-

SoundSage
-
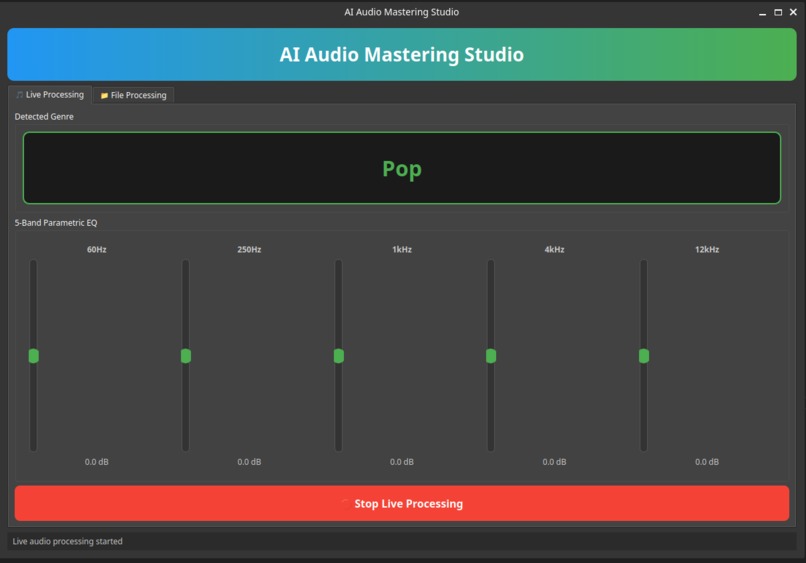
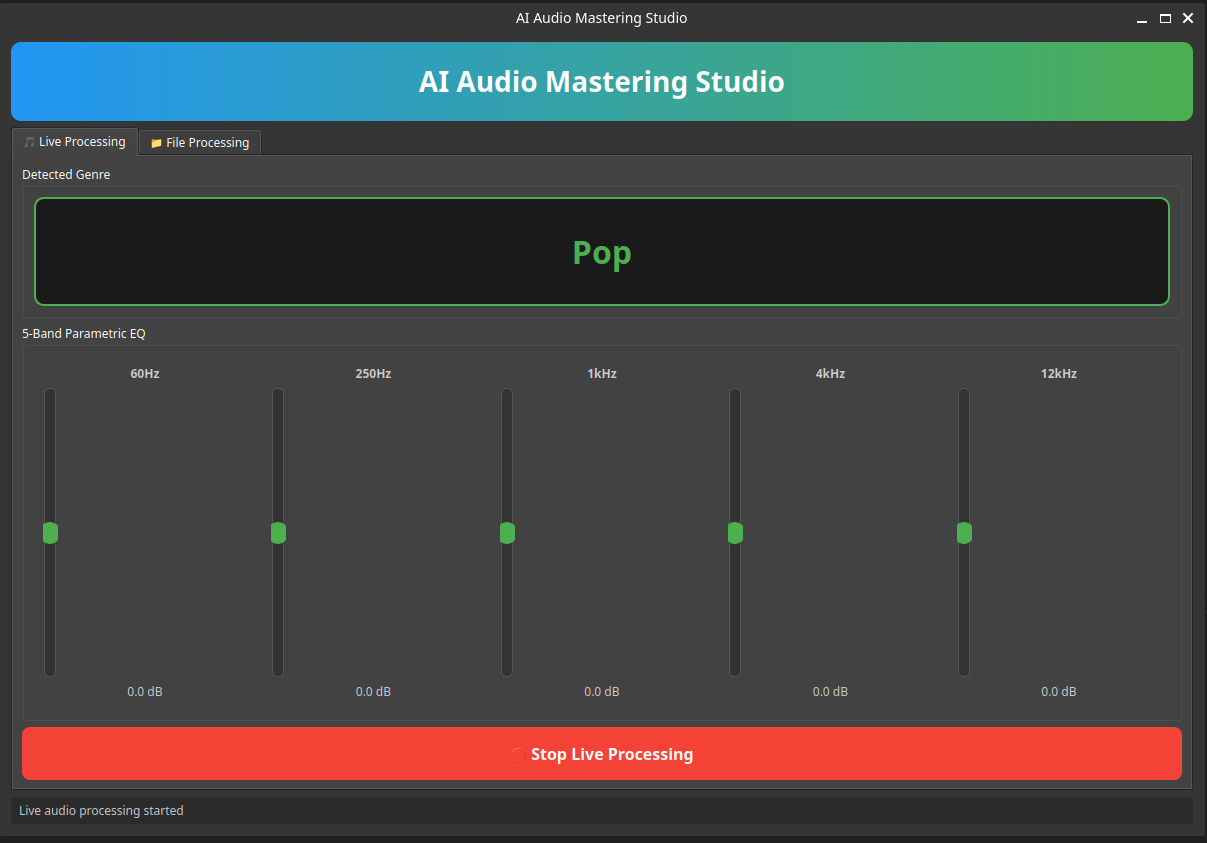
Live Genre and EQ version 1.0
-
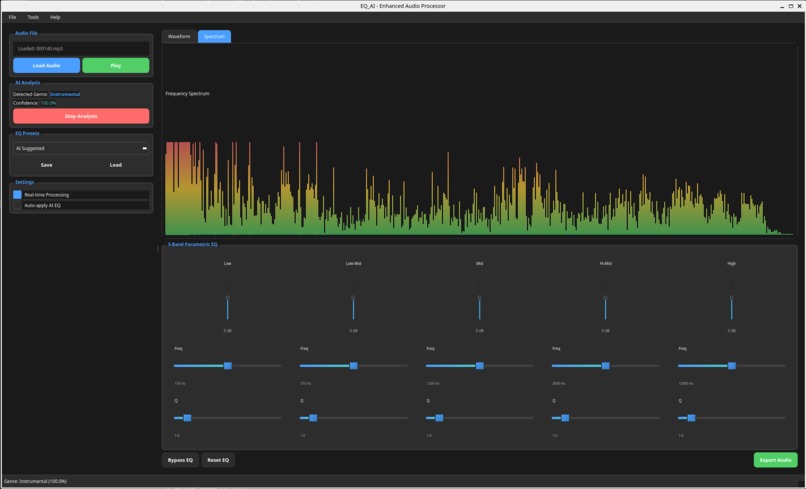
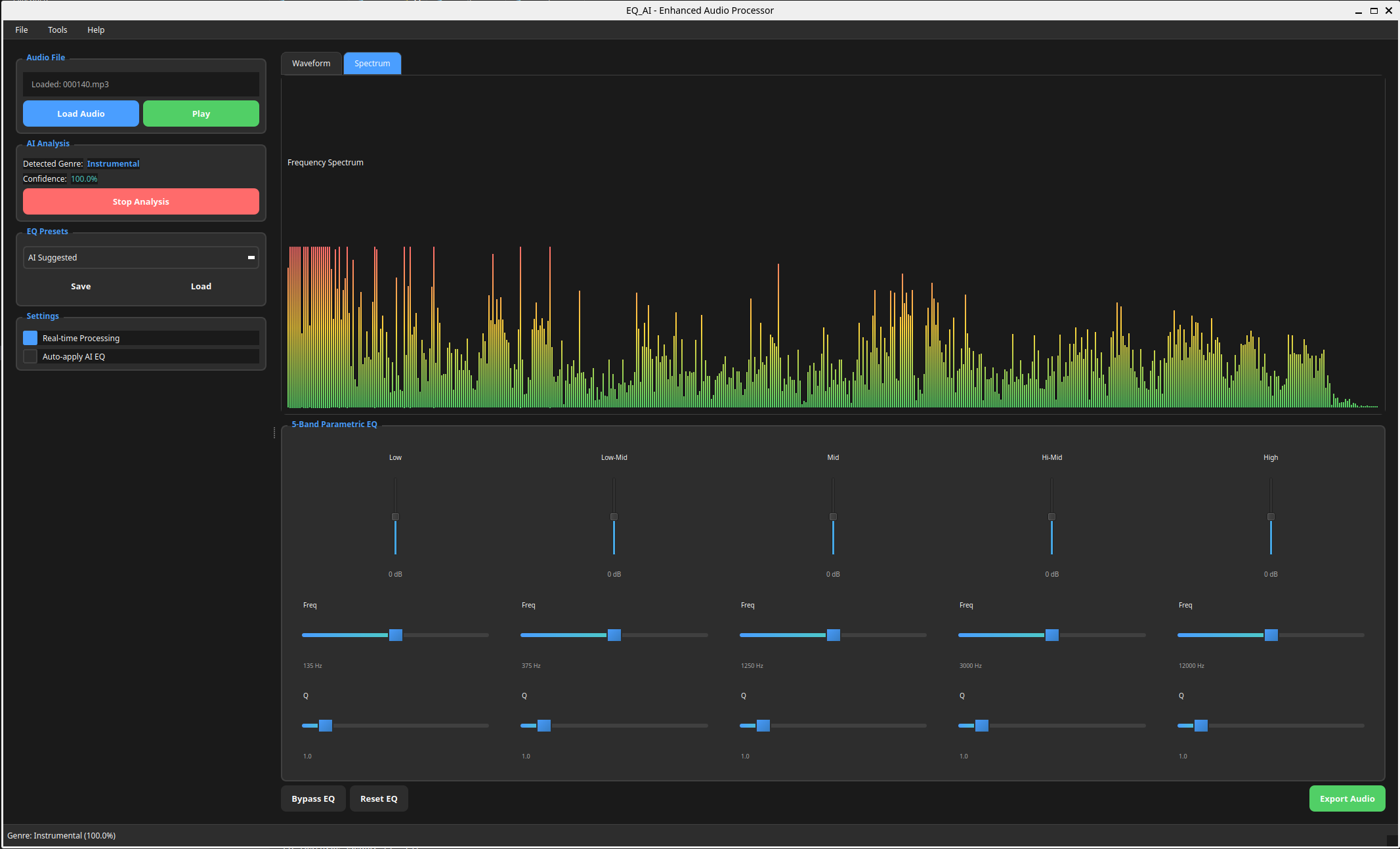
Live Genre and EQ version 1.1

Inspiration
We were frustrated with the limitations of current music systems - generic EQ presets that don't adapt to specific songs, cloud-dependent analysis that compromises privacy, and genre classification systems biased toward popular music. We envisioned an intelligent system that could understand music like a professional sound engineer and enhance it in real-time, all while running locally on efficient hardware.
What it does
SoundSage is a dual-AI system that instantly identifies music genres and automatically optimizes your audio experience. The first model analyzes audio features to detect the genre, while the second model intelligently adjusts EQ settings tailored to that specific genre. Everything runs locally on MemryX NPU hardware, delivering studio-quality audio enhancement without cloud dependency or privacy concerns.
How we built it
Data Pipeline:
- Processed 22,000+ audio clips from the FMA dataset
- Extracted 80+ audio features (MFCC, spectral, tempo, chroma)
- Implemented strategic class balancing (8 genres × 1,000 samples each)
- Used ANOVA F-test to select the 60 most relevant features
Model Development:
