-
-
dashboard
Inspiration
Two observations sitting next to each other for months.
The first: every Sunday at midnight my Claude Pro credits reset. I've never once hit the weekly cap. Neither has anyone I asked. The unused capacity just evaporates.
The second: I follow a handful of open source projects on GitHub and the same pattern keeps showing up. Kubernetes sits on three thousand open issues. Babel maintainers ship most of their reviewer time on the first 80% of style and test nits before a human should touch the PR. Home Assistant gets the same bug filed weekly because GitHub search is bad. None of these projects are going to expense a Claude seat per maintainer. The unit economics of paid AI subscriptions don't match the shape of OSS labor.
The pitch wrote itself. There's a waste on one side and an unfunded need on the other. Connect them.
What it does
Spare-change is a local Python daemon plus a small distributor service. As a donor, you install the daemon, point it at a distributor, and configure a credit window (e.g., the last ten hours of your weekly cycle) and an allowlist of OSS projects you want to support. Inside that window the daemon polls the distributor for tasks, runs them with claude --print against your existing Claude Code session, and POSTs the result back over a webhook. API users can specify a dollar cap instead and treat the contribution as a clean line-item donation.
Maintainers paste three files into their repo to opt in: a .github/SPARE_CHANGE.md notice declaring what task kinds they accept, a stdlib-only Python script that reads a YAML manifest and seeds the queue, and a weekly cron GitHub Action that runs the script. Each completed task becomes a GitHub-issue-ready markdown body. One command (./scripts/file_issue.sh ) opens it as a draft issue on the maintainer's repo.
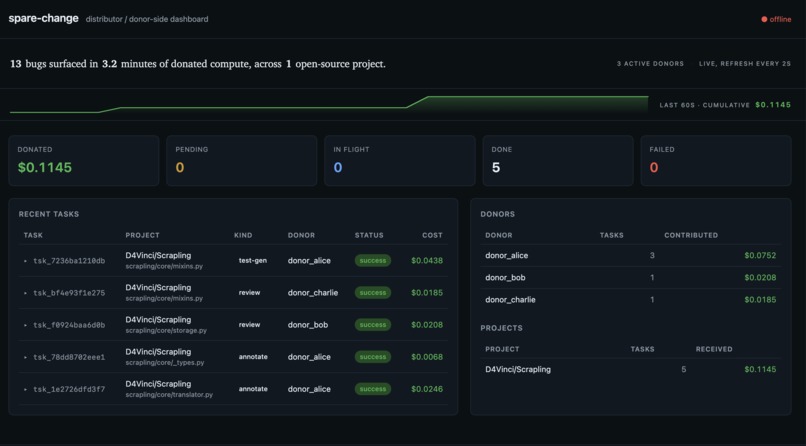
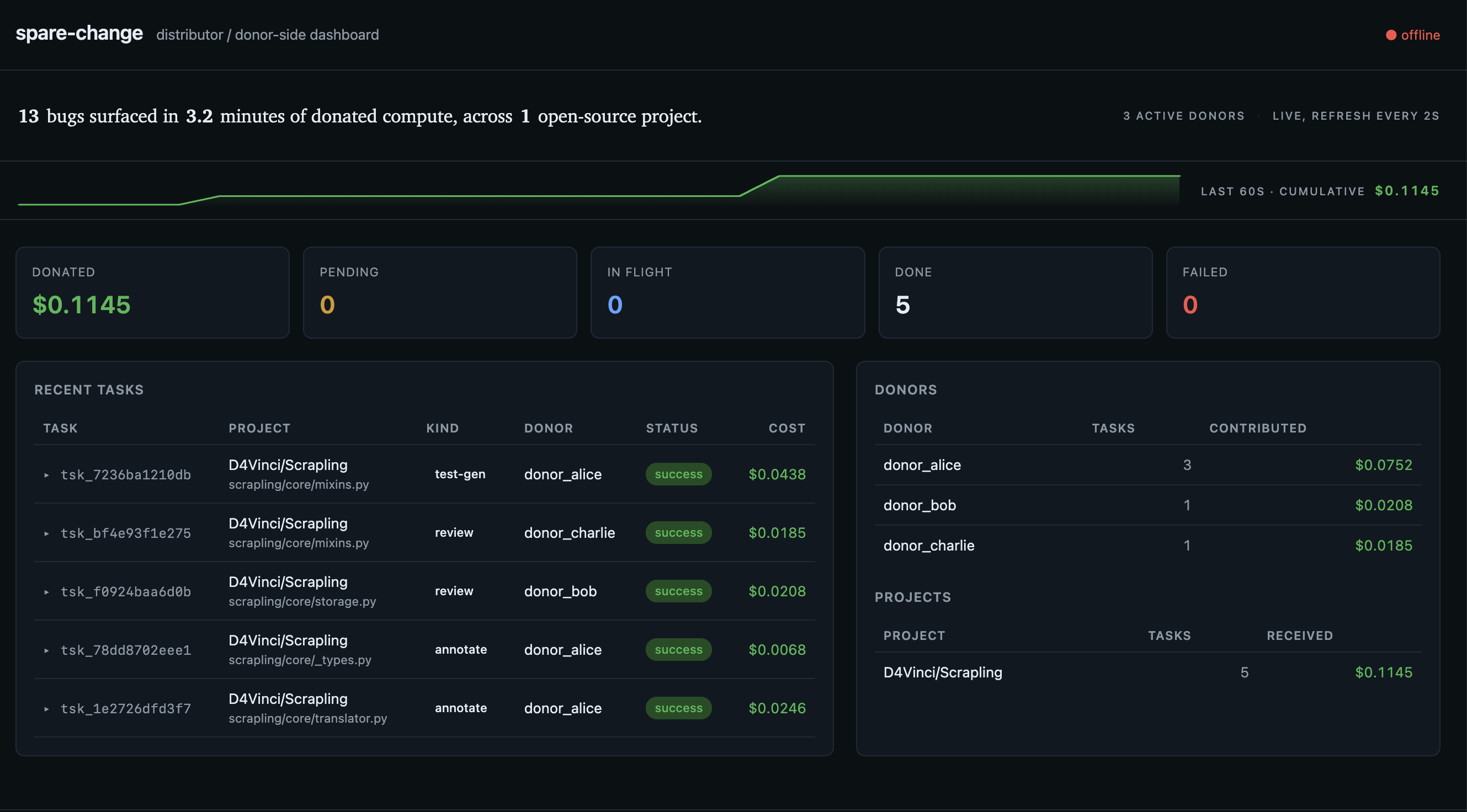
The distributor exposes a live dashboard at / showing queue counts, per-donor and per-project leaderboards, a sixty-second sparkline of cumulative donations, click-to-expand task previews, and an editorial byline that reads "N bugs surfaced in M minutes of donated compute, across K open-source projects." A separate /discover page lists registered projects with one-click YAML snippets so donors can add a project to their allowlist by pasting one line. A /receipts/ page gives donors a tax-records summary of their session.
