-
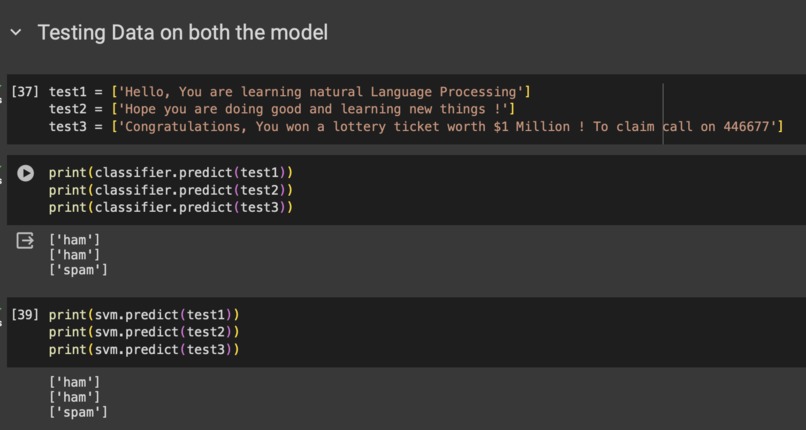
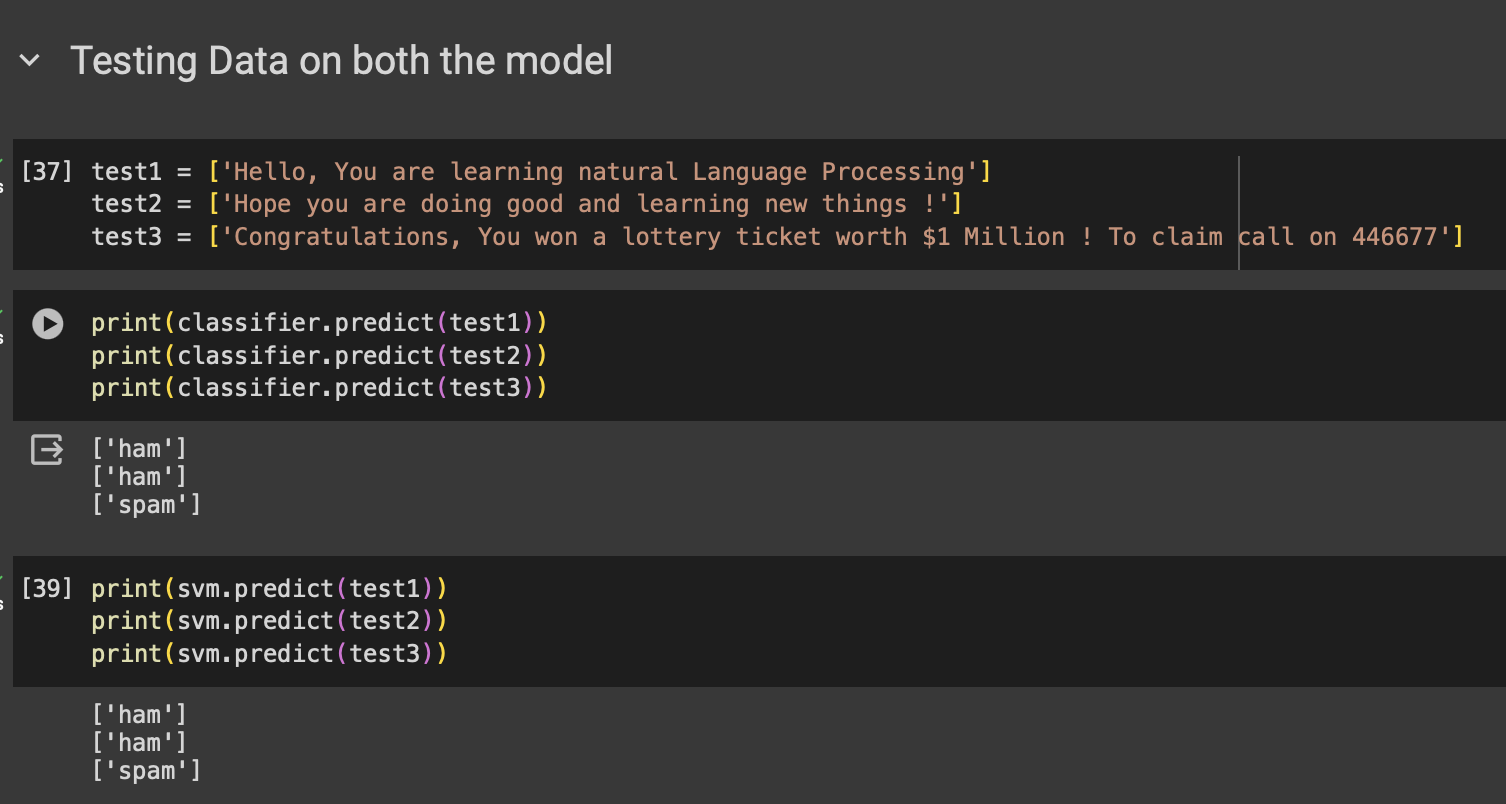
Result after implementing
Inspiration
The inspiration behind the Spam Message Classification project was the pervasive issue of spam in our daily digital communications. Spam messages not only clutter our inboxes but can also pose significant security risks, such as phishing attacks. Recognizing the need for an effective solution to filter out unwanted messages and enhance email security, this project was conceived.
What it does
The Spam Message Classification project leverages machine learning algorithms to accurately distinguish between spam and legitimate (ham) messages. By analyzing the textual content of emails, the system is designed to classify messages, thereby ensuring that users receive only relevant communications, while spam is effectively filtered out.
How we built it
The project was built using Python, with a focus on data preprocessing, feature extraction, and model training. Key steps included:
Data Preprocessing: We started with cleaning and preparing the data, which involved handling missing values, and ensuring a balanced dataset by sampling equal numbers of spam and ham messages.
Feature Extraction: We used the Term Frequency-Inverse Document Frequency (TF-IDF) vectorizer to convert text data into a format that could be processed by machine learning algorithms.
Model Training: Two different models were trained and evaluated:
- Random Forest Classifier: Known for its robustness and ability to handle non-linear data.
- Support Vector Machine (SVM): Chosen for its effectiveness in high-dimensional spaces, typical of text classification tasks.
Challenges we ran into
One of the main challenges was dealing with imbalanced data, as typically, datasets contain more ham messages than spam. Balancing the dataset without losing important information was crucial. Additionally, tuning the models to achieve high accuracy while avoiding overfitting required extensive experimentation with hyperparameters.
Accomplishments that we're proud of
We are particularly proud of achieving high accuracy in classifying messages, which demonstrates the effectiveness of our preprocessing and model training strategies. The use of a pipeline to streamline the process from vectorization to classification significantly optimized our workflow.
What we learned
Throughout this project, we deepened our understanding of natural language processing (NLP) techniques and machine learning algorithms. We gained practical experience in data preprocessing, feature extraction, and the intricacies of model selection and tuning.
What's next for Spam Message Classification
Looking ahead, we aim to further refine our models by incorporating more sophisticated NLP techniques, such as word embeddings and deep learning models like LSTM or BERT, for even more accurate spam detection. Additionally, we plan to explore the integration of this system into real-world email services, enhancing its accessibility and impact.


Log in or sign up for Devpost to join the conversation.