Inspiration
Researchers are increasingly using recorded sound to understand the characteristics of an environment and how it changes over time. An example might be analyzing the occurrences of a certain bird call to learn about the effects of climate change on biodiversity. We thought we would make this traditionally tedious process of counting sound events a little easier.
What it does
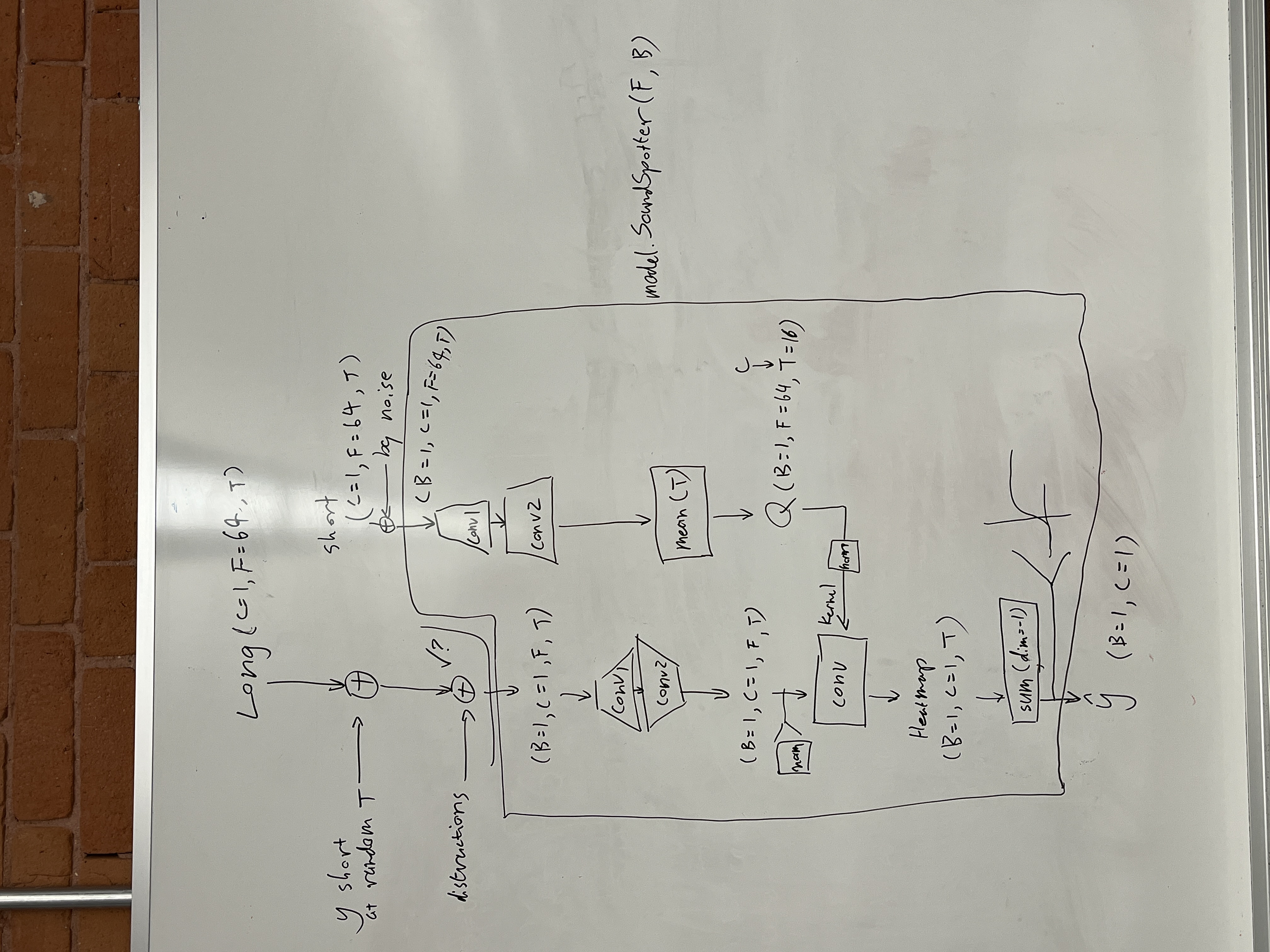
The model takes in a long audio clip and a short example of the type of sound you want it to track (e.g. a cough). It counts the occurrences of this type of sound (e.g. someone coughs 4 times within the duration of the clip) using convolutional layers and a sliding query.
