Spar
Inspiration
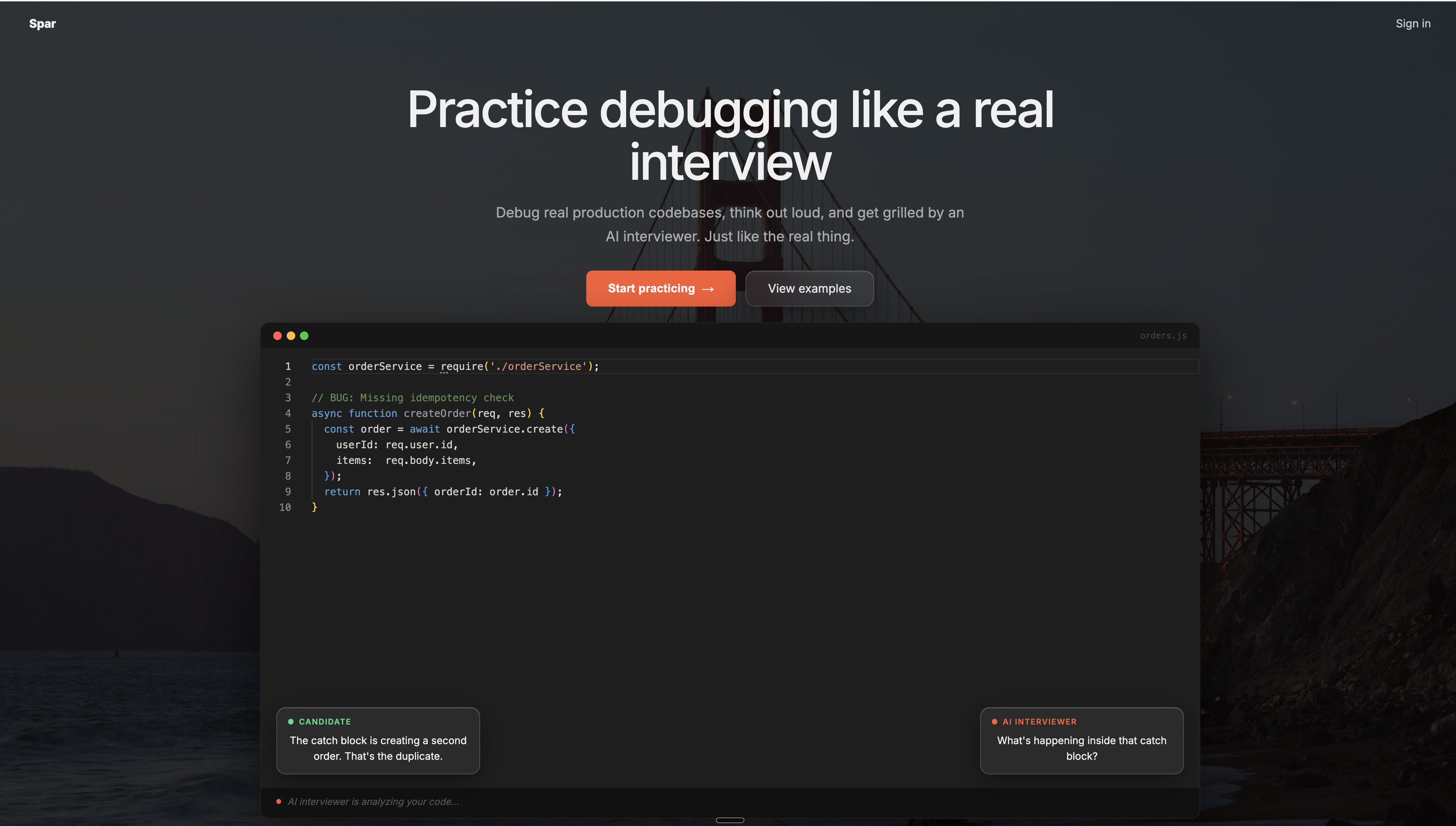
We got tired of grinding LeetCode for interviews that look nothing like LeetCode. Real engineering interviews drop you into a broken codebase and watch how you think. How you explore, how you communicate, how you handle pressure. The prep industry never caught up. We built Spar in 7 hours to fix that.
