-
-

Poster Presentation!
-
-


Sound Classification for Hazardous Environmental Sound
Final Writeup: https://docs.google.com/document/d/12B52WLIKm95Q410JS_OTwclFybrRWl8ro4igjsAxbQ0/edit?usp=sharing
Poster Presentation Link (higher quality PDF): https://drive.google.com/file/d/1B9YzE2khYVcM3XuqOYg4pHeZnbbinnZh/view?usp=sharing
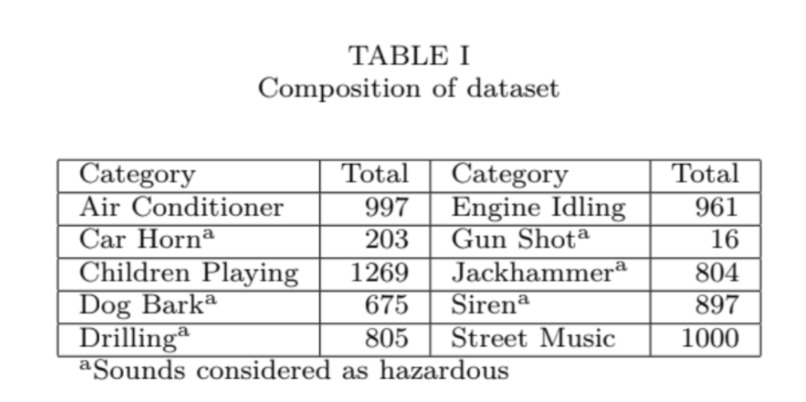
We will be reimplementing a paper on sound classification using several networks: a triple-layer LSTM, a CNN + LSTM combined network, and an ensemble network to classify environmental sounds as hazardous or non-hazardous. The 10 classes of sounds that we will be employing this model on are air conditioner, car horn, children playing, dog bark, drilling, engine idling, gun shot, jackhammer, siren, and street music. This model could be used to help the hard-of-hearing or deaf classify environmental sounds, using the Urbansound8K dataset (8732 labeled sound excerpts under 4 seconds each).
Who: Names and Logins
Leila: lkim30, Github: leilankim
Mel: mcui5, Github: mcui5
Mary: mlou2, Github: mylou6688
Yasmin: ykarasu, Github: KarasuY
Github Link: https://github.com/mcui5/dl-final
Introduction: What problem are you trying to solve and why?
"Deep Learning-Based Hazardous Sound Classification for the Hard of Hearing and Deaf" (Suh, Seo, Kim 2018) attempts to create a model (and real-life hardware) that uses deep learning to identify hazardous sounds for people with hearing impairments. We chose this paper because it is an interesting classification problem and has the potential to have a positive impact for people with hearing difficulties.
This problem is a supervised learning classification problem that uses LSTM and CNN models. We will classify the sound files from the Urbansound8k dataset into one of 10 categories, which are intended to be sounds that are either non-dangerous or dangerous. Sound categories: (air conditioner, car horn, children playing, dog bark, drilling, engine idling, gun shot, jackhammer, siren, and street music).
Related Work:
Medium article: https://medium.com/@mikesmales/sound-classification-using-deep-learning-8bc2aa1990b7
Summary: Using a similar method to paper, this implementation uses 4 conv2d layers sequentially and 72 epochs to train. Accuracy 92% in testing and 98% in training. Code for implementation available using scikit learn library.
More preprocessing information:
https://towardsdatascience.com/how-to-apply-machine-learning-and-deep-learning-methods-to-audio-analysis-615e286fcbbc
https://towardsdatascience.com/urban-sound-classification-with-librosa-nuanced-cross-validation-5b5eb3d9ee30
https://medium.com/@anonyomous.ut.grad.student/building-an-audio-classifier-f7c4603aa989
https://towardsdatascience.com/extract-features-of-music-75a3f9bc265d
Extract Features code reference: https://gist.github.com/mikesmales/aafd09846c3c21f0997af57154b8ba8c#file-feature_extraction-py
Note: There are also a few publicly available implementations of preprocessing for sound data (e.g. turning .wav files into spectrograms, and if we reference any of them we will make sure to include that later!). Below is an example of one that we found: https://github.com/keunwoochoi/UrbanSound8K-preprocessing
Data: Urbansound8K Dataset
We will be using the Urbansound8k dataset, a dataset with 8732 labeled sound excerpts of hazardous and non-hazardous urban sounds, with a total of 10 classes. There is significant preprocessing required for this project; we will need to read in the sound data and extract 5 different features from each sound (). These features will be conglomerated into a (173, 40) tensor input that training and testing will use. These inputs can be visualized as spectrograms of the time-series feature data of the audio signals (column direction contains time-series data and row direction contains feature data detected at a certain point in the audio file). .
