-
-
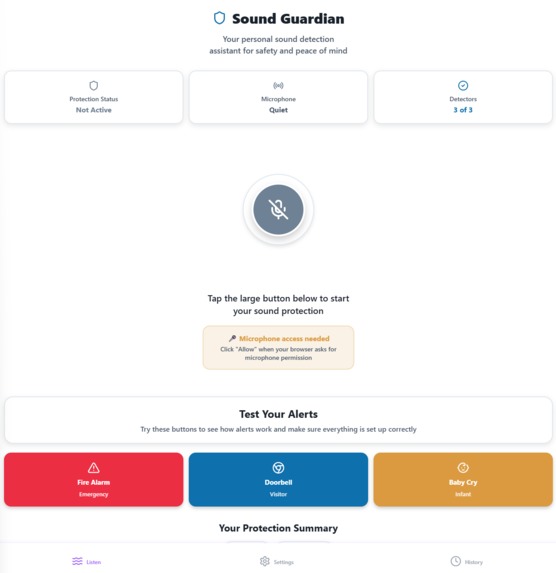
Main
-

Alert
-
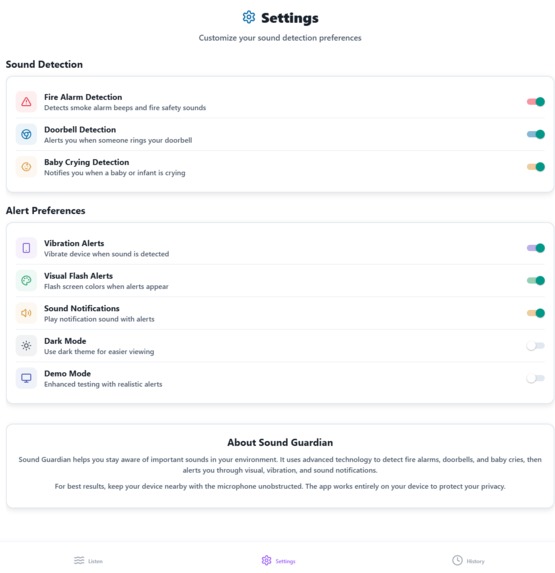
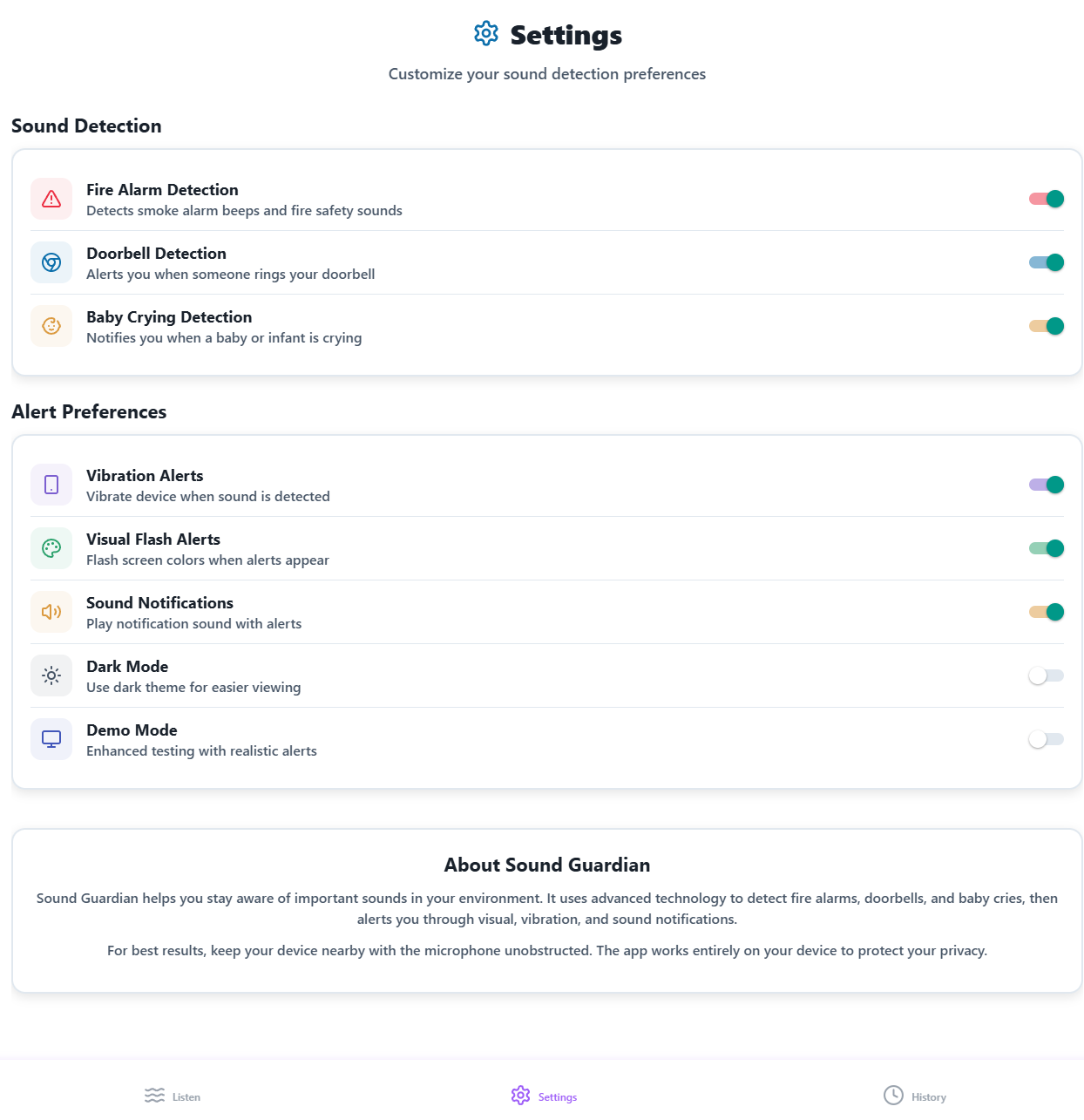
Settings
-
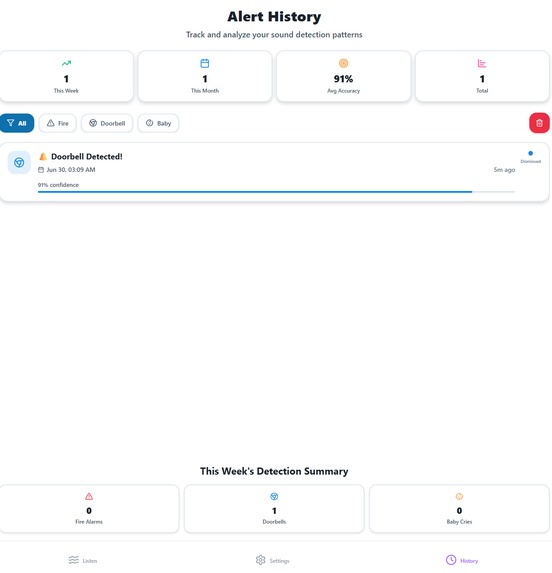
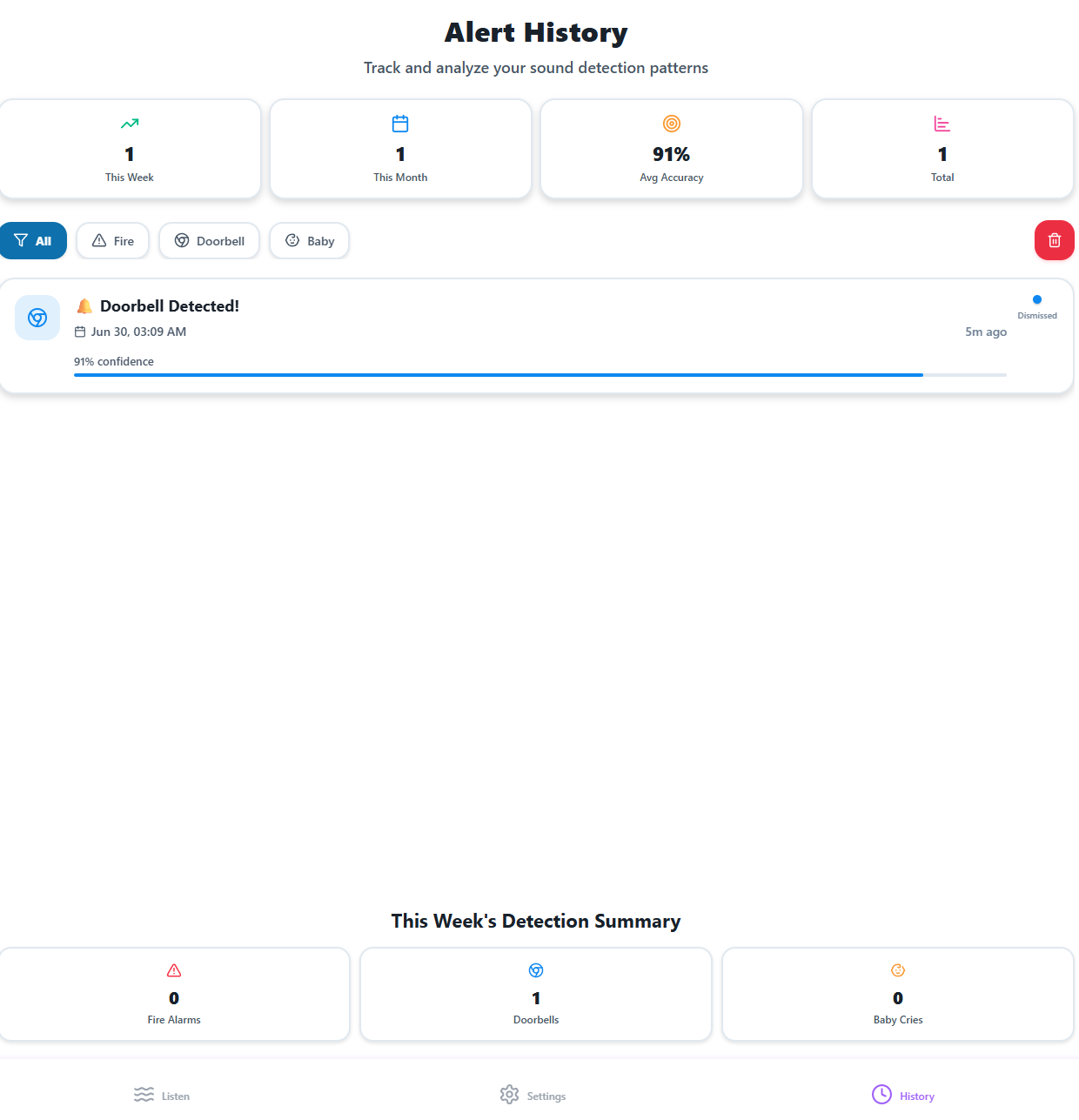
History

Inspiration
The inspiration for Sound Guardian came from a personal realization: millions of people with hearing impairments live alone and may not hear critical environmental sounds like fire alarms or doorbells. Similarly, busy parents often struggle to respond quickly to a crying baby while multitasking. Most existing solutions either require expensive IoT hardware or compromise user privacy by streaming audio to the cloud. We wanted to create something better—affordable, accessible, and respectful of privacy.
What I Built
Sound Guardian is a real-time sound detection assistant built entirely with web technologies. It identifies three key sounds—fire alarms, doorbells, and baby cries—using on-device machine learning. The app runs fully in the browser, delivering alerts via visual flashing, vibration, and optional sound, without uploading a single byte of audio data.
Key components include:
- A custom audio classification pipeline using MFCCs + TensorFlow.js.
- Expo/React Native Web architecture for cross-platform compatibility.
- An intuitive UI with toggleable alert types and confidence analytics.
How I Built It
We started with a React Native + Expo Router framework and extended it for web deployment via Netlify. The sound recognition model was trained and optimized in TensorFlow.js to ensure efficient, low-latency inference directly in the browser.
The project uses:
- Expo SDK 53 / React Native Web for cross-platform UI
- Web Audio API for real-time audio capture
- TensorFlow.js for sound classification (MFCC-based)
- Reanimated 3 for dynamic visual feedback
- Netlify for one-click static hosting
The UI is fully keyboard-navigable and accessible, with configurable alerts for each sound type.
Challenges I Faced
- Web limitations: Implementing real-time sound detection in-browser while preserving performance was difficult.
- Animation conflicts: React Native Reanimated 3 had rendering issues with React 18 on the web, causing runtime errors.
- Expo Router quirks: Expo Router + static export required careful routing structure to avoid hydration errors.
- Training the model: Balancing size, accuracy, and inference speed for a browser-based model was tricky.
What I Learned
- How to implement privacy-first sound classification without server-side processing.
- How to deploy cross-platform apps using Expo + Netlify.
- Fine-tuning UI/UX for accessibility and clarity, especially for users with auditory impairments.
- Deeper understanding of animation lifecycles and memory management in hybrid React/React Native environments.
What's Next
- Add custom sound training (e.g., pets, timers).
- Offline PWA support for full native-like functionality.
- Expand history and analytics for long-term usage tracking.
- Multilingual accessibility and voice-over integration.
Built With
- context-api
- expo-router
- expo-sdk-53
- netlify.
- react-native-web
- reanimated-3
- tensorflow.js
- typescript
- web-audio-api

Log in or sign up for Devpost to join the conversation.