What It Does
Spar is an AI-powered mock coding interview platform. A candidate picks a broken codebase scenario, thinks out loud while an AI interviewer listens and pushes back in real time, debugs the code in an in-browser Monaco editor, and receives a scored report card when they finish.
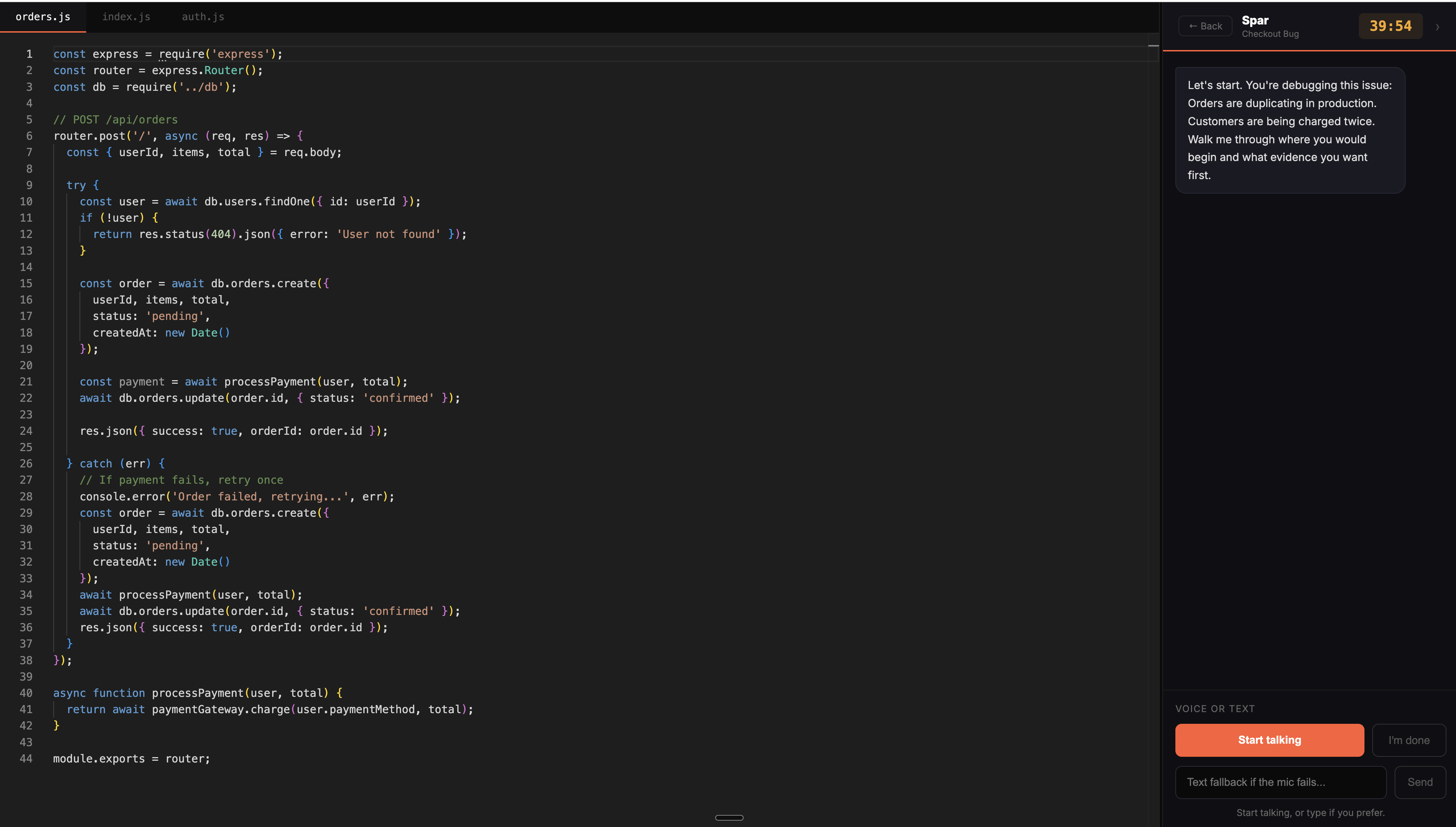
Agent 1 — The Live Voice Interviewer Powered by Deepgram's Voice Agent API over a full-duplex WebSocket. The candidate speaks naturally - their audio streams as raw PCM at 16kHz via an AudioWorklet. Deepgram handles speech recognition and routes each utterance through a tuned Gemini 2.5 Flash system prompt that plays the role of a senior engineer. It asks one short follow-up question at a time, pushes on reasoning, not just actions, and never gives the answer away. The whole loop, speak, process, respond, runs in under three seconds.
