-
-
Whole picture!
Inspiration
Misinformation—both promoted deliberately and accidentally—is perhaps an inevitable part of the world in which we live and is not a new problem. However, we currently live in an era in which technology enables information to reach large audiences distributed across the globe, and thus the potential for immediate and widespread effects from misinformation now looms larger than in the past. Recent examples include the misinformation regarding COVID-19, Trump's tweets, and how Facebook handled the hate speech and misinformation regarding Rohingyas in Myanmar. In recent years, tech companies have been criticized for their role in the spread of misinformation and how they should take action against it. Furthermore, we also know that people judge source credibility as a cue in determining message acceptability and will turn to others for confirmation of the truth of a claim. The flow of misinformation on social media is thus a function of both human and technical factors. So what if we can bring both of these factors together in a way to minimize misinformation? A platform that is available for all and regulated by all but what you share is fact-checked by people whose credibility is dependant on their real expertise, skills, and previous credit and this is exactly what we want to try and build!
What it does
The Source to put it simply can be regarded as a mix of social media such as Twitter or Facebook and a community-driven and collaborative platform such as Wikipedia.
The main features of our first version consist of:
- Users can post and share news and facts in different categories.
- Categories are pre-defined by the system and examples include politics, health, sports, etc.
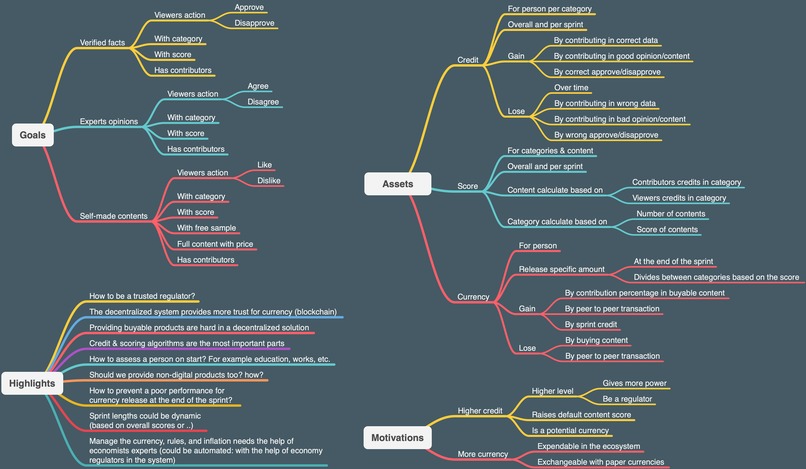
- Each post's credibility will be measured by users. Every user has a credit in each category and based on users' interaction with a post (the credit of the person posting it, approving/disapproving done by other users) the system will calculate a post's score (a measure for a post's credibility in our system). To get a better idea of the credit system, imagine something similar to StackOverflow.
- A post with a score above a specific number is considered a verified fact.
- The ultimate goal of the system is to show only the verified posts to users and thus, how the user's timeline is ordered or what kind of posts are considered more hot are all decided based on the post's score.
- Users will gain credits by making positive actions (post a correct fact, help measure the facts)
- Users will lose credits with negative actions (post a fake fact, approve a wrong fact)
- Being good at sports doesn't mean you also know more about the COVID-19! Users will have separate credibility in each category and thus having a high credit in one category doesn't mean your voice will reach a bigger audience in other categories.
How we built it
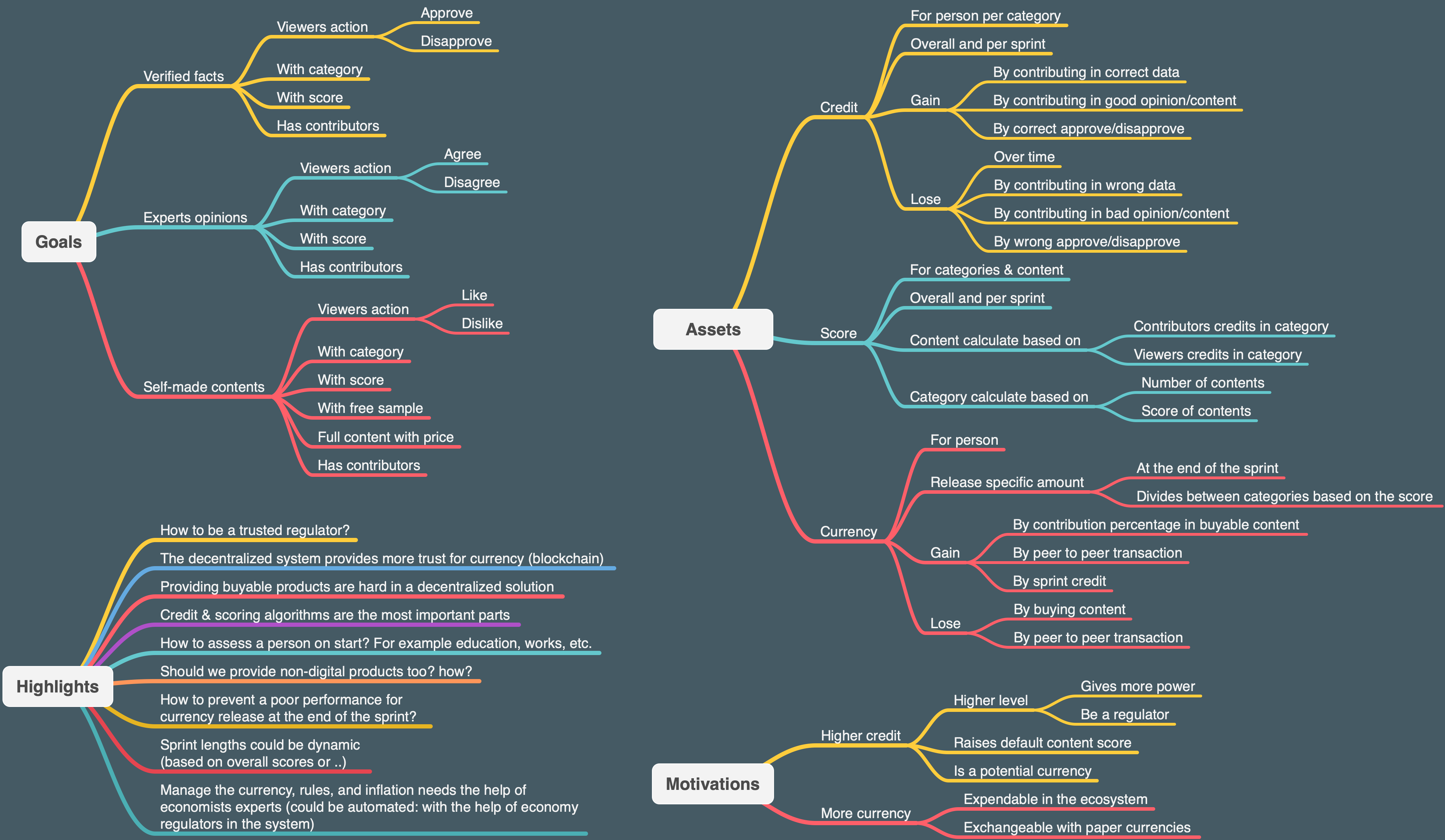
We first started by a simple social media in which users can join, login, post their facts/news, and see others' posts. We built this based on REST with Django and React-Native, Redux as our mobile state manager, and PostgreSQL as our primary database. Then we implemented the approve/disapprove for posts. Every user (except the author) can approve/disapprove the post. After this, we had the main APIs in place. In the next stage, we focused on our scoring and credit algorithms. A couple of scoring algorithms were tested against our test data. We implemented the best one for the first version which computes the score based on the author's credit, approvers credits, and disapprovers credits. This algorithm creates a separate cluster for each and finds the best mean between them. The score will be between -100 to 100. -100 means the fact is completely wrong, 