- Built dual neural networks in PyTorch
- Genre model: 60 → 256 → 128 → 64 → 8 architecture
- EQ model: Genre-aware parameter optimization
- Trained on Modal with GPU acceleration
Deployment:
- Converted models to ONNX format
- Optimized for MemryX NPU using DFP file format
- Implemented real-time audio processing pipeline
Challenges we ran into
Data Imbalance: Original genre distribution was highly skewed (some genres had 7,000+ samples, others only 100). Our initial models were biased toward majority classes.
Feature Selection: Determining which of the 80+ audio features were most relevant for genre classification required extensive testing and ANOVA analysis.
Hardware Optimization: Converting our models to run efficiently on MemryX NPU with DFP format presented unexpected compatibility challenges.
Real-time Performance: Achieving <5ms inference time while maintaining accuracy required significant architectural optimization and pruning.
Accomplishments that we're proud of
- World's First: Created the first real-time dual-model music intelligence system on NPU hardware
- Perfect Balance: Successfully balanced 8 genres with 1,000 samples each, eliminating classification bias
- Hardware Integration: Achieved seamless deployment on MemryX NPU with DFP format
- Performance: Reached >85% genre accuracy with <5ms latency
- Privacy-First: Built a fully local system that processes audio without cloud dependency
What we learned
- Balanced data beats complex models: Simple architectures with balanced data outperform complex models with imbalanced data
- Feature selection is crucial: 60 well-chosen features outperformed 80+ generic features
- Hardware-aware design: Model architecture must consider target deployment hardware from day one
- Regularization diversity: Combining dropout, weight decay, and label smoothing provides robust generalization
- Edge optimization: ONNX to DFP conversion requires careful attention to operator compatibility
What's next for SoundSage
Short-term (3-6 months):
- Expand to 16+ genre classifications
- Develop mobile SDK for Android and iOS
- Integrate with popular music streaming apps
Medium-term (6-12 months):
- Personalization engine that learns individual listening preferences
- Multi-modal analysis combining audio with metadata and lyrics
- Real-time audio effect chain beyond basic EQ
Long-term (12+ months):
- AI-powered music composition assistance
- Cross-platform plugin ecosystem
- Enterprise solutions for broadcast and live sound
- Open-source community edition for developers
We're just getting started on our mission to make intelligent audio enhancement accessible to everyone, everywhere.
Built With
- memryx
- onnx
- python
- torch


Log in or sign up for Devpost to join the conversation.