-
-
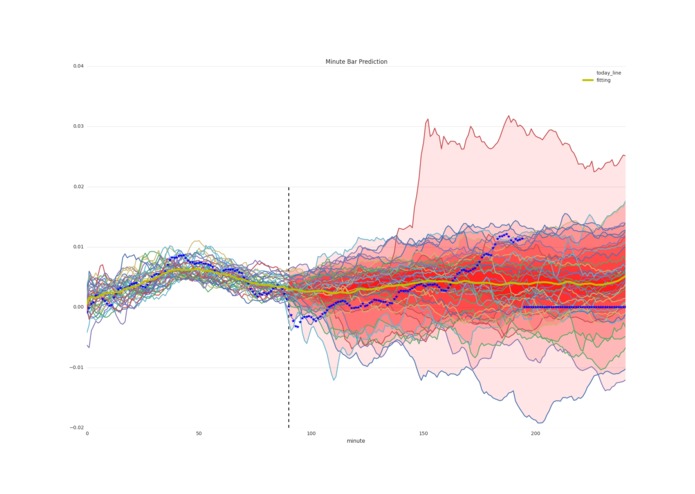
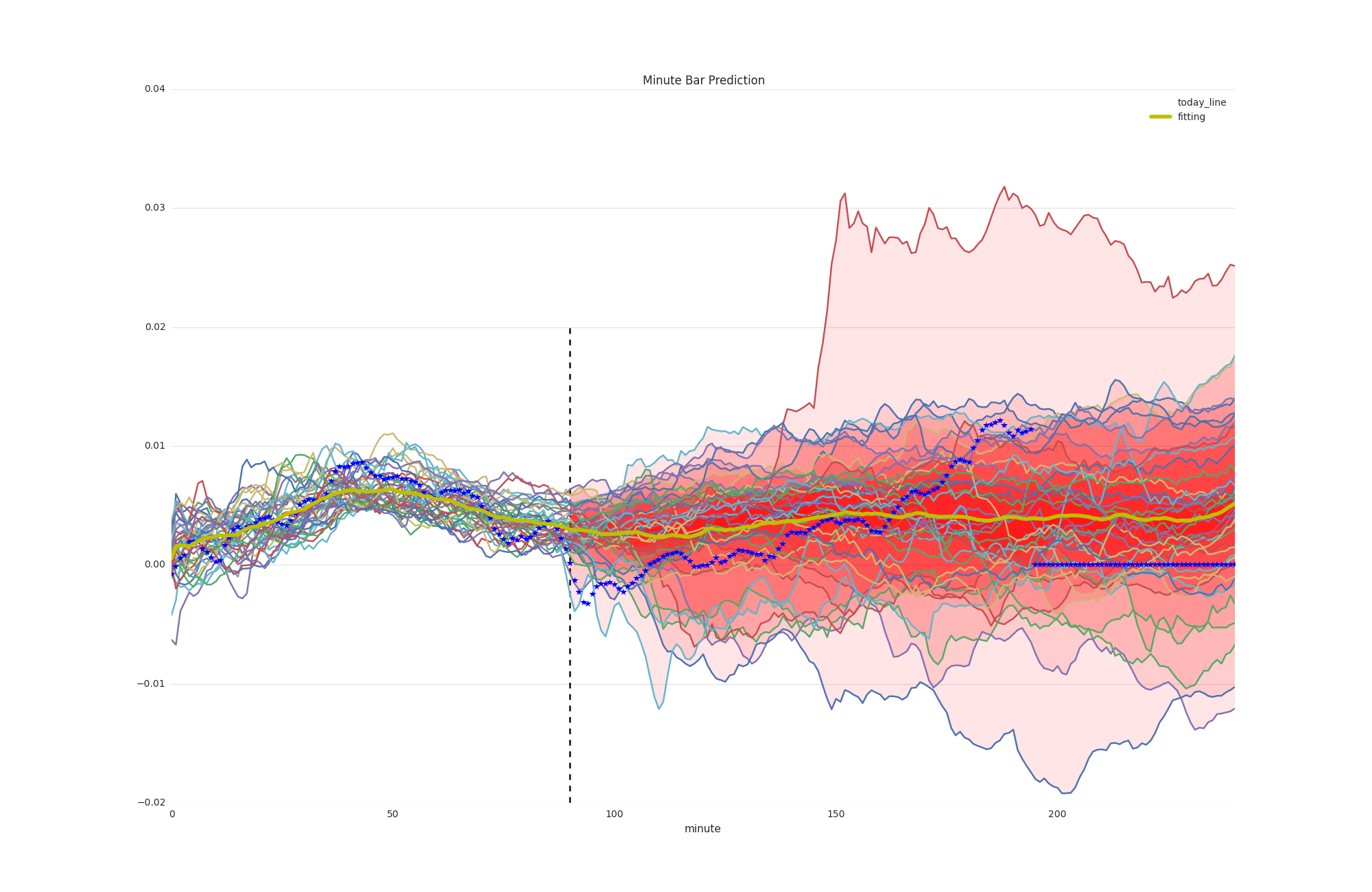
Index prediction using minute bar
-
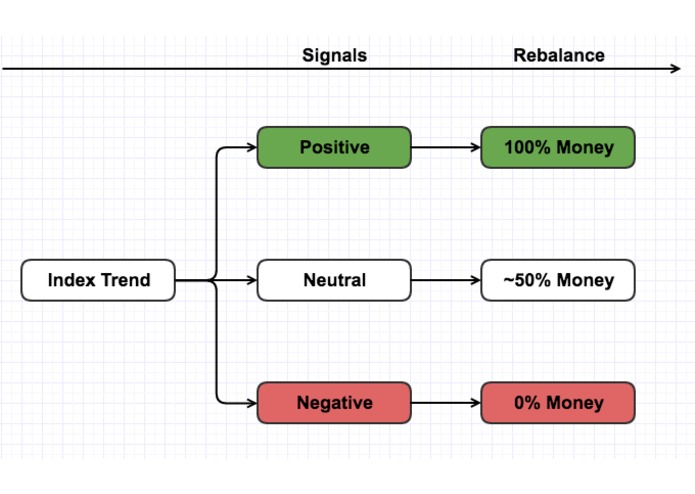
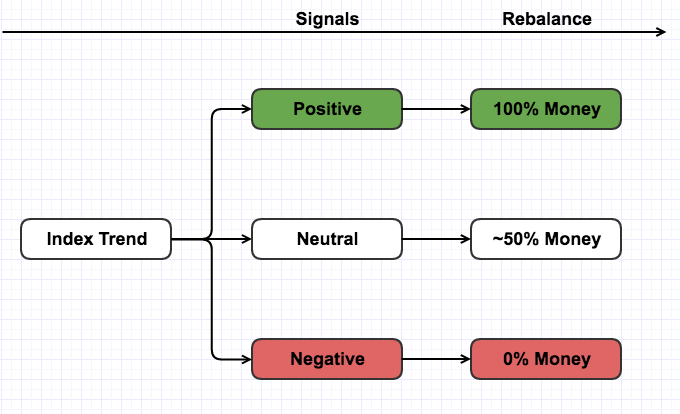
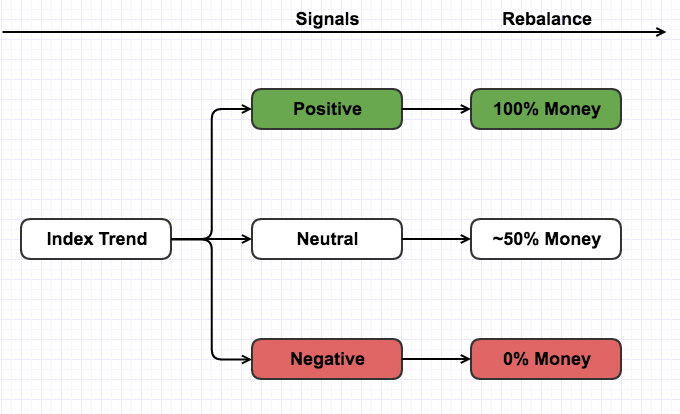
Macro timing and portifolio rebalance
Spark-in-Finance-Quantitative-Investing
Product
This is a module in some financial investment startegies. Through analysing the trend of index, we can build some macro timing or portifolio adjustment signals.
