-
-

Gaussian Splat Scene
-
Homepage
-

dashboard demo page

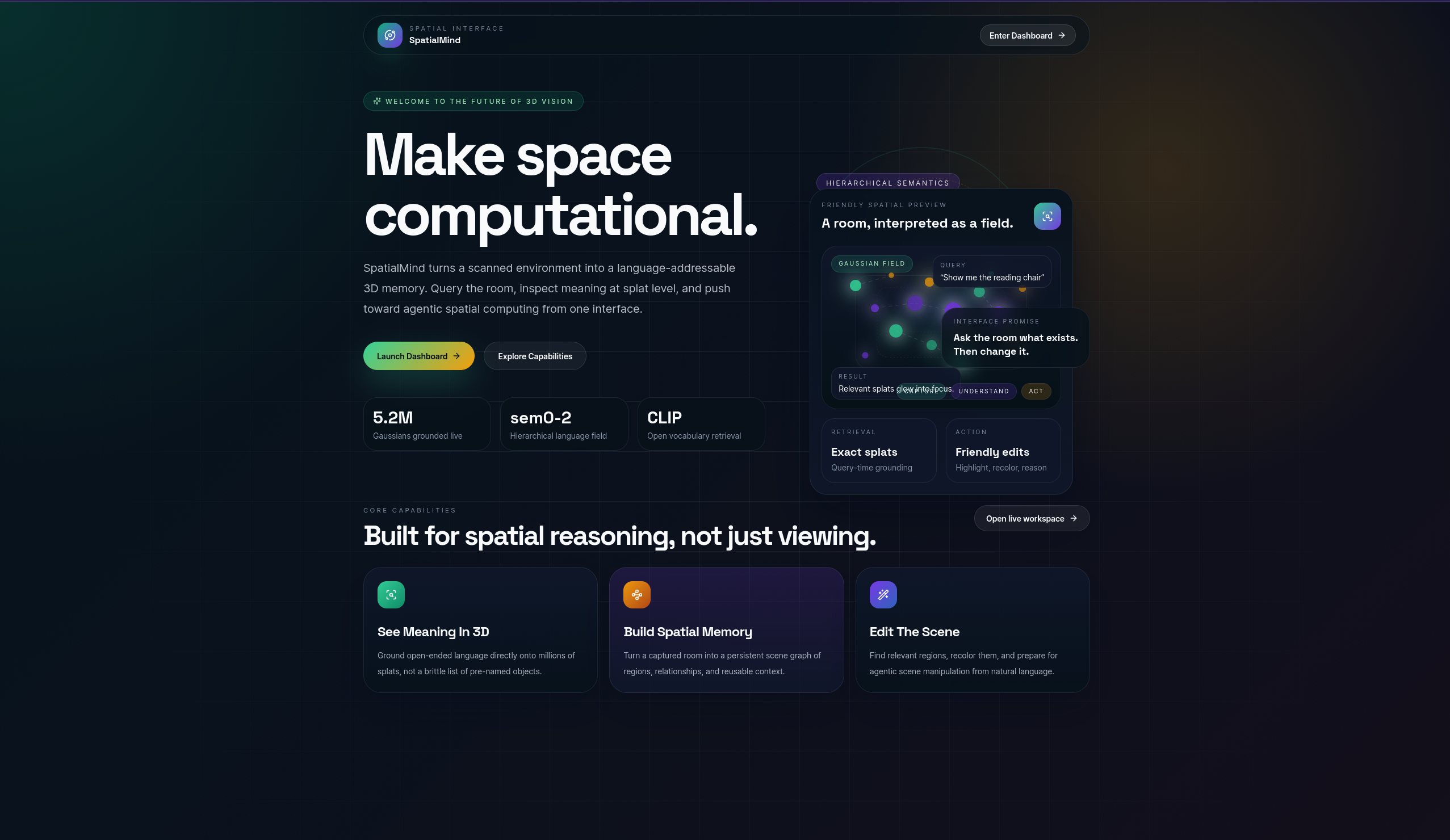

Inspiration
We asked a simple question: what if you could talk to a 3D scene? Not just view it — query it. "What's on the table?" and watch the answer light up. "Change the couch to red" and
see it happen in real time. Current 3D reconstruction gives you photorealistic visuals but zero understanding — every Gaussian knows its color, but nothing about what it is. We
wanted to bridge that gap: give every splat a semantic identity and make the entire scene queryable as a spatial knowledge graph.
What it does
SpatialMind is a spatial intelligence engine that makes 3D Gaussian Splat scenes queryable with natural language. Record a video on your phone with Scaniverse, and our pipeline
reconstructs it as a semantic 3D scene where every Gaussian knows what it represents. Type "what's next to the bookshelf?" and matching objects light up in a photorealistic 3D
viewport while an agentic walker traverses a spatial knowledge graph to return a fluent answer with spatial relationships. Say "change his hair to blue" and the matched Gaussians
recolor instantly. Three semantic levels let you drill from whole objects ("chair") to parts ("armrest") to subparts ("metal screws") — all without ever rendering to 2D.
The system supports multi-step reasoning through a Gemini-powered agent with tool-calling, persistent cross-session memory via Backboard, and a live knowledge graph overlay that
draws spatial relation edges between discovered objects in 3D space.
How we built it
Training pipeline (Colab A100): Video frames → COLMAP camera pose estimation → 3D Gaussian Splatting (91K→500K+ Gaussians) → SAM segmentation at three hierarchy scales → CLIP
encoding → autoencoder compression (512→3 dimensions, ~99.4% reduction) → LangSplat semantic training. This produces three PLY files — one per semantic level — where each Gaussian
carries a 3-dim latent that decodes back to CLIP space.
Runtime server (FastAPI + JAC): Text queries are encoded with OpenCLIP ViT-B/32, decoded through the scene-specific autoencoder, and compared against every Gaussian's learned
embedding via vectorized cosine similarity. DBSCAN clusters high-similarity Gaussians into object candidates without needing to know the object count in advance. Spatial relations
(on_top_of, next_to, inside, left_of) are computed from cluster geometry using SciPy KDTree and convex hulls.
JAC orchestration: Walkers traverse a typed graph where SceneObject nodes hold centroids, bounding boxes, and confidence scores, connected by SpatialRelation and SemanticHierarchy edges. A ChatQuery walker uses by llm() for zero-prompt-engineering intent classification — the function signature is the prompt. Query results persist as graph nodes for cross-query reasoning.
Frontend (React + Three.js + Spark.js): World Labs' Spark.js renderer displays Gaussian splats with per-splat recoloring via the SplatMesh API. A force-directed knowledge graph
mini-view shows discovered objects and their relations. Query responses stream in with reasoning traces, animated object chips, and smooth camera interpolation to points of
interest.
Persistent memory (Backboard): Each scanned scene gets a Backboard thread. Objects discovered in one session are remembered in the next — spatial context accumulates over time