Methodology:
What is the architecture of your model?
Two models, along with an ensemble calculation accuracy-prediction integration method (will take in outputs of various trained models and perform calculations to decide on a final prediction) will be built. One model will be a triple-layer LSTM, and the second will be a CNN + LSTM combined network.
Triple-layer LSTM structure: This model adjusts weights by categorical cross entropy loss and will use a learning rate of 1e-4.
Layer 1: 256 nodes with 0.2 dropout
Layer 2: 128 nodes with 0.2 dropout
Layer 3: 64 nodes with 0.2 dropout + Dense layer to output size 10.
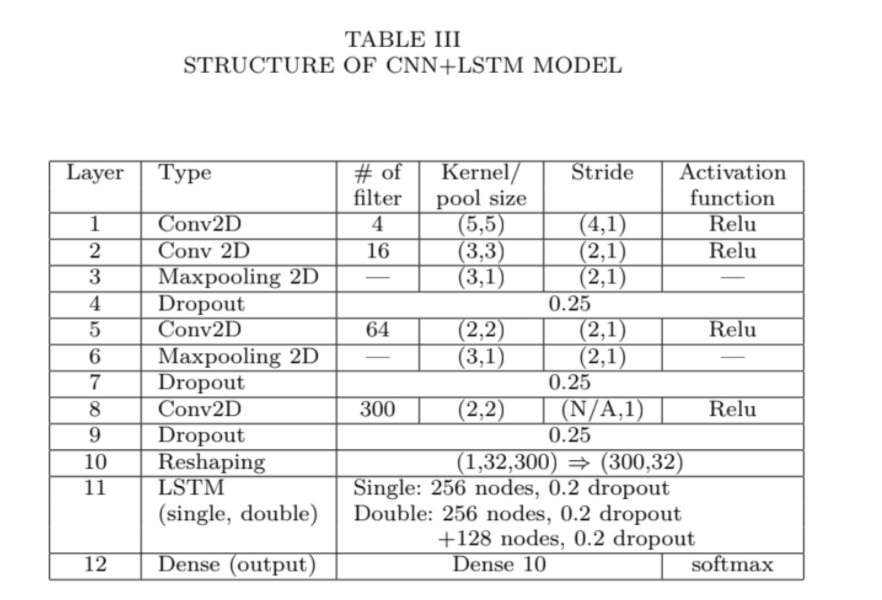
CNN + LSTM combined network: This model adjusts weights by categorical cross entropy loss and will use a learning rate of 2e-4.
Conv2D layer 1: 4 filters of kernel size (5, 5), stride (4, 1), Relu activation
Conv2D layer 2: 16 filters of kernel size (3, 3, ), stride (2, 1), Relu activation
Maxpooling 2D: kernel size (3, 1), stride (2, 1)
Dropout 0.25
Conv2D layer 3: 64 filters of kernel size (2, 2), stride (2, 1), Relu activation
Maxpooling 2D: kernel size (3, 1), stride (2, 1)
Dropout 0.25
Conv2D layer 4: 300 filters of kernel size (2, 2), stride (N/A, 1), Relu activation
Dropout 0.25
Reshape output from size (1, 32,300) => (300, 32)
LSTM: 256 nodes, 0.2 dropout
Dense Layer: output size of 10, softmax
According to the paper, both models “reached maximum accuracy between the 1500th and 2000th epoch”. While we may not have the computational capacity to train for this long, we will adjust the epoch training time until we reach at least our base goal accuracy of 60-70% (the paper achieved accuracy above 90% for all models).
We will also employ the prediction-accuracy ensemble method to combine the outputs of the above 2 networks to make a prediction on the sound class encountered.
How are you training the model?
The UrbanSound8K dataset contains a total of 8732 WAV sound files that are 4 second or shorter recordings of ten types of sounds. Out of these 8732, 15% will be randomly selected and used as testing data and the remainder will be used as training data.
Training will most likely be performed on Google Cloud Platform due to the sheer volume of data involved and the high number of epochs for which training will need to occur over.