How we built it
The model, training, and data processing are all written in Python with PyTorch. We spent 3 hours on the planning phase, which included designing the model architecture and data pipeline. Some model design choices (such as the summation at the end and the feature depth in the convolutional layers) were made with the help of ChatGPT 4o. Training data was synthetically generated using environmental sounds and sound effects from these two public datasets:
- Ambient Noise by José H. Solórzano (https://www.kaggle.com/datasets/solorzano/ambient-noise)
- ESC-50 by Karol Piczak (https://github.com/karolpiczak/ESC-50)
Challenges we ran into
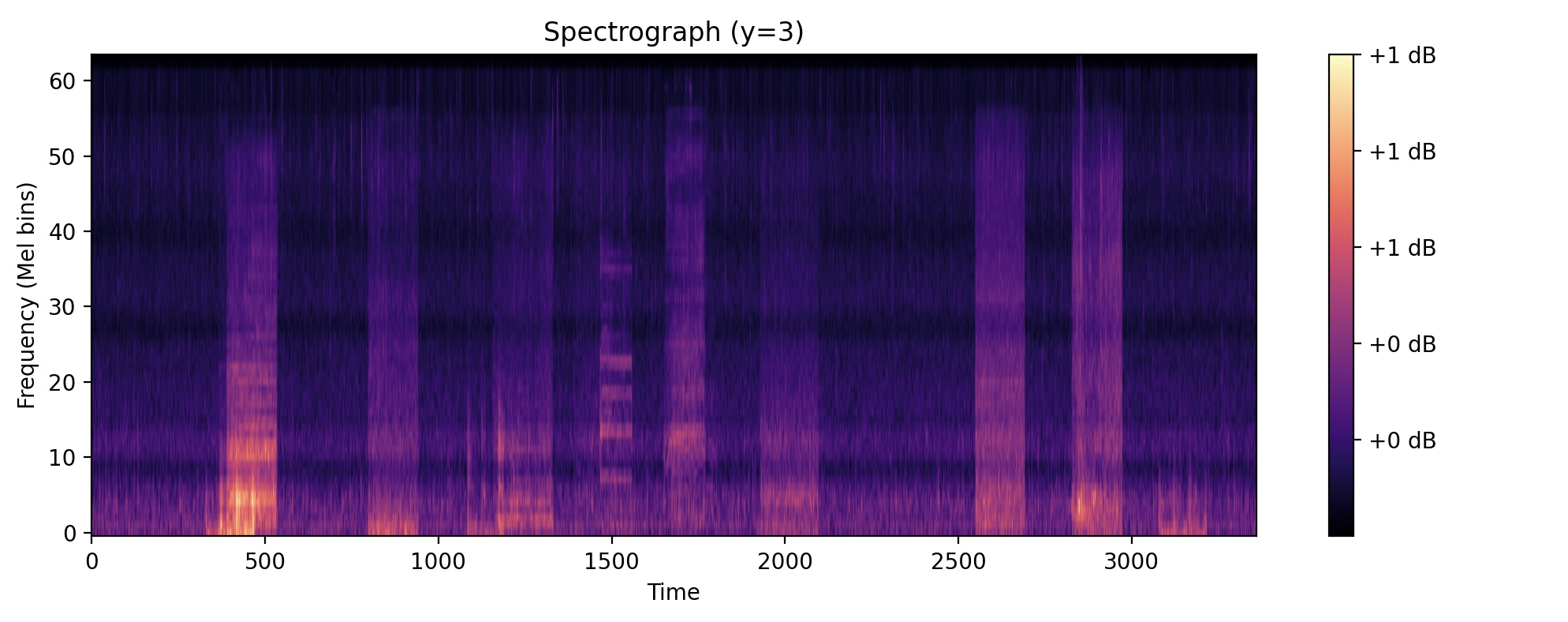
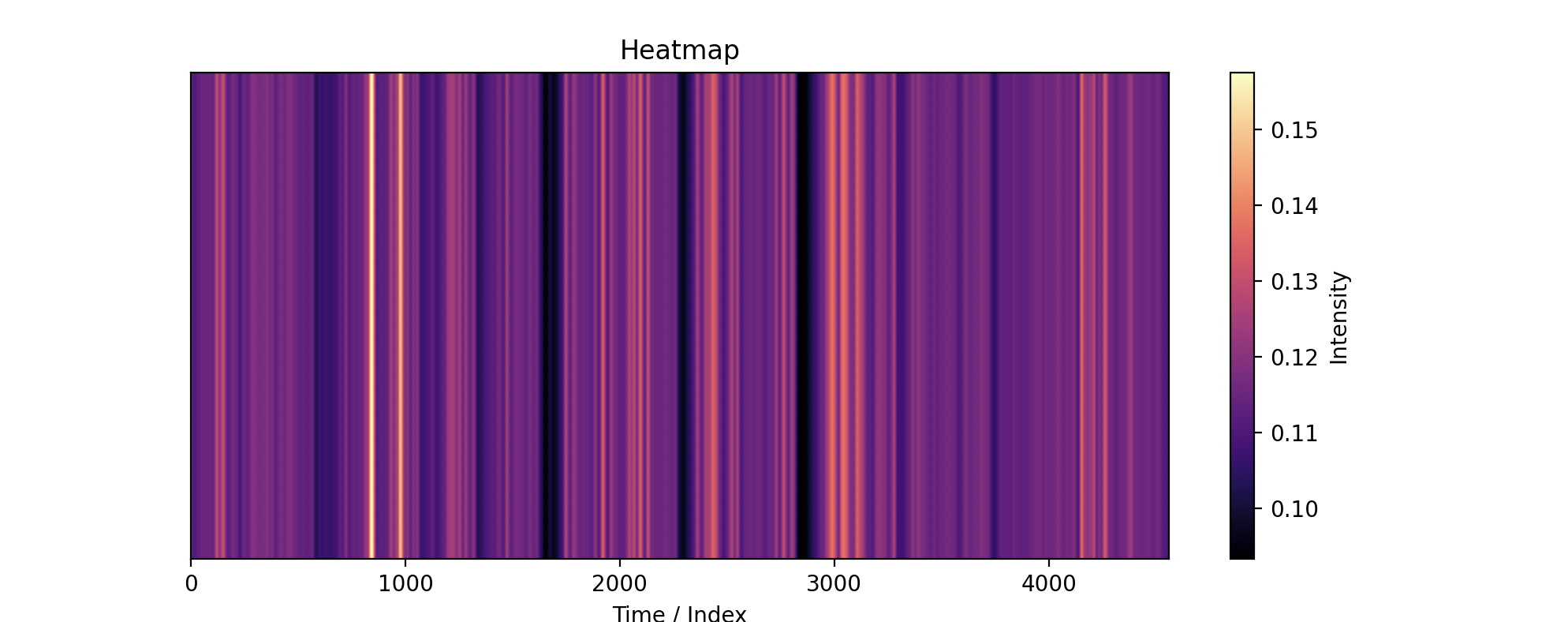
The "black box" nature of neural nets really showed here. We expected the heat map before the last layer of the model to indicate the presence of the example sound with respect to time. However, there turned out not to be much correlation between the two, which might mean that our model has found other ways to solve the problem. It was also a little tedious and confusing at first to keep track of the two audio formats: wave vs. spectrogram. Eventually, it helped to be really specific about the input and output types of our helper functions.
Accomplishments that we're proud of
This model is quite complicated compared to what we have worked on, but we managed to write most of the code within 12 hours with just 2 people! It performs fairly well on simple real-world datasets.
What we learned
We learned a lot about the different methods of processing audio tensors and generating synthetic data, as well as some new layers that we didn't know you could add to a neural net.
What's next for Sound Spotter
Increasing the size and diversity of our synthetic dataset would greatly improve the generalization abilities in practical tasks.






Log in or sign up for Devpost to join the conversation.