-
-
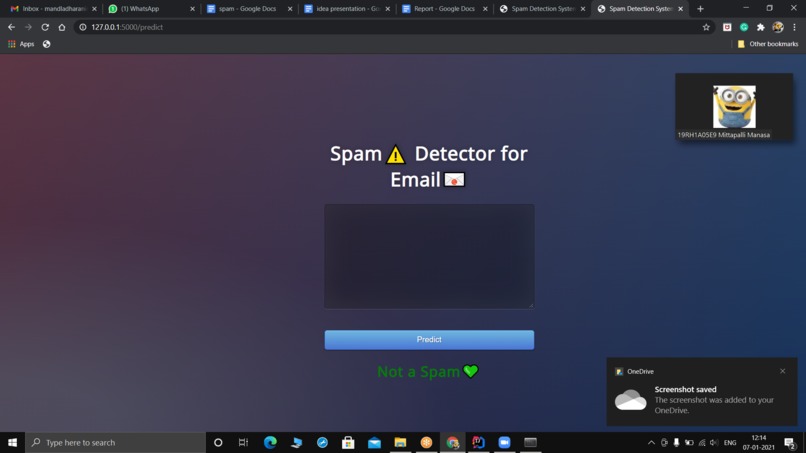
Not a spam message
-
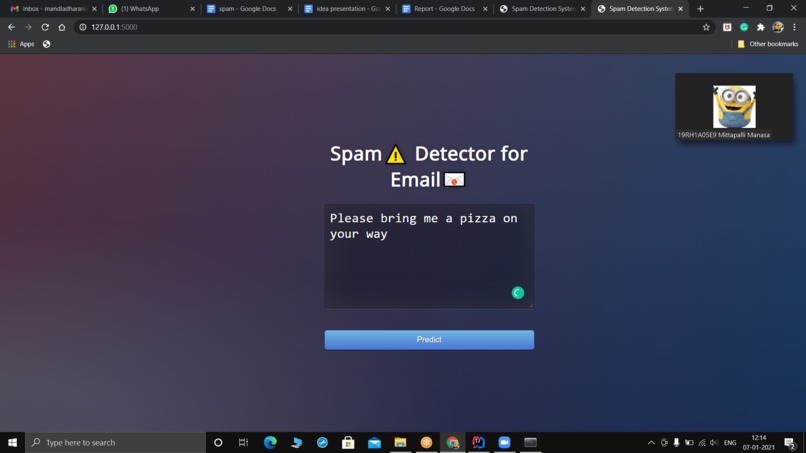
Text
-
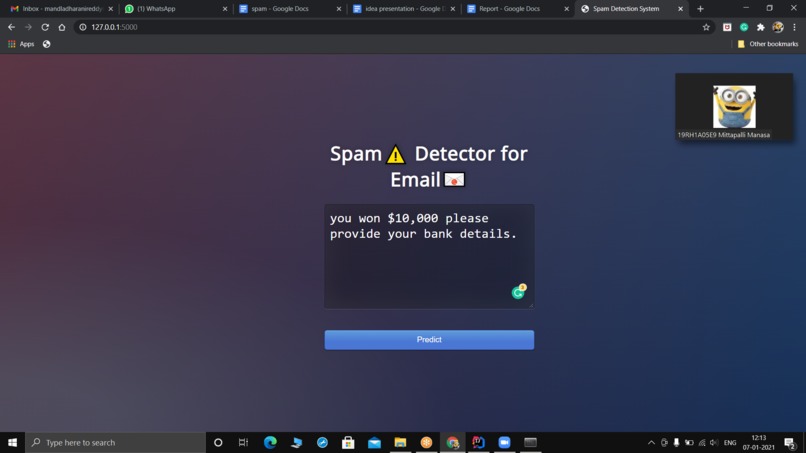
Text
-
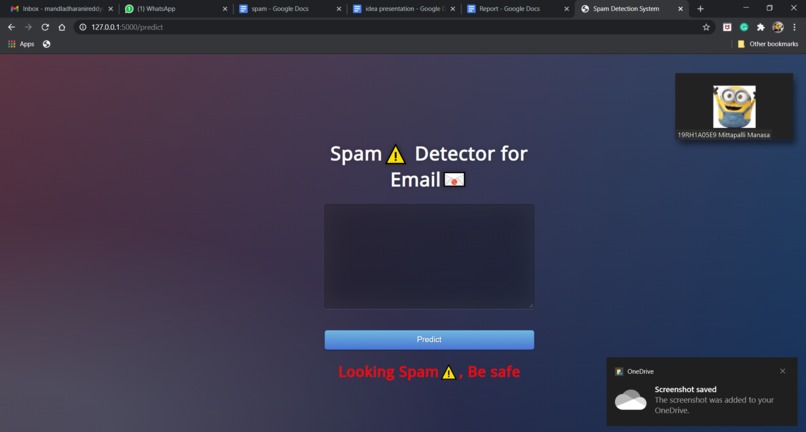
Spam message
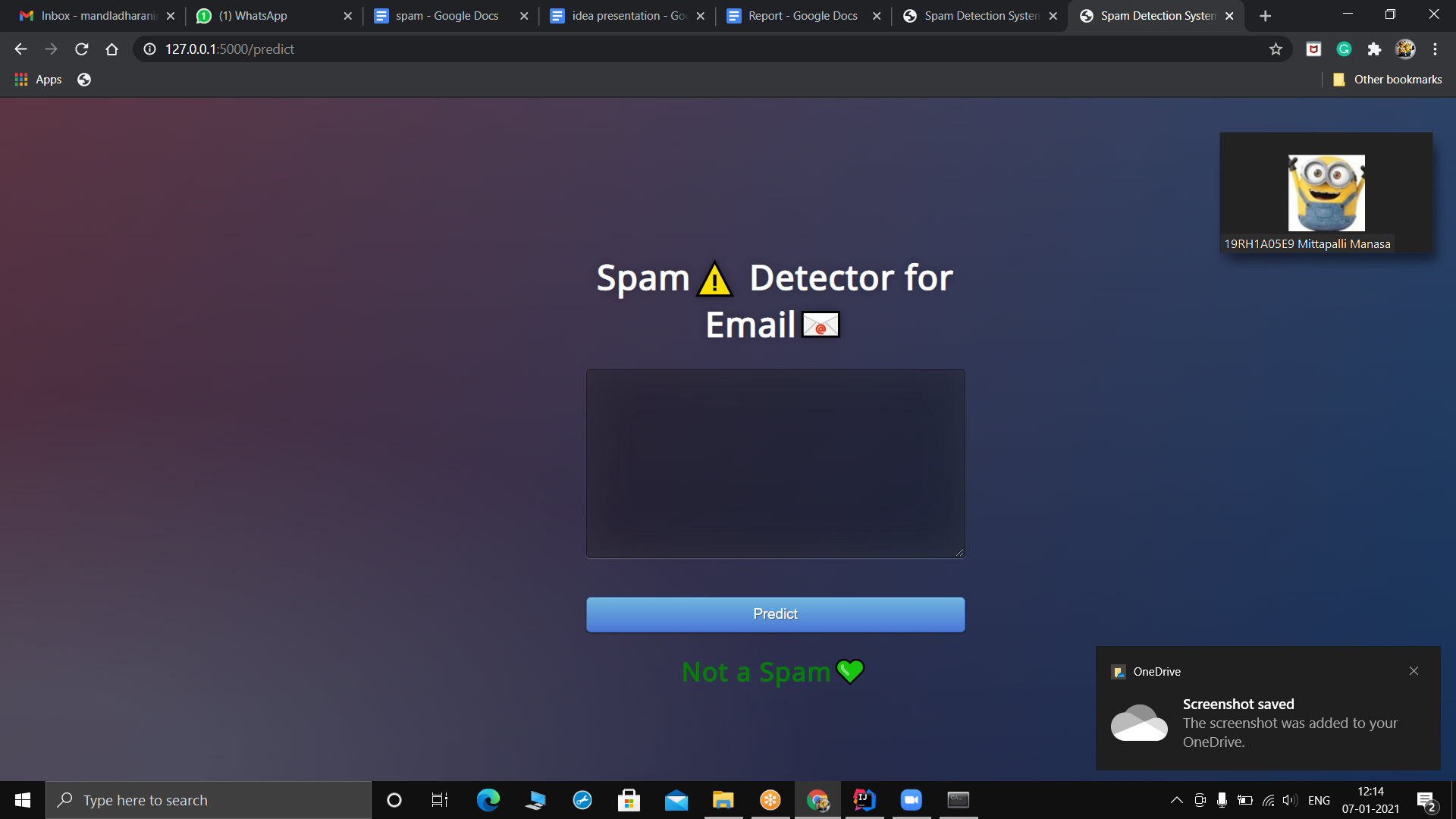
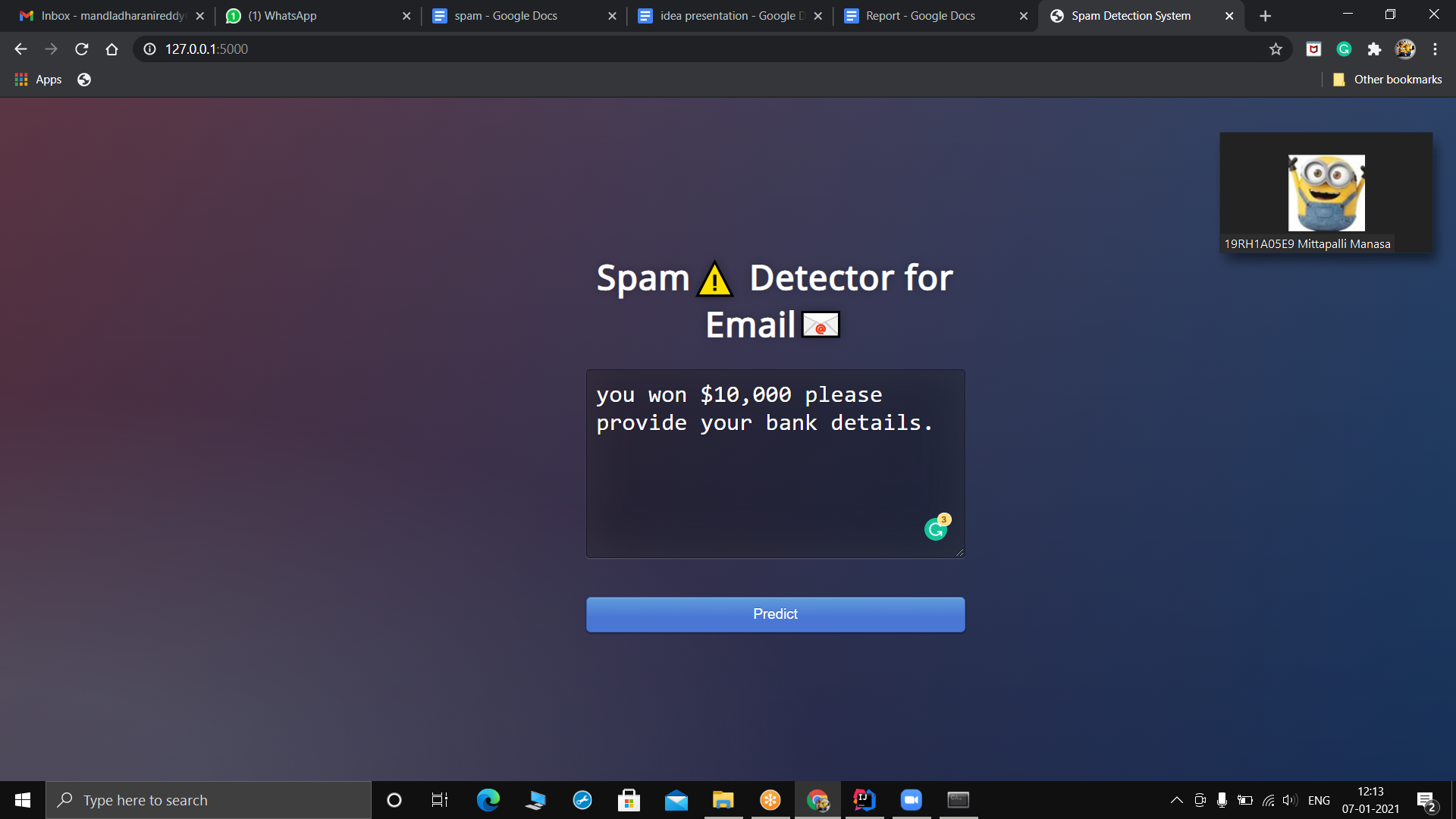
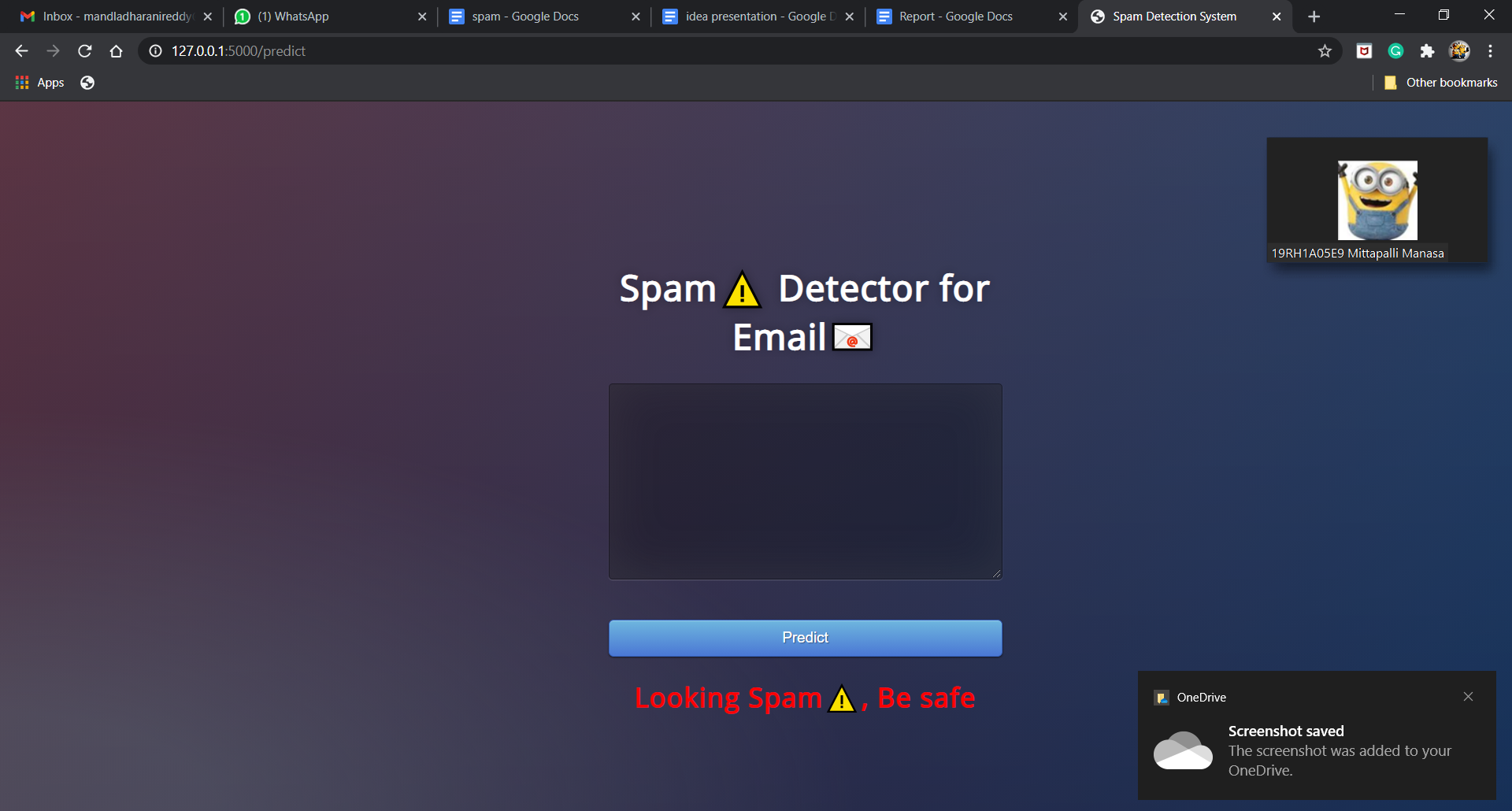
Problem: Email spam is also termed as junk email, these are suspicious messages sent in bulk through emails. Most of the email spam messages are commercial in nature. They contain links that look genuine and convincingly familiar however the links lead to phishing websites that host malware. Spam emails can be annoying for users, but they bring more issues and risks with them. Solution: Email spam detection in a logical, theoretically grounded manner, in order to facilitate the introduction of spam filtering techniques that could be operational in an efficient