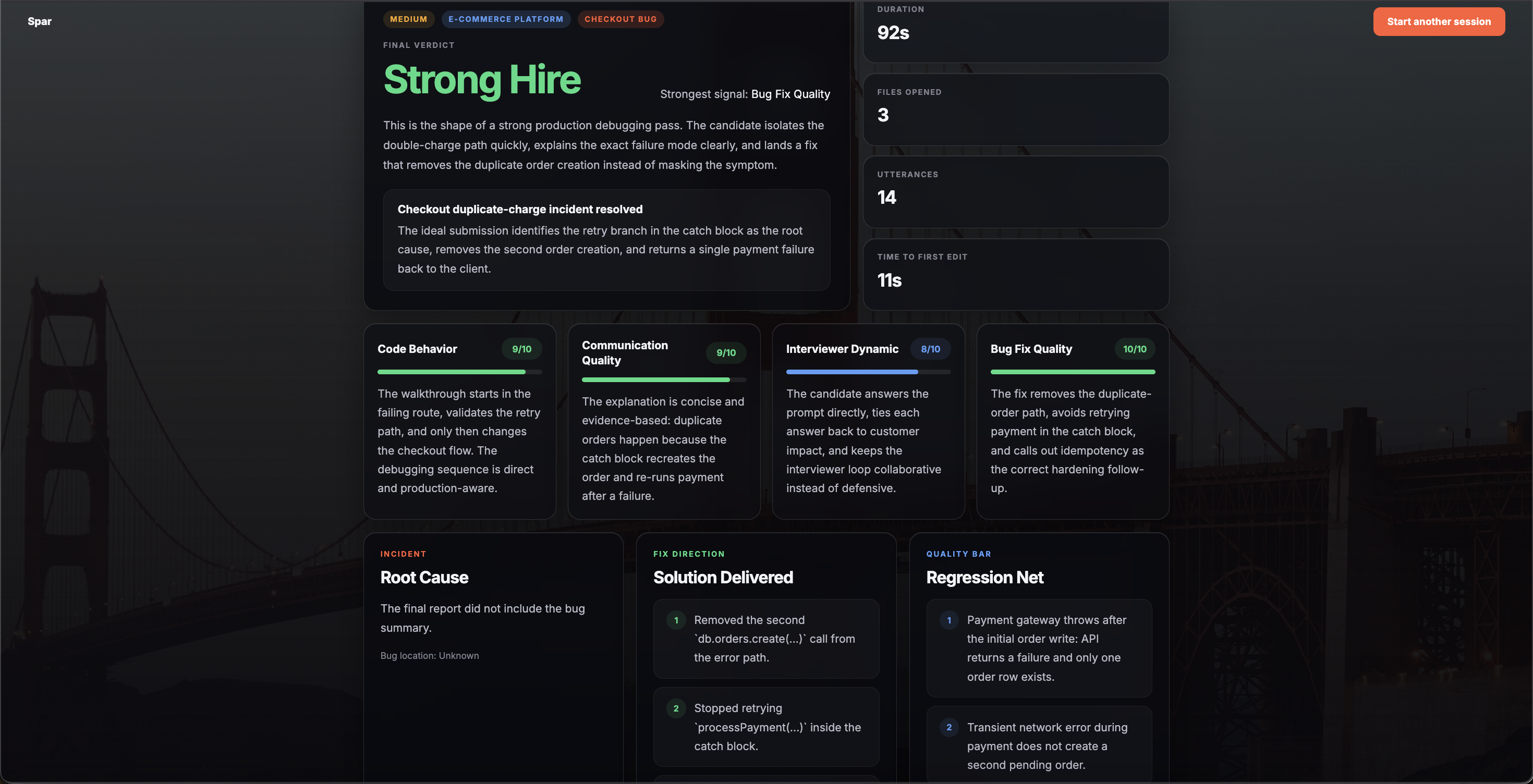
Agent 2 — The Code Behaviour Analyzer Fires after the session ends as part of a parallel report pipeline. It reads the full session tracker: which files the candidate opened, how long before they made their first edit, and every editor event logged during the session. It scores code reading discipline and exploration instinct, the signals that separate engineers who understand a system from those who guess and check.
Agent 3 — The Communication Quality Analyzer Runs in parallel with Agent 2. It reads the full chat history between the candidate and the AI interviewer and evaluates the specificity and clarity of every spoken statement. Strong candidates narrate every thought, including dead ends. This agent measures exactly that.
Agent 4 — The Interviewer Dynamic Analyzer Also runs in parallel. It measures how the candidate engaged with the interviewer, response rate to follow-up questions, whether they treated the AI as a collaborator or ignored it. Interviewers notice this in real interviews. So does Spar.
Agent 5 — The Bug Fix Quality Analyzer Compares the candidate's final edited files against the answer key stored in the scenario definition. It evaluates whether the actual fix addressed the root cause, not just the symptom.
Agent 6 — The Synthesizer Once all four analyzers complete, the synthesizer merges their outputs into a single coherent report: a verdict, a verdict summary, per-dimension scores, and next steps. Verdict thresholds: ≥8.5 = Strong Hire, ≥7 = Hire, ≥5.5 = Leaning Hire, ≥4 = Leaning No Hire, else No Hire. If any agent fails, a fallback report computes scores locally from raw session metrics - the report always returns something.
How We Built It
| Layer | Technology |
|---|---|
| Frontend | React 19 + Vite |
| Code Editor | @monaco-editor/react (VS Code in the browser) |
| Voice Interview | Deepgram Voice Agent API (full-duplex WebSocket) |
| Audio Capture | AudioWorklet — raw PCM at 16kHz |
| AI Orchestration | Backboard.io (Gemini 2.5 Flash) |
| Report Pipeline | 4 parallel analyzer agents + 1 synthesizer via Backboard |
| Backend API | Node.js + Express 5 |
| Styling | Plain CSS — inline styles, dark theme |
The Architecture
┌─────────────────────────────────────────────────────────────────┐
│ User Layer │
│ │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ Candidate Browser │ │
