-
-
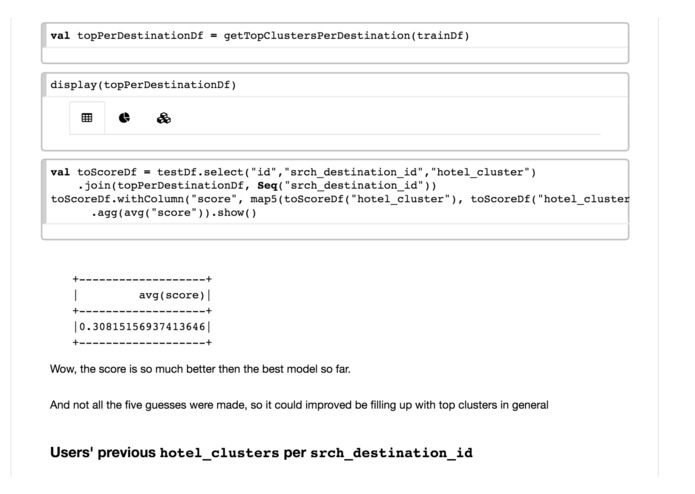
Sample fragment of Spark-notebook
-
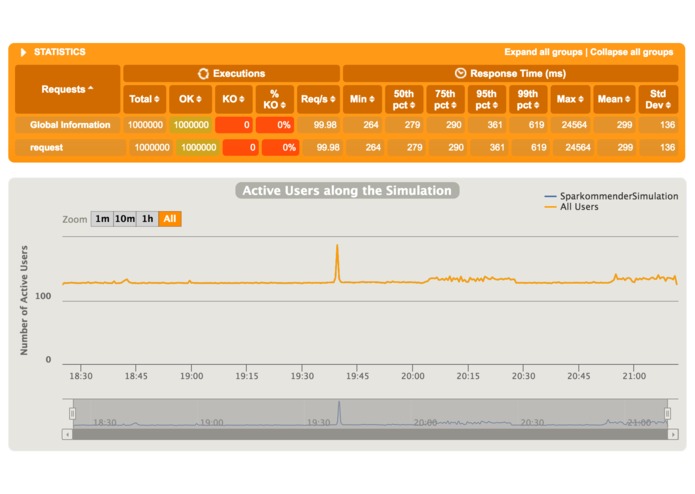
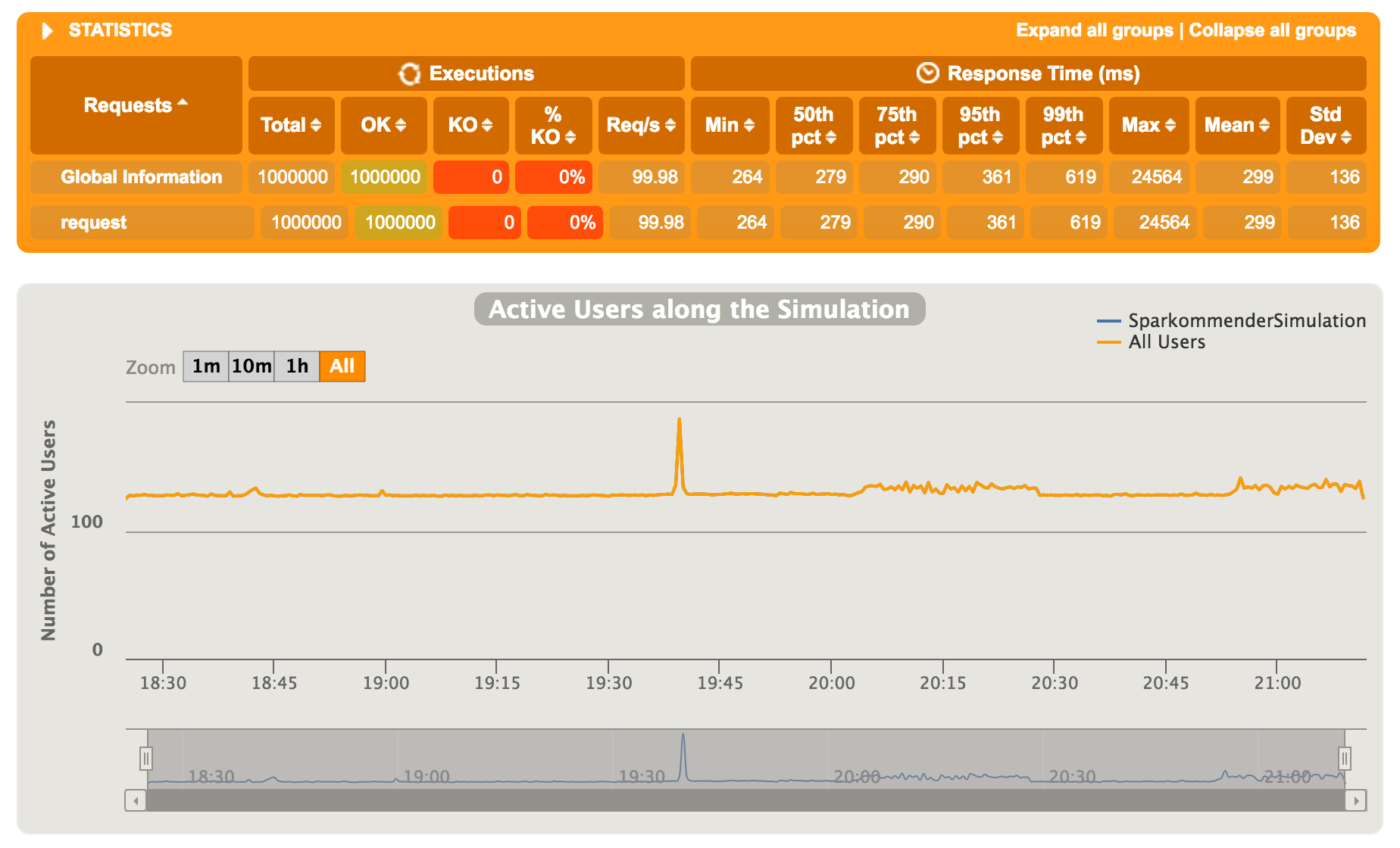
Sparkommender performance and stability results for making 1M recommendations
-
Sparkommender demo page running on iPhone 6
-
Sparkommender running in Docker Cloud/AWS
-
Sparkommender running in Bluemix Containers Service


Inspiration
Recommendation engines are becoming a necessity for every trading company nowadays. This is particularly important in the travel sector, where the race is on between the competitors for the market share by keeping old and attracting new customers. The holy grail is to improve the user experience and at the same time increase the revenue. Main challenges come both from the shear amount of data like user clicks and bookings and from high velocity of the incoming users' requests.
First challenge is to be able to gain insights, analyze and build accurate models when the data is too big to fit into a memory of a single computer.
Second challenge is to actually apply the knowledge we gained (ML models) in a real business setting like a booking website where the users are not left waiting for the recommendations to load on the page.
What it does
Sparkommender solves the above two challenges and allows hotel booking companies easily incorporate very fast and accurate hotel recommendation service directly into their websites or mobile apps. And, as a result, improve customer satisfaction and implicitly generate more revenue.
How I built it
- Used Apache Spark with notebooks to gain knowledge about the data and build best recommendation models by applying various Machine Learning techniques.
- Built Dockerised Play! Web Service with a REST interface
- Tested portability by running both in IBM Containers Service and Docker Cloud/AWS
- Tested performance and stability by running Gatling tests (http://sparkommender.com/assets/simulation/index.html)
- Built a simple website integrating the microservice (http://sparkommender.com)
Challenges I ran into
One of the initial ideas of the project was to use a streaming recommendation engine, where the recommendations themselves get better over time with the added information about the actual new bookings. However, having Spark serve the actual recommendations was not quick enough for production, even after spending lots of effort on various optimisations when using Spark Job Server.
Accomplishments that I'm proud of
Great performance results of the one million recommendation test.
What I learned
Use the best tool for the job: Spark was not made for super fast response times.
What's next for Sparkommender
Try some Deep Learning tools like Tensorflow to come up with more accurate recommendation model.



Log in or sign up for Devpost to join the conversation.