way. To effectively handle the threat posed by email spam, leading email providers have employed a combination of different machine learning (ML) techniques. All these tasks are done through Natural Language Processing (NLP), which processes text into useful insights that can be applied to future data. In the field of artificial intelligence, NLP is one of the most complex areas of research due to the fact that text data is contextual. It needs modification to make it machine-interpretable and requires multiple stages of processing for feature extraction. Model Overview: Let’s start with our spam detection data. We’ll be using the open-source Spambase dataset from the UCI machine learning repository, a dataset that contains 5569 emails, of which 745 are spam. The target variable for this dataset is ‘spam’ in which a spam email is mapped to 1 and anything else is mapped to 0. The target variable can be thought of as what you are trying to predict. In machine learning problems, the value of this variable will be modeled and predicted by other variables. Data usually comes from a variety of sources and often in different formats. For this reason, transforming your raw data is essential. However, this transformation is not a simple process, as text data often contain redundant and repetitive words. This means that processing the text data is the first step in our solution. The fundamental steps involved in text preprocessing are Cleaning the raw data Tokenizing the cleaned data. Feature extraction is a general term for methods of constructing combinations of the variables to get around these problems while still describing the data with sufficient accuracy. Many machine learning practitioners believe that properly optimized feature extraction is the key to effective model