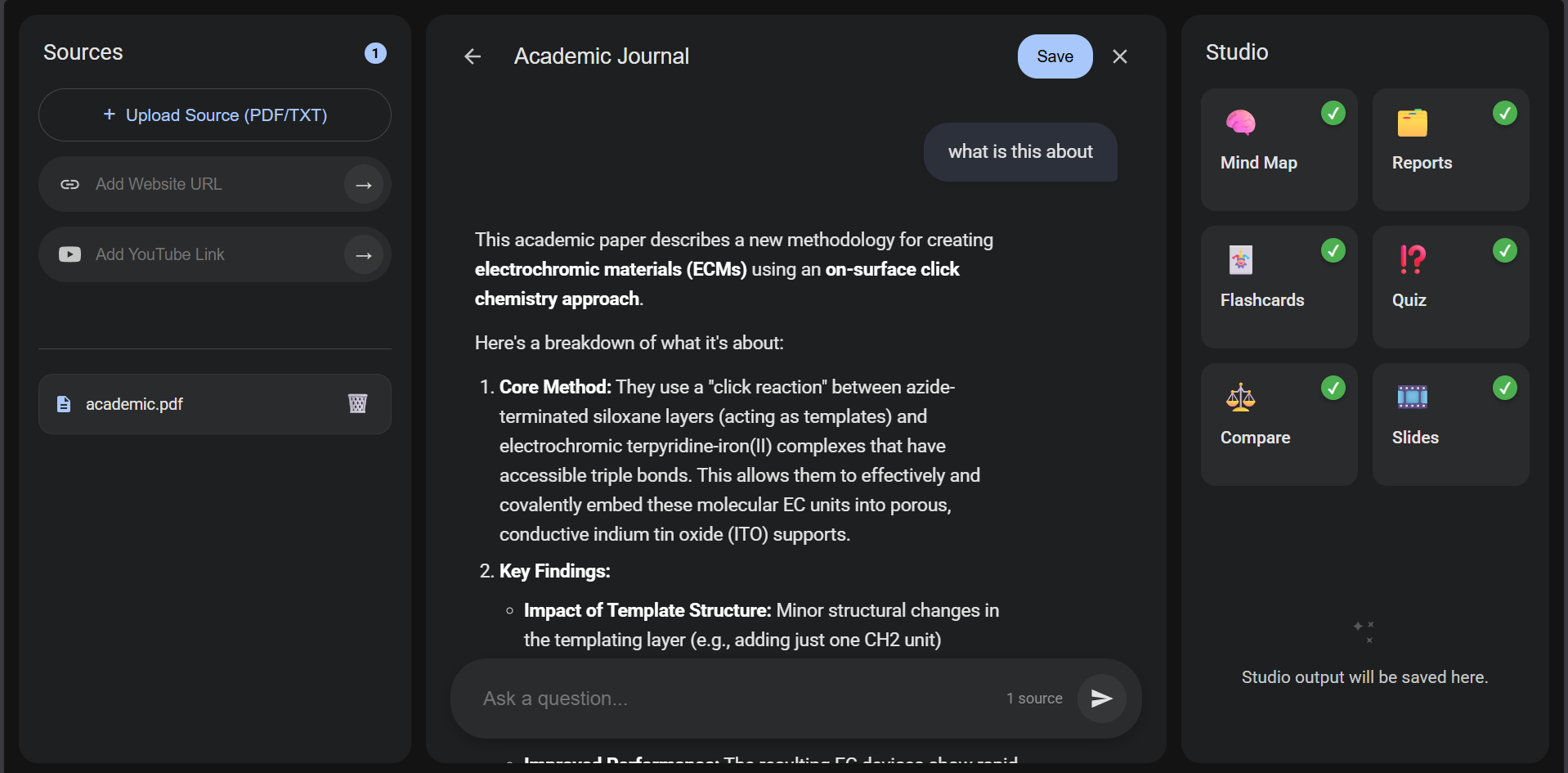
Inspiration
The Spark of Inspiration My inspiration for SourcebookLM stemmed from the frustration of managing and learning from the overwhelming amount of digital information across various formats (PDFs, web articles, YouTube videos). I envisioned an AI-powered "second brain" that could not only ingest diverse content but actively transform raw data into structured, actionable knowledge – generating mind maps, flashcards, or quizzes on demand. The goal was to make learning, research, and content organization significantly more efficient and insightful using generative AI.
Lessons Learned Along the Way Building SourcebookLM provided invaluable experience:
Full-Stack Development: Orchestrating backend APIs with Flask and interactive frontends with HTML, CSS, and JavaScript. Diverse Content Ingestion: Mastering text extraction from a wide array of sources like PDFs, DOCX, web pages, and YouTube transcripts. Generative AI Mastery: Deep dive into prompt engineering, context management, and generating structured outputs using the Google Gemini API. Database Design: Leveraging MongoDB's flexible document model for persistent storage of complex, hierarchical data. Interactive UI: Crafting dynamic user interfaces for tools like mind maps, quizzes, and real-time chat. The Construction Process SourcebookLM features a modular architecture:
Backend (Flask): Handles all API endpoints for notebook management, content processing, and AI tool interactions. AI Orchestration: Manages communication with the Google Gemini API for chat, structured content generation, and context awareness. Content Extraction: Integrates various libraries to extract text from files (PDF, DOCX, TXT, etc.), web URLs, and YouTube video transcripts. Persistent Storage (MongoDB): Stores all user data, including notebooks, sources, and AI interactions. Interactive Frontend: Built with HTML, CSS, and JavaScript, providing a seamless and dynamic user experience across all features. Overcoming the Hurdles Key challenges during development included:
Standardizing Diverse Inputs: Ensuring consistent, clean text extraction from heterogeneous sources for AI processing. Maintaining AI Context: Effectively managing conversation history and dynamically feeding relevant source content to the Gemini API while adhering to token limits. Reliable Structured AI Output: Consistently prompting the AI to generate specific data formats (e.g., JSON for mind maps, structured questions for quizzes). Frontend Complexity: Building responsive and intuitive interfaces for dynamic content visualization and interactive AI tools. Each challenge served as a valuable learning experience, contributing to SourcebookLM's robust design and functionality.


Log in or sign up for Devpost to join the conversation.