-
-

Start Page
-
Standby
-
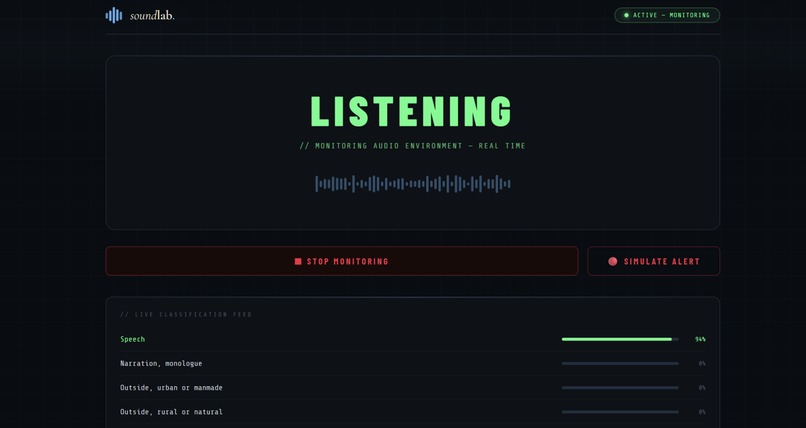
Monitoring Audio
-
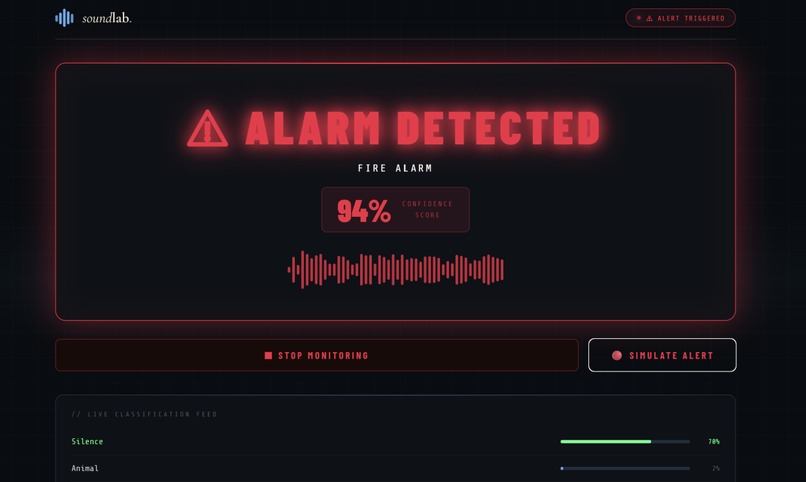
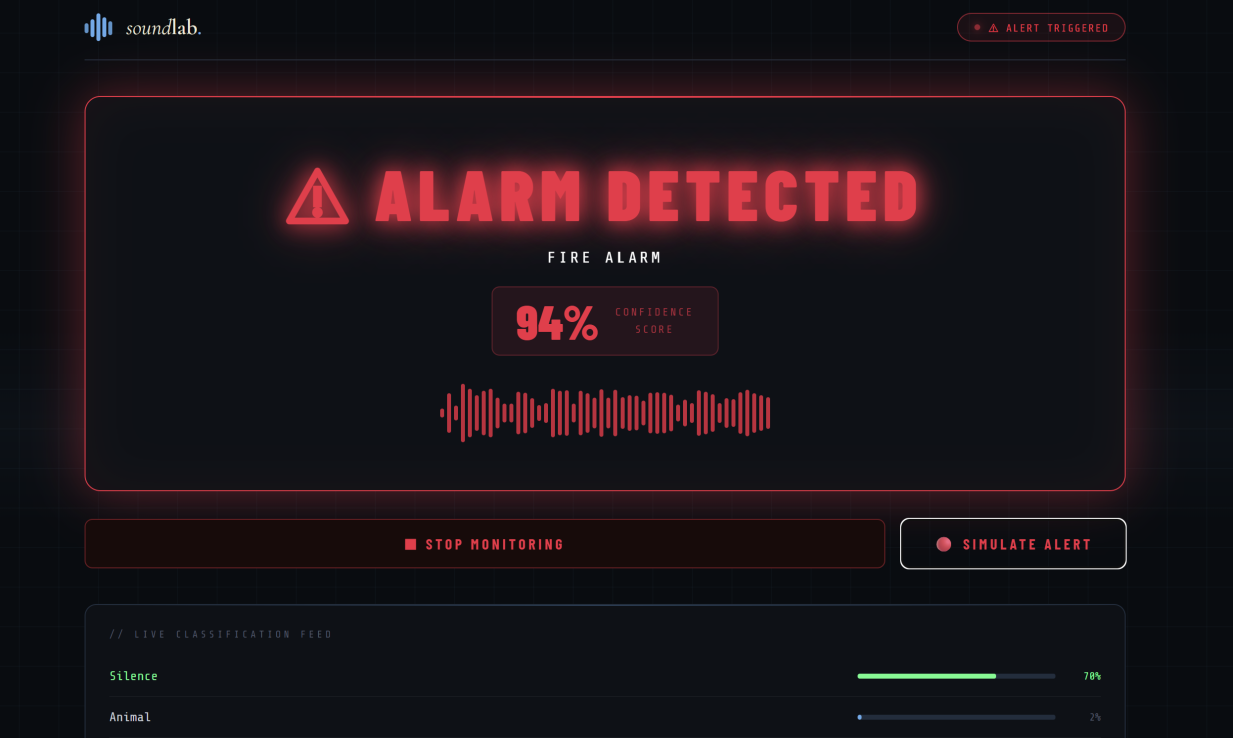
Alarm Triggered


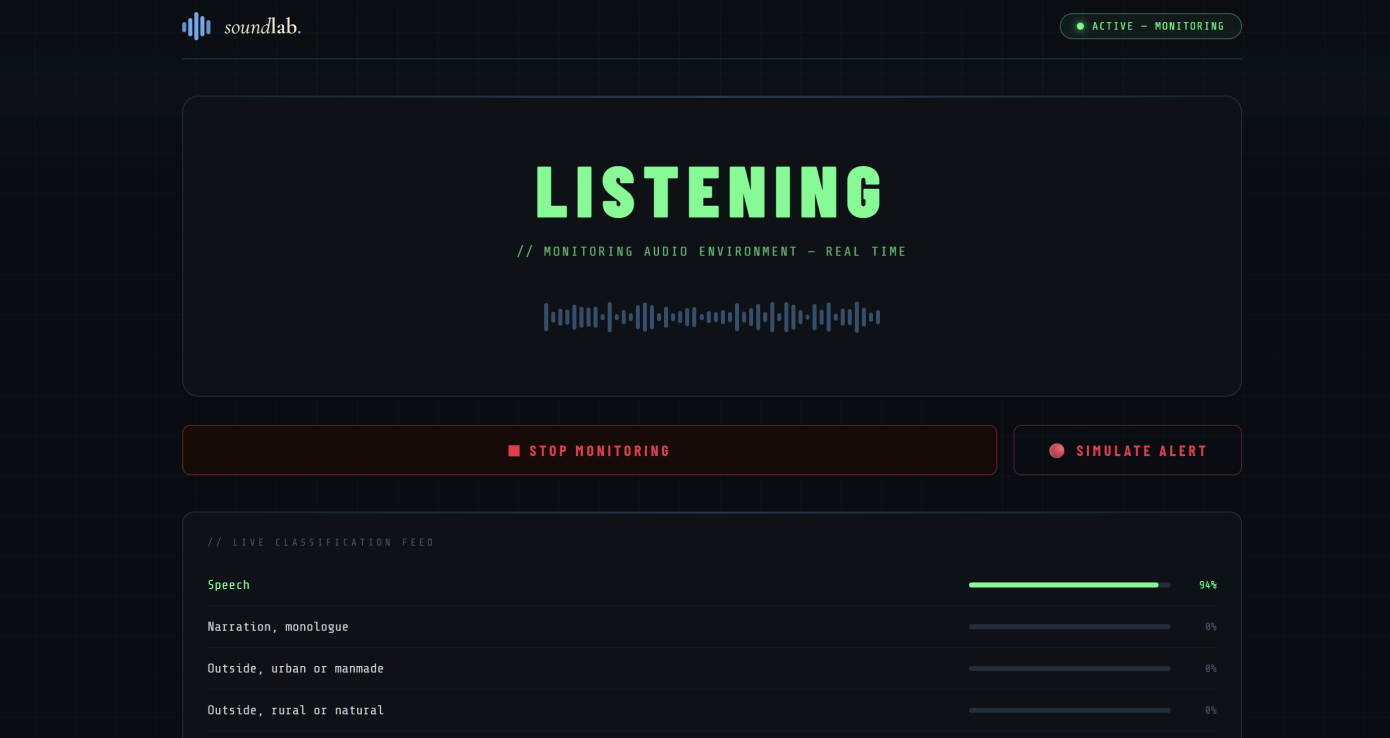
Inspiration
Noise-canceling headphones are amazing for focus but they create a dangerous disconnect to the outside world. Imagine a scenario where someone with noise cancelling headphones is listening to loud music, there is a high chance that they fail to recognize the emergency and may succumb to it. We wanted to build a safety application that allows users to stay focused without compromising their physical safety while maintaining the immersive experience of modern audio technology.
What it does
Our software acts as an intelligent audio monitor, constantly running in the background. It continuously monitors microphone input for specific emergency sound signatures, such as fire alarms and sirens. When a hazard is detected, the software overrides the user's current audio state by initiating a multi-threaded interrupt. This safety protocol instantly mutes all other Windows applications and plays a warning audio for 15 seconds, therefore delivering a clear alert so the user can react to the danger immediately.
How we built it