construction. In machine learning, scoring is the process of applying an algorithmic model built from a historical dataset to a new dataset in order to uncover practical insights that will help solve a business problem. Text processing is the automated process of analyzing text data for getting structured information. Text generation is a subfield of natural language processing. It leverages knowledge in computational linguistics and artificial intelligence to automatically generate natural language texts, which can satisfy certain communicative requirements. Model selection is the process of selecting one final machine learning model from among a collection of candidate machine learning models for a training dataset. Text data can be easily interpreted by humans. But for machines, reading and analyzing is a very complex task. To accomplish this task, we need to convert our text into a machine-understandable format. Embedding is the process of converting formatted text data into numerical values/vectors which a machine can interpret. Different performance metrics are used to evaluate different Machine Learning Algorithms. The key classification metrics: Accuracy, Recall, Precision, and F1- Score. metrics used to evaluate a classification model are an accuracy, precision, and recall. Accuracy is defined as the percentage of correct predictions for the test data. It can be calculated easily by dividing the number of correct predictions by the number of total predictions. Future works: We try to improve our model accuracy by improving feature extraction and then we try to detect spam emails in real-time. By comparing our metrics, accuracy,f-factor we improve our algorithm efficiency and we try to build an efficient spam filter.


Log in or sign up for Devpost to join the conversation.