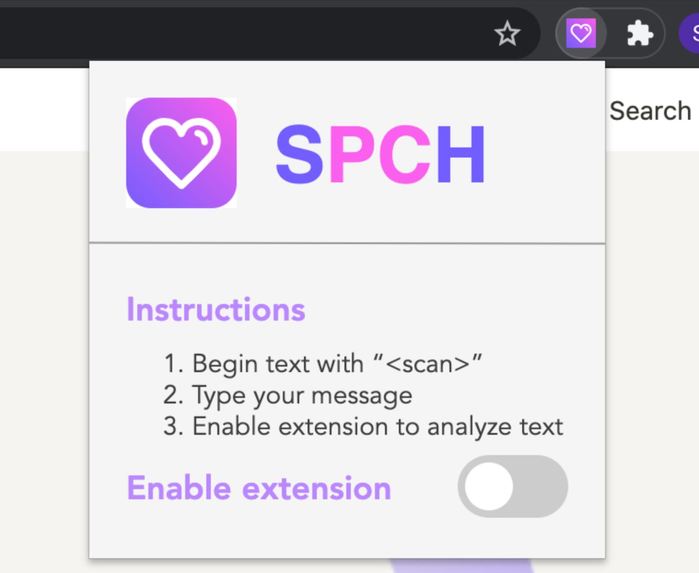
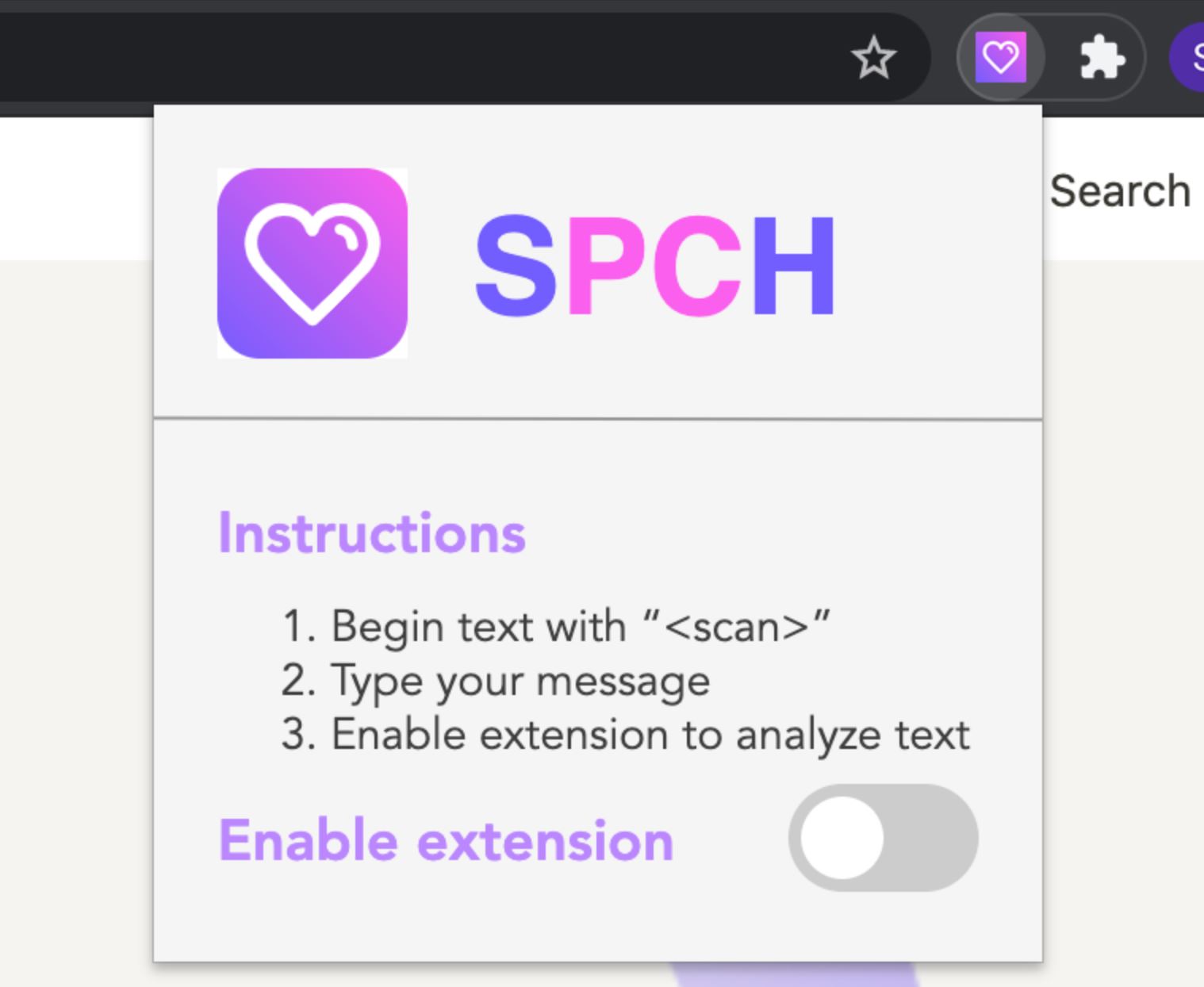
Chrome Extension
-

Text Editor Detection Example
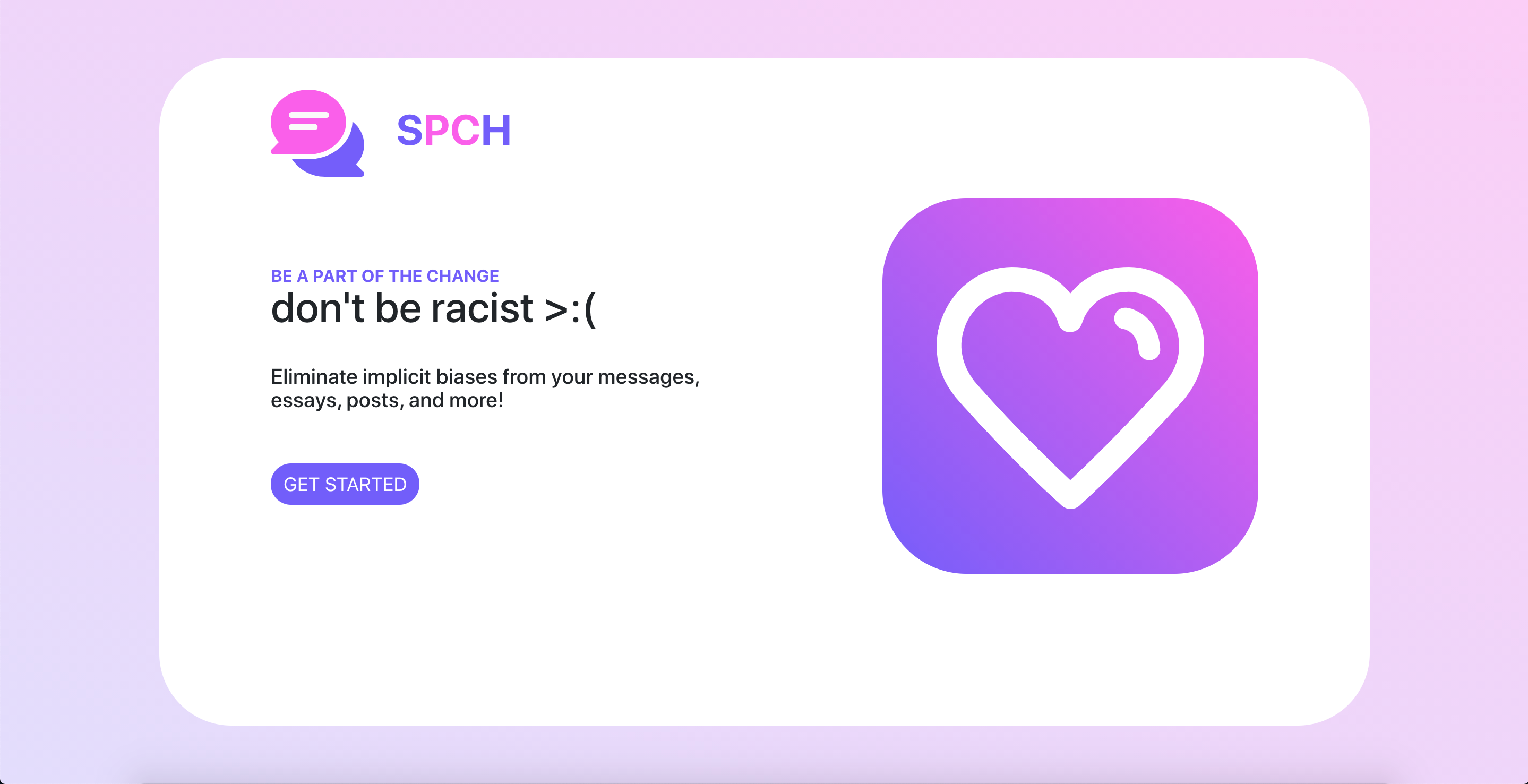

Inequality Track
Inspiration
One of our team members read an article detailing the uptick of hate speech and other offensive language on the internet in the past four years. In the technology-driven society that we live in, the internet has a massive reach of influence, and is accessible to many different types of people across the world. Hate speech and offensive language threaten the fundamental safety and rights of marginalized people, and thus can turn people away from the technologies that drive our society. Moreover, they perpetuate inequalities that exist in our society. To help fix these issues, we developed SPCH.