How we built it
Python 3.11, FastAPI, Pydantic v2, PyYAML, httpx, uvicorn. The donor agent shells out to the official claude CLI in print mode rather than going through an SDK, because that's the only way to actually spend a Pro/Max subscriber's credits today; the Anthropic SDK requires an API key that bills separately. We wrapped the subprocess with start_new_session=True and a process-group kill on timeout so a hung claude invocation can't orphan its children.
The distributor uses an in-memory dict + deque as a deliberate swap-point for NATS JetStream later. The dashboard is a single self-contained HTML constant in main.py, vanilla JS, no build step. We used the impeccable design skill's principles to keep it editorial: hairline rules instead of boxed cards, serif numerals in the byline, restrained green accent only on money figures, sparkline as a continuous polyline with a soft gradient fill rather than the usual SaaS hero-metric strip.
We aggressively parallelized the build using git worktrees with subagents. While the main session built core infrastructure, subagents ran in isolated worktrees building things like the donor receipts page, the multi-donor demo script, the maintainer adoption kit, and the documentation sync. Merging back was a cherry-pick of disjoint sections of the same files. This routinely cut sprint wall-clock from forty minutes serial to twenty-five parallel.
Challenges we ran into
The Goose runtime turned out to be the wrong tool for the job. We initially planned to use Block's open-source agent framework, but Goose requires an Anthropic API key and Anthropic has actively blocked third-party tools from authenticating against Pro and Max subscriptions. So we shelled out to the official claude CLI instead, which works against the donor's existing session. This is documented in the README so the path back to Goose is clear once subscription OAuth ships.
Numaflow was the other dead end. Streaming on paper, K8s-native in practice, push-edge architecture. Pull semantics from a donor's laptop would need a bridge layer that's bigger than the queue it's wrapping. We swapped to a plan to use NATS JetStream behind an HTTP gateway when we outgrow the in-memory queue.
The smallest bug took the longest to find. The /discover page hung on "Loading…" because a Python triple-quoted JS string had \n where it needed \n, which Python renders as a literal newline mid-JS-string. JS SyntaxError. The browser silently swallowed the script. The fix was one character.
Accomplishments that we're proud of
We have an end-to-end working demo that finds real bugs in real projects. Pointing the agent at D4Vinci/Scrapling/scrapling/core/mixins.py review reliably surfaces an infinite-loop bug at line thirty-five plus XPath construction errors and test gaps, in about forty-five seconds, for under two cents of credit value. Different runs find different real bugs. The system is reproducibly useful.
Twenty out of twenty tests pass. Three commits, five working scripts, two browser-rendered pages, a maintainer adoption kit, a deck, and a captured backup artifact, all in roughly three and a half hours of focused work.
We avoided every SaaS visual cliché the dashboard wanted to become. The byline reads as a sentence, not a card grid.
What we learned
The shape of the problem matched the shape of the solution better than we expected. Donor agents are stateless polling clients. Maintainers want artifacts they can paste into existing tooling, not new platforms. The whole system collapses to a JSON queue and a few markdown formatters.
Research before commit is cheap. Two parallel research passes (Goose, Numaflow) saved us from two weeks of going down the wrong path. Naming the wrong tools clearly in the README is worth more than glossing over them.
Editorial restraint reads as more credible than SaaS polish. The dashboard would have been worse with a gradient hero-metric strip even though every instinct in the modeling reached for one.
What's next for spare-change
A NATS JetStream gateway behind an HTTP edge to replace the in-memory queue, so the distributor can fan tasks out to fifty thousand donors instead of three.
Multi-donor coordination with leases and dedup, so two agents don't burn credits running the same task. Today the three-donor demo races on claim_next; tomorrow it cooperates.
SQLite persistence so tasks survive a distributor restart. The store interface was designed for this swap.
Pilot adoption with a real OSS maintainer. The kit is in place, the artifact pipeline works. The next question is whether a maintainer will actually paste those three files into their repo and start receiving donor compute. The technology is the easy part. Adoption is the hackathon afterwards.
Goose runtime the moment Anthropic ships OAuth for Claude subscriptions. The subprocess hack is a workaround, not the destination.

Log in or sign up for Devpost to join the conversation.