│ │ - Scenario select (Easy / Medium / Hard) │ │
│ │ - Monaco editor (in-browser code editing) │ │
│ │ - Voice bar (live transcript + mic controls) │ │
│ │ - Report card (scored dimensions + verdict) │ │
│ └──────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ Frontend Layer │
│ │
│ │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ React 19 + Vite │ │
│ │ - Screen state machine (App.jsx) │ │
│ │ - useLiveVoiceInterview — WebSocket + AudioWorklet │ │
│ │ - useSessionTracker — file opens, edits, utterances │ │
│ │ - No router library — plain useState navigation │ │
│ └──────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ Backend Layer │
│ (Express.js) │
│ │
│ ┌───────────────────────┐ ┌───────────────────────────┐ │
│ │ /api/interview/live │ │ /api/reports │ │
│ │ - Full-duplex WS │ │ - 4 parallel analyzers │ │
│ │ - Deepgram Voice Agent│ │ - Synthesizer agent │ │
│ │ - PCM audio bridge │ │ - Fallback report engine │ │
│ │ - Session lifecycle │ │ │ │
│ └───────────────────────┘ └───────────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘
│ │
▼ ▼
┌──────────────────────────┐ ┌──────────────────────────────┐
│ Voice AI Layer │ │ Orchestration Layer │
│ Deepgram │ │ Backboard.io │
│ │ │ │
│ - Voice Agent API │ │ - Gemini 2.5 Flash │
│ - Real-time STT │ │ - 5 named assistants │
│ - gpt-5.4-mini think │ │ - Persistent threads │
│ - Managed turn-taking │ │ - Parallel agent runs │
└──────────────────────────┘ └──────────────────────────────┘
The Session Model
Every interview session tracks a live behavior log via useSessionTracker. Every file open, editor change, spoken utterance, and AI message updates the same tracker ref in real time. When the session ends, the full tracker is posted to /api/reports and passed through the report pipeline.
landing → difficulty → scenario → interview → report-loading → report
useSessionTracker
→ filesViewed, editorEvents, utterances,
chatHistory, finalFileContents, startTime
POST /api/reports { scenarioId, tracker }
→ 4 analyzers (parallel) → synthesizer → final report
Challenges We Ran Into
AudioWorklet PCM streaming. Deepgram's Voice Agent expects raw 16kHz PCM, not compressed audio. Getting the browser AudioWorklet to capture, downsample, and stream binary frames reliably --without dropouts that break the voice session - was the hardest technical piece.