If you are implementing an existing paper, detail what you think will be the hardest part about implementing the model here. We believe the hardest part of implementing the model will be the preprocessing of the data into the appropriate input form, with the extraction of the 5 features (Mel-frequency cepstral coefficients, chromagram, Mel-scaled power spectrogram, spectral contrast, and tonal centroid features) from the audio files requiring usage of a Python package that we have not used before, Librosa.
Metrics: What constitutes “success?” What experiments do you plan to run?
The paper we are consulting experiments a lot with different models and different combinations of models within various ensembles. Thus, there are many combinations of models to be used within ensembles, and many different accuracies that can be compared to determine what kind of model is best suited for our task. Our team plans to experiment with a few different models (triple LSTM and CNN + LSTM in particular) and choose 2 or 3 to create an ensemble model that is intended to perform better because it has the input of multiple models instead of one. One of our goals is to also analyze the differences in the accuracies and effectiveness of the two models and the ensemble method. We are interested in analyzing the results of the different models and the ensemble method to see if there are any significant differences between using a single model versus an ensemble on sound data (which inherently has complexities that make it different from the image and text data we have seen previously, in which time was never a factor in the input), and how different models perform on sound data.
For most of our assignments, we have looked at the accuracy of the model. Does the notion of “accuracy” apply for your project, or is some other metric more appropriate?
Yes, accuracy is relevant here. Since the task is a 10-class classification problem, we can simply use accuracy on a given batch or test set to measure our model’s performance (as the paper did to determine the success of the models created).
If you are implementing an existing project, detail what the authors of that paper were hoping to find and how they quantified the results of their model.
The authors of the paper intended to create an accurate model for sound classification, but experimented with what type of model would be best suited for the task. In their experimentation, they generated several different models (LSTM single, LSTM double, LSTM triple, CNN + LSTM(single), CNN + LSTM(double)) and also generated 3 different ensemble methods (general voting method, accuracy voting method, accuracy prediction integration method) using various combinations of the previously named models to obtain a better prediction. Results from the implementations of this range of different models were then compared to see how each model fared in the sound classification task. Model effectiveness/success was judged using an accuracy metric (was the model able to correctly predict the class of the sound input).
The authors were hoping to find an ideal combination of networks that would best be able to classify sound data, which contains the added complexity of time-sequence and preprocessing feature extraction in comparison to image and text data. From their results, they found that LSTM networks performed better than CNN + LSTM models (CNN models were incorporated in the hope that they would perform well as the sound inputs were generated using extraction of 5 features in preprocessing). In addition, the ensemble method 3 (accuracy prediction integration method) performed with highest accuracy; however generalizing that this ensemble method was the best could not be done as its performance varied depending on the combination of models used. However, the high accuracies that the team obtained indicated that using deep learning to train a network to classify environmental sounds was possible, and could be done effectively.
Base, Target, and Stretch Goals:
Base Goal: Our base goal is 60-70% accuracy on testing.
Target Goal: Our target goal is 70-80% accuracy on testing.
Stretch Goal: Our stretch goal would be to attain the accuracy of the paper itself, which is ~96% testing accuracy.
Ethics: What broader societal issues are relevant to your chosen problem space?
Why is Deep Learning a good approach to this problem?
Deep learning is a good approach to this problem due to the nature of our data, which has high complexity with a lot of data points (frequency and amplitudes over time), making it a good candidate for neural networks. Furthermore, since we are converting each sound into an input size of (173, 40), our model is extracting several features to learn from, a task that CNN’s are well equipped to deal with. Moreover, since sound is sequential in nature (frequency at one time point may be related to the frequencies around it), the data is also properly suited for an LSTM model, which performs well on sequential data.
What is your dataset? Are there any concerns about how it was collected, or labeled? Is it representative? What kind of underlying historical or societal biases might it contain?
Paper on how the sound was collected: http://www.justinsalamon.com/uploads/4/3/9/4/4394963/salamon_urbansound_acmmm14.pdf
The dataset we will use for this project is UrbanSound8K, one of the largest among non-speech sound datasets. .
If Urbansound8k were collected without individuals’ consent, for example the specific sound of children playing, this could be a source of concern. As sound data is inherently difficult to collect, some sounds in the UrbanSound8K dataset are underrepresented. As the 2018 Suh, Seo, Kim paper noted, certain sounds such as gunshots were significantly underrepresented in the data set, