

Inspiration
If you've walked through Purdue's campus, you know the feeling. You sit in a lecture hall with ceiling tiles from the '70s, fluorescent lights buzzing overhead, and chairs that were probably uncomfortable when your parents sat in them. The dorm rooms haven't changed since before we were born. Students submit renovation requests, sign petitions, attend town halls — and by the time anything actually changes, they've already graduated. The next class inherits the same broken radiator and the same conversation about fixing it.
The problem isn't that nobody wants renovations. It's that nobody can show what the renovation would look like — not in a way that creates urgency. A written proposal describing "modernized collaborative study spaces" doesn't move a budget committee. A flat rendering from one angle doesn't capture how a room actually feels. And hiring an architecture firm to produce proper 3D visualizations for every building on campus? That costs tens of thousands per project and takes months.
We kept thinking about this gap. Students can articulate exactly what they want — "replace the carpet with hardwood," "get rid of those ancient desks," "add some actual comfortable furniture" — but there's no fast, cheap way to turn those words into something a decision-maker can walk through and say "yes, fund that."
Then we zoomed out. This isn't just a campus problem. Americans spent $526 billion on home renovations in 2025, and the most expensive part isn't the materials — it's the wrong guess. The remodel that looked great on a mood board but feels wrong in person. Real estate agents spend $2,000–$5,000 staging homes with rented furniture that gets returned in a month. Interior designers lose weeks to revision cycles because clients can't visualize proposals from flat images. The virtual staging market hit $1.33 billion in 2026 — and every product in it outputs a single 2D photo from one angle.
We thought: what if you could just say what you want and walk through it?
What it does
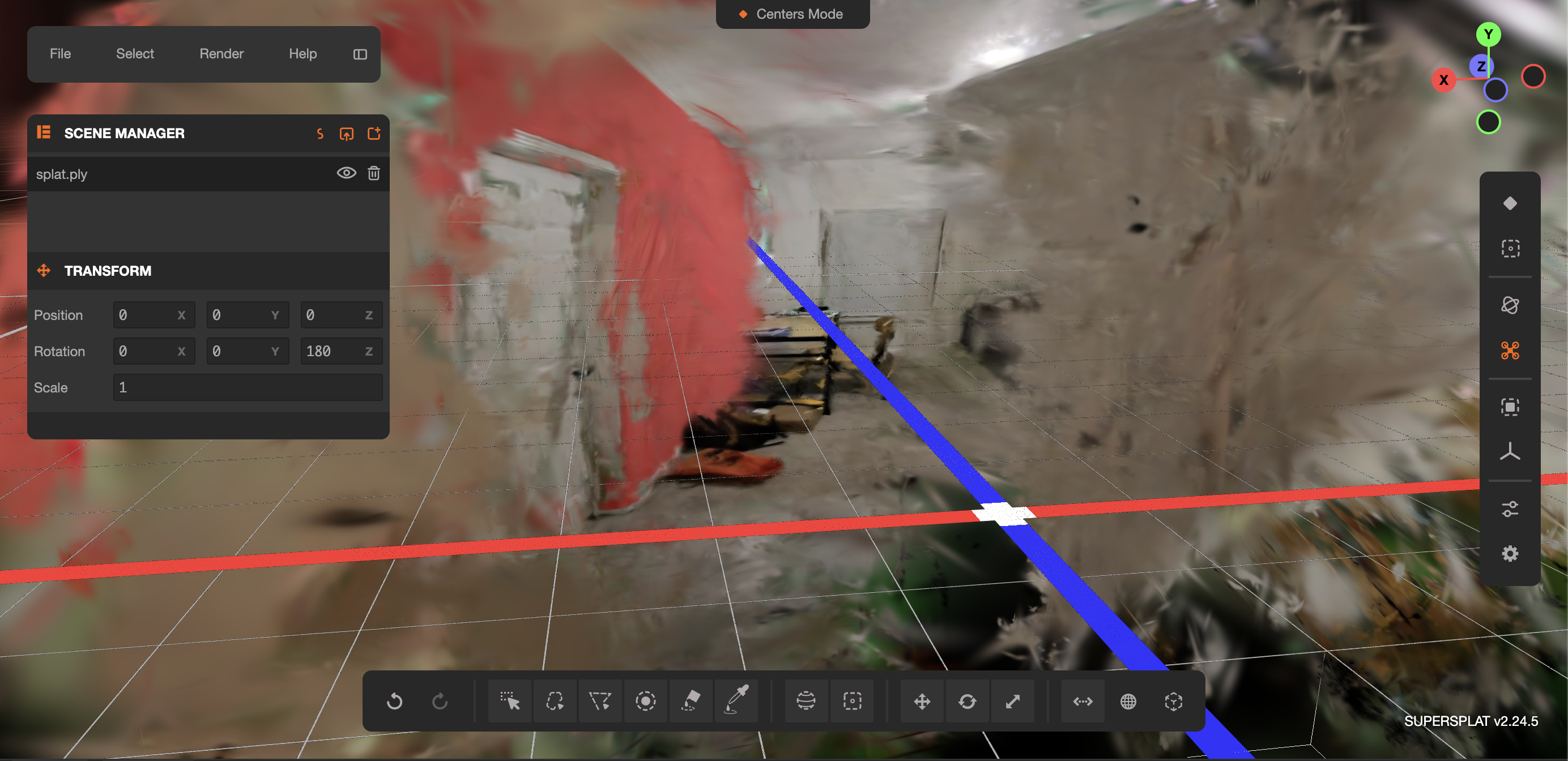
SpatialBuild turns a 30-second phone video into a voice-controlled, navigable 3D room redesigner.
You record a room. You speak changes naturally — "change the floor to hardwood," "paint this wall sage green," "remove that old shelf," "add a mid-century armchair in the corner." The system transcribes your commands, parses them into structured edits, applies them consistently across every video frame, and reconstructs the entire scene as a photorealistic 3D gaussian splat you can walk through in your browser.
Not a rendering. Not a single image. A full 3D environment built from your actual room, with your actual changes, viewable from any angle.
The before and after are both navigable — orbit around, zoom in on the new floor grain, walk from the doorway to the window. The spatial understanding this creates is fundamentally different from looking at a flat image. You don't just see the redesign. You experience it.
How we built it
The architecture splits into three pipelines that we divided across our team of two.
Voice pipeline. The raw audio goes through Whisper with word-level timestamps, producing a transcript where every word is anchored to a moment in the video. A local Mistral 7B model parses the natural language into structured JSON commands — classifying each into an action (recolor, replace, remove, add), a target (wall, floor, shelf, armchair), and parameters (sage green, hardwood, mid-century modern). No cloud API calls. Everything runs locally.
Vision pipeline. This is where SAM2 earns its keep. The key insight we had early on was that 3D reconstruction from edited frames requires edit consistency — if the floor looks different in frame 50 vs frame 200, COLMAP can't find matching features and the reconstruction falls apart. SAM2's temporal tracking solved this. It produces the same segmentation mask across every frame of the video, so when we swap a floor texture or inpaint a removed object, the edit is pixel-consistent across hundreds of frames. Surface edits (walls, floors) use mask-and-replace with tiled textures. Object removal uses SAM2 masks fed into an inpainting model to fill the gap. Object addition happens post-reconstruction as 3D mesh compositing.
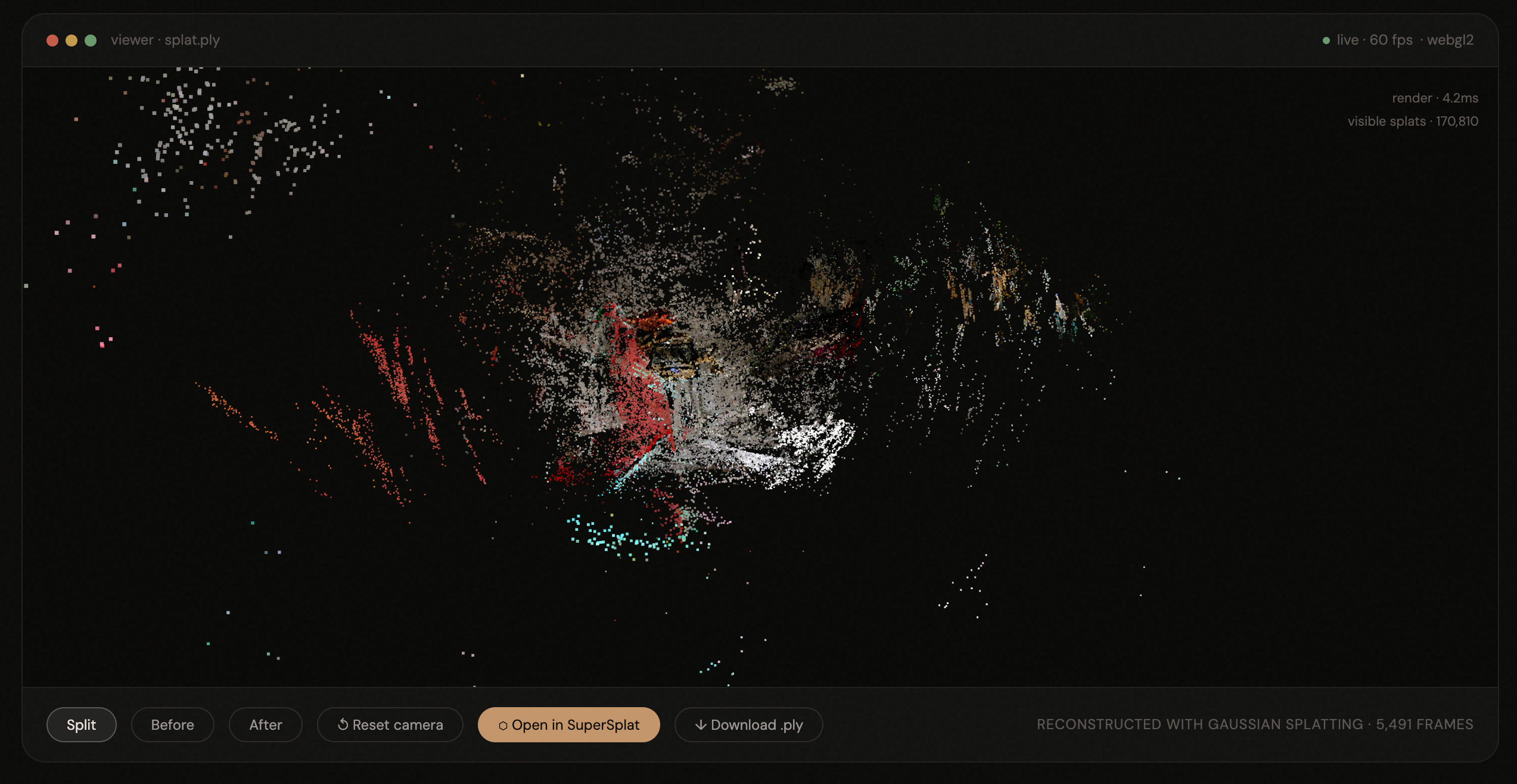
3D reconstruction pipeline. The edited frames go through COLMAP for Structure-from-Motion — extracting SIFT features, matching them across sequential frames, and triangulating camera poses plus a sparse 3D point cloud. This sparse scaffold then feeds into OpenSplat, which initializes a gaussian at each 3D point and trains them through a differentiable rendering loop on our AMD Instinct MI300 GPU. Each iteration renders the gaussians from a known camera angle, compares the result to the actual photograph, and backpropagates the loss to adjust every gaussian's position, shape, color, and opacity. After 10,000 iterations, the gaussians converge to a photorealistic representation of the edited room — exported as a .ply file and rendered in real-time via Three.js in the browser.
The critical architectural decision was treating surface edits and object additions differently. Surfaces (walls, floors, paint) are edited in 2D before reconstruction — this gives us pixel-perfect control and frame consistency. New furniture is added in 3D after reconstruction — generated as meshes via text-to-3D and composited into the splat viewer. This hybrid approach plays to each tool's strengths instead of forcing one technique to do everything.
Challenges we faced
Frame consistency was the hardest problem. Our first attempt at editing frames independently produced a psychedelic nightmare — COLMAP found zero matches because every frame's floor had a different wood grain pattern. The realization that SAM2's temporal tracking was the solution, not just a convenience, came after two failed reconstruction attempts.
COLMAP doesn't use AMD GPUs. COLMAP's GPU acceleration is built on OpenGL/CUDA. Our MI300 speaks ROCm/HIP. We spent time trying to make GPU SIFT work (Xvfb virtual displays, Mesa drivers) before accepting that CPU SIFT at 60 seconds for 150 frames was fast enough. The GPU muscle goes where it matters — OpenSplat training.
OpenSplat's build system and our container environment fought each other. The ROCm linker couldn't find clang++, cmake paths were wrong, the binary got nested three directories deep. We burned time on build tooling that had nothing to do with the actual algorithm. Hackathon lesson: containerized builds have edge cases that no README covers.
Splat quality is a function of input quality, not just iteration count. Our first splat was blurry — we threw 30,000 iterations at it, which helped minimally. The actual fix was fewer, sharper frames at lower resolution with better angular coverage. 150 frames at 720p with deliberate camera movement produced better results than 600 frames at full resolution from a shaky video.
What we learned
The biggest lesson was that the pipeline design matters more than any individual model. We spent the first hours researching the most powerful tools — World Labs Marble for generative 3D, GaussianEditor for text-guided editing, the latest diffusion models for video-to-video. Most of them couldn't do what we needed, or couldn't do it consistently enough for downstream reconstruction.
The solution that worked was boring by comparison: segment consistently, edit simply, reconstruct faithfully. SAM2 + texture replacement + COLMAP + OpenSplat. No single component is cutting-edge on its own. The innovation is in how they compose — voice commands flow into frame edits flow into 3D reconstruction, with each stage's output format matching the next stage's input requirements.
We also learned that gaussian splatting is genuinely ready for production. The gap between "research demo" and "usable tool" has closed. OpenSplat on a modern GPU produces photorealistic reconstructions in minutes. Three.js splat renderers run at 60fps in a browser tab. The file format ecosystem (PLY, SPZ, KSPLAT) has standardized. A year ago this pipeline would have taken weeks of custom CUDA kernel work. Today it's a Python script.
What's next for SpatialBuild
The immediate extension is a proper web app — upload a video, speak or type commands, get a shareable 3D link. The compute pipeline runs in minutes and costs under a dollar, making it viable as a SaaS product for real estate agents and interior designers.
Beyond staging, the same pipeline generalizes to any spatial editing workflow. Renovation contractors showing clients proposed changes before breaking ground. Insurance adjusters documenting damage and visualizing restoration. Architects placing new structures in the context of real existing environments. Event planners previewing venue layouts.
The core capability — speak what you want, see it in 3D, from your actual space — is a new interaction paradigm. We built the first version in a weekend. The potential is much bigger than real estate.

Log in or sign up for Devpost to join the conversation.