Coming into this hackathon with primarily academic Java expertise, we had to adapt quickly and chose Python for its AI and audio processing ecosystems. Our core detection engine is powered by TensorFlow and Google's pre-trained YAMNet model for audio classification. To ensure high accuracy and reduce false positives (especially from vocal harmonics), we engineered a custom audio processing pipeline before the AI stage step. aUsing a FFT Veto Gate, we then convert our time domain signal into the frequency domain using a Discrete Fourier Transform (DFT) to isolate the peak frequency. If the peak frequency is 800 Hz or less, the gate drops the signal, preventing human speech from triggering a false alarm. Then using a Bandpass Filter, the raw audio stream is first restricted to the 2kHz–4kHz range where most emergency alarms sit. Only the high probability audio is passed to YAMNet. If the threshold for an emergency sound is met, our custom Windows audio interrupt script takes over.
Challenges we ran into
This was our first time building a complete functioning product from scratch as a group together. Translating our academic foundation in Java and object-oriented programming into a dynamic Python environment while managing continuous data streams was a steep learning curve. Fine-tuning the FFT Veto Gate to distinguish between a high-pitched voice and a legitimate alarm signal required extensive testing. Moreover, managing the multi-threaded interrupt to safely control the Windows OS volume without crashing the main listening loop was a major technical hurdle we had to overcome.
Accomplishments that we're proud of
We successfully built a real-time, AI driven safety protocol in just 24 hours. Designing the Bandpass and FFT filtering architecture to reliably eliminate false positives was a massive win for the stability of our system. Most importantly, we proved to ourselves that we could take a concept, learn entirely new frameworks on the go, and deliver a working minimum viable product.
What we learned
We learned the immense value of prototyping and how to use AI tools to speed up our development process. We gained our first hands on experience with continuous data streams and integrating pre-trained machine learning models into a live application. We also learned how crucial teamwork, structured delegation, and strict timelines are when the clock is ticking.
What's next for SoundLab
We want to package this into a standalone desktop application with a polished user interface. We also plan to expand the AI model's training to recognize a wider array of hazard sounds and eventually port the protocol to mobile devices and other operating systems like macOS, Linux, etc.
Built With
- digital-signal-processing
- machine-learning
- numpy
- pyaudio
- python
- scipy
- tensorflow
- windows-api
- yamnet

Log in or sign up for Devpost to join the conversation.