-
-
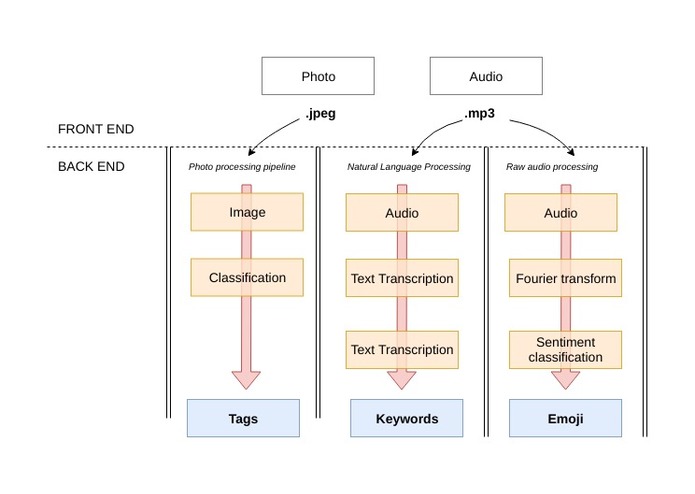
Processing pipelines
Inspiration
- Recently there is a surge is people using voice assistants such as Google Home or Alexa for almost everything, right from asking about the weather to ordering something on the internet. Though these devices capture the information that was being said, it fails to comprehend the real mood of the person. We feel it is important to capture the human emotions in their speech to give better services for the end customer.
- For reporters and journalists, it is much easier to report real time updates on events much faster and quicker.
- For wannabe actors / actresses, our emotion recognition / prediction model can help them improve their acting skills by improving and improving their emotional skills.
What it does
- Understand the mood of the speaker via deep learning classification
- Transcribes voice input as text using Google speech-to-text API
- Summarizes the voice input using sequence to sequence modelling and gives a short snippet which the user, including relevant hashtags that one can post it on social media, including a short smiley based on his/her mood
- Chooses a an image based on the voice content and mood, including the corresponding tags for images ( Not implemented due to lack of time )
How I built it
- Speech Recognition - Google speech-to-text API to recognize speech
- Emotion recognition from speech - We trained our own deep learning model to predict emotions based on the way the speaker sounds
- Text summarization - We trained a sequence to sequence model to summarize the spoken text into a couple of sentences. Used Cotentpool API for getting news sources
Challenges I ran into
- There were not much available labelled dataset for except Berlin emotions dataset and the Ryerson audio-visual dataset. These datasets had some limitations such as the number of spoken sentences and the number of different speakers. So, we had to build our model based on the existing dataset.
- We tried to build our own dataset for emotion recognition, but we were not as good as the actors/actresses from the dataset in expressing our emotions. So, we felt our dataset will add in more noise rather than trying to improve our model accuracy.
- Streaming audio data and processing the sound data over the web server was difficult because of incorrect byte format that was used during streaming and reading the streamed chunks
Accomplishments that I'm proud of
- State of the art accuracy in predicting emotions. Much better than expected after struggling a lot with feature engineering
- Some of us started learning natural language processing and was able to summarize a long speech to a condensed snippet.
- We could integrate multiple machine learning models and after one full day of hackathon, we are very proud with our final project.
- Getting a python Flask web app deployed on a Google Cloud instance for REST API interfacing
What I learned
- Some of us enhanced our natural language processing skills, learnt new machine learning frameworks
- The benefits of collaboration with like-minded people
What's next for Souns
- Get more data and improve our accuracy of the model
- Implementing the combination of text and image processing to easily post your ideas on social media.
Built With
- contentpool-api
- flask
- google-web-speech-api
- java
- javascript
- keras
- librosa
- numpy
- python
- scipy
- tensorflow
- webflow




Log in or sign up for Devpost to join the conversation.