What it does
Our project “SPCH” involves a text editor and Google Chrome extension that scans for hate speech and offensive language within a block of text. By entering a block of text, users can identify language that they may want to consider replacing before publishing it as a Tweet, Facebook post, or anywhere else! It also identifies more subtle and underlying implicit biases that users may not be able to immediately recognize.
How I built it
The model used for the backend is from Data for Democracy’s Hate Speech Detector: https://github.com/Data4Democracy/hate_speech_detector. This model is trained on 25k tweets containing keywords from HateBase to create a model that differentiates between hate speech and non-hate speech offensive language. Datastax Astra functionality was added for storing user input: once the model predicts a score for user data, the score is saved to the database to be manually validated and added to the training data. This will allow the model to improve over time.
The frontend of our website and Google Chrome extension were built using React. We used React hooks to manage state and create functional components. React-router was also used to create a multi-page app.
We used Firebase to deploy the frontend because of its ease of use and flexibility. Docker + Google Cloud Run was used for deploying the model for its automatic scalability and
The UI design of the front end for both the website and Google Chrome extension was made within Sketch. We maintained a very minimalistic approach to both designs, as we wanted to keep our solution easy to understand and accessible to all users.
Challenges I ran into
The first model we worked with was written in Python 2.7, which created several headaches for us. First, the most recent versions installed by pip created compatibility issues, so we had to make sure that each library was the version used by the research team. Also, hosting the endpoint did not work because Heroku did not support the specific version of pip that was required to download data from the nltk library. Therefore, we had to find another implementation.
The second model was updated to Python 3.5, which is much more compatible. However, there were still issues with the nltk library that needed to be modified in the model code. This model trains when it is being deployed, so Heroku did not have enough power to host. Therefore, we used Google Cloud Run because it has a powerful Build service.
Accomplishments that I'm proud of
When beginning this hackathon, many of us were very unfamiliar with Machine Learning. We are very proud of being able to understand how to implement a Machine Learning model with a React.js web application. Furthermore, developing a Google Chrome extension using React was a new challenge for our team, and we felt very accomplished being to integrate it with our Machine Learning model. Lastly, we decided to design a beautiful and clean user interface to ensure that our project would be easy to understand and accessible to everyone. This is one of our very steps into UI/UX design, and we are very proud of being able to wireframe, design, and implement our design within 24 hours.
What I learned
Throughout this hackathon, we learned how to implement a Machine Learning model with our frontend, as well as how to develop a Google Chrome extension. We also learned how to design a UI and integrate each element with our frontend. One of the softer skills that we were newly exposed to through HackDuke was working on a project remotely. It was a very interesting experience learning how to communicate solely through calling each other rather than working in person, and we look forward to seeing how we can further improve our communication in future virtual hackathons.
What's next for SPCH
In the future, we plan to expand SPCH by developing more features that would increase its net of use-cases. One example of this would be to develop a voice-to-text mobile application, which would allow users to simply talk into their phone’s microphone and detect underlying hate speech. Another effective expansion would be the gamification of the training of the model. This would include a crowdsourced game that creates training data where users can help recognize and mark offensive language and hate speech. To further improve our ML model, we plan to have an automatic pipeline for new data, which would help route new text entries to our model to help further train it.
Domain.com submissions: dontberacist.online mylaptopisoutof.space


Log in or sign up for Devpost to join the conversation.