GPT-5 temperature restriction. Deepgram's managed Voice Agent path with GPT-5 models silently rejects a temperature field in provider settings. We caught this mid-demo, traced it, and added buildThinkProviderSettings() to strip the field conditionally based on model name.
Shared scenario file. The server loads scenarios.js directly from the client package via dynamic import(). If the file isn't valid ESM or a scenario fails validation, the server throws on the first request. Getting this boundary right — and adding proper validation in lib/scenarios.js - took a full integration pass.
Parallel agent reliability. Four Backboard agents running in Promise.allSettled means partial failures are expected. Building buildFallbackReport() to compute meaningful scores from raw session metrics - so the report always returns something useful - was essential for demo safety.
Accomplishments We're Proud Of
- A full-duplex voice interview loop - speak, stream PCM, get an AI follow-up - running under 3 seconds end-to-end
- Five specialized Backboard agents running in parallel, producing a coherent scored report from raw session data
- A scenario data model shared cleanly between client and server with no duplication
- A complete, demo-ready product shipped in 7 hours across three parallel workstreams
What We Learned
The voice loop is the product. Everything else is scaffolding. We learned to build toward the live interview moment first — the candidate speaks, the AI pushes back instantly and polish everything else second. The fallback report was the best decision we made: knowing the report always returns something let us demo confidently without worrying about agent failures on stage.
What's Next for Spar
- More scenarios — distributed systems bugs, SQL performance issues, frontend regressions, security vulnerabilities across more difficulty tiers
- Persistent candidate history — track score improvement across multiple sessions over time, surface trends in communication and exploration
- Company-specific packs — scenarios modelled on real codebases from specific companies so candidates prep for the exact interview they're walking into
- Interviewer personas — different system prompt styles for different interviewer archetypes: Socratic prober, impatient tech lead, supportive mentor
- AI-generated scenarios — use an LLM to generate novel broken codebases on demand, expanding the library without manual authoring



Log in or sign up for Devpost to join the conversation.