Screenshot
similarity line and predict trend
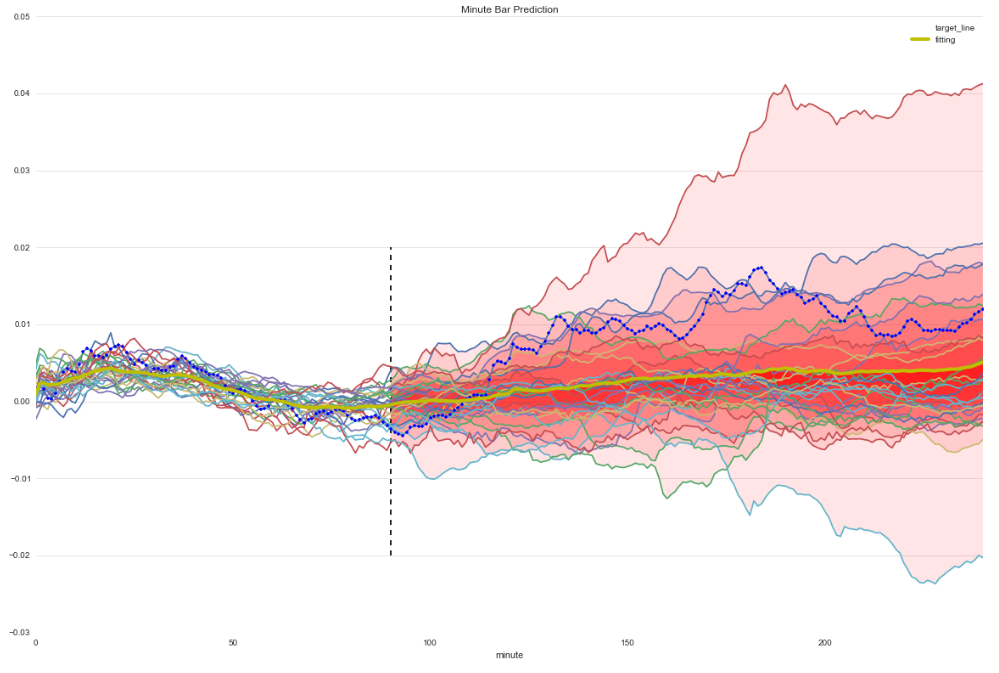
prediction close index change percent
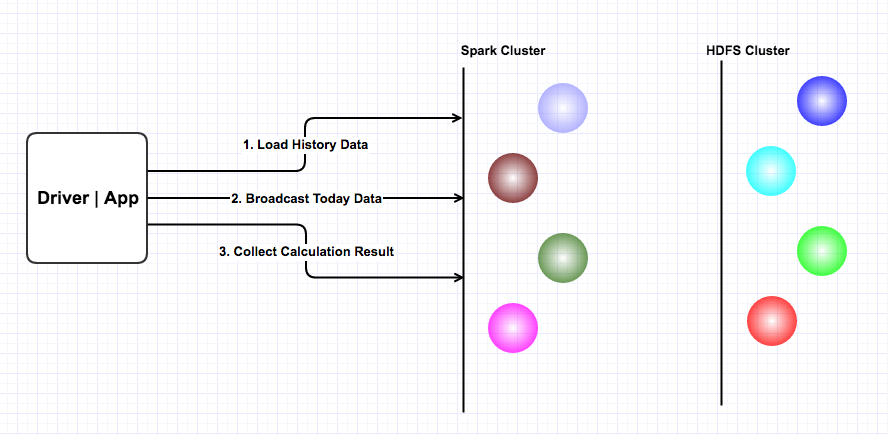
Architecture
Bellow is the brief indroduction of this app:
- During the transaction time:
- Spark cluster loads all the history data;
- Dirver loads today's data;
- Driver broadcasts today's data to the cluster;
- Spark cluster parallelly calculates similarity data;
- Dirver collects the calculation results;
- Dirver parses the calculation results;
Data Used
This application used serveral data bellow:
- Index minute bar in the previous serveral years;
- Index minute bar of today, refresh every one minute;
Alogorithms
Just for the demo, I used the basic similarity algorithm.
Value of Product
This application is a module in some quantitative funds, it can be used in macro timing and portifolio rebalancing.
For the future, there are endless imaging and extension space. For example, as the data growing more and more, we can put more data in the algorithm, and design serveral different algorithms to do the prediction parallelly, leverage the power of big data and Spark, completing a calculation round within 1 second, build high-frequency singals in the market. Which will be a revolution in the financial market.
I currently use a more complex algorthim do calculate the similarity and build macro signals in my private investment account, it really works, and I believe it will do much better in the future.
Imporvement
- More data:
- Using more history data
- Using more kinds data
- price
- volume
- money flow
- Signals
- Macro timing
- Portifolio rebanlance
- Ticker timing
- Ticker pair trading strategy
- Larger cluster
Future
In recent years, as the big data announcing its power, more and more frameworks show their muscles to the world. Apache Spark it one the most powerful framework in my eyes, and now there are many companies start put Spark in their buisness systems. But, as we known, most of today's Spark applications are dealing with logs and machine learning models, to be frankly, we do not leverage the power of big data and Spark until the Finacial Market pays attention on the mass big data and Spark.
In quantitative investing field, we using some mathematic methods to do analysing market data, in order to build some signals in our strategies. As the data grows more and more, as the models become more and more complex, we need a powerful tool to do parrallelly computing on the mass market data.
This application, Spark-in-Finance-Quantitative-Investing, is just a demo, but it's really powerful and useful. I believe through this application, the quant can find that Spark, is the thing they are seeking to do the analysing, computing, modeling, etc job.
Github
Spark-in-Finance-Quantitative-Investing



Log in or sign up for Devpost to join the conversation.