rather than resetting.
Challenges we ran into
CUDA memory overflow in LangSplat's frozen rasterizer. During densification, large Gaussians overflow a fixed-size tile sort buffer. The forward pass handled it gracefully, but the backward pass read past the buffer, crashing with illegal memory access. We traced it to line 415 of rasterizer_impl.cu and solved it by using the official upstream rasterizer for RGB training (which has the fix) and LangSplat's fork only for semantic fine-tuning (which skips densification).
GPU-accelerated COLMAP in headless Colab. Standard COLMAP requires a display server. We solved this with pycolmap-cuda12 for fully headless SfM on Colab's A100.
Checkpoint reconstruction from PLY. After RGB training completed, we needed to resume from a PLY export rather than a full checkpoint. We wrote a reconstruction script that
rebuilds the optimizer state and training parameters from the exported Gaussians.
512-dim per-Gaussian storage. Storing raw CLIP features for 500K+ Gaussians is infeasible (~1GB per level). LangSplat's autoencoder compresses to 3 dimensions with ~99.4% reduction — but the autoencoder is scene-specific, so it must be trained alongside the scene and shipped as an artifact.
Spark.js spherical harmonics conflict. Per-Gaussian recoloring only works with maxSh=0 — spherical harmonics override manual color assignments. Took hours of debugging the
rendering pipeline to discover this one flag.
Accomplishments that we're proud of
- No render-to-2D hack. Every query runs directly in CLIP embedding space against the Gaussian field. No screenshot → VLM → bounding box pipeline. This is genuine 3D understanding.
- Three-level semantic hierarchy. A single scene supports queries from "find the chair" down to "find the metal screws on the armrest" — all from the same trained model.
- JAC-native spatial graph. Spatial relationships are first-class typed edges, not JSON blobs. The knowledge graph is the scene representation.
- Sub-second queries. Vectorized cosine similarity across 100K+ Gaussians + DBSCAN clustering returns results in under a second on CPU.
- Working end-to-end demo. Phone video → trained scene → live 3D viewport → natural language query → highlighted objects with spatial explanations. The whole pipeline works.
What we learned
- Frozen forks accumulate bugs. Always check upstream before debugging for hours — LangSplat's rasterizer bug was fixed in the original repo months ago.
- White and shiny surfaces are invisible to feature matchers. Scene selection matters as much as algorithm choice. Our first scene (a white kitchen) failed completely at SfM.
- The gap between "3D reconstruction" and "3D understanding" is exactly one foundation model pipeline. CLIP embeddings are the bridge — once every Gaussian has a semantic identity,
the rest is graph traversal.
- VGGT (CVPR 2025 Best Paper) can replace COLMAP's entire multi-stage SfM pipeline in under one second — a glimpse of where this field is heading.
- by llm() is underrated. Turning typed function signatures into LLM prompts with zero prompt engineering is exactly what a hackathon needs.
Built with
JAC (Jaseci 2.3.12) · Python · FastAPI · LangSplat · 3D Gaussian Splatting · OpenCLIP · DBSCAN · React · Three.js · Spark.js · Backboard · Google Gemini · COLMAP · SAM · TypeScript · Vite

Log in or sign up for Devpost to join the conversation.