0 means the fact is neutral, and 100 means the post is completely correct. We then sat the thresholds of >60 and <-60 for verified and unverified facts based on our tests. This helped us to build a training model based on logistic regression. This model trains its data against the verified and unverified facts and their authors and voters credits. This process is completely automated and online. Then it predicts the score of every fact to find the potentially correct and potentially wrong facts. In the end, we built our credit system. This system uses the user's posts and votes to evaluate the credit of the user. The algorithm is not based on training models. Also, we add the feature of "initial credit" for each user in each category. This helps us to boost the credit system. It should be filled by the user's degree, publications, previous works, etc.
Challenges we ran into
We had 3 main challenges:
- The scoring system is so complicated and so new. Every fact-checking publication and ML algorithms mostly focus on extracting the subject, object, and the claim and check them with the correct data from reliable sources. However in our case, we have our own credit for each source, and each source claims the falseness/correctness of the fact independently. So we should find out based on the sources credits the falseness/correctness factor of the fact.
- The credit system also updates with the scoring system and the actions of the users. These variables (user's score and user's posts credits) will be computed based on each other which adds more complexity to the system.
- How should we fill the "initial credit" automatically for each user? This is very dependent on every category, for example, we could use publications for the health category. But sites like Google Scholar have no open API, and cannot be used to verify the user's email.
Accomplishments that we're proud of
First of all, we managed to implement the first version of our MVP with only 2 people and in a short time. A social-network with scoring and credit systems and features. We are so proud of this. Also, we implemented some complex algorithms, design and implement a training model for predicting the post score, and automate the whole thing on the development stage (which is on Heroku). In the mobile, we also managed to implement the main features with minimal UI/UX just for showcasing.
Being rapid and have a working product is the most important thing to consider in a startup. In order to achieve it, we had to create a vision, break the epic stories, assign priorities to them, and plan every 6 hours for ourselves.
What we learned
We only realized the depth of the challenges of our idea when we started developing the system especially the challenge with determining the initial credit. Automating the training model on Heroku. Working with a tight deadline and designing the interface on spot.
What's next for Source
On the tech side, we need to improve the scoring and credit systems, gather more training data, and make our model better. Also, features like comments with different types of posts (facts, opinions, and self-made contents) will make the system more usable. We also think the system can produce digital currency based on the user's credits and which will be given to them at the end of each season. This currency is based on "Data", the more popular self-made content that you generate, the more currency you will receive. The more you spread the correct facts or help the system to determine the correct and wrong facts, you will receive more currency.
The whole picture can be explained by the product name, Source! Source of verified facts, Source of expert's opinions, Source of any type of self-made contents, and Source of your income.



Log in or sign up for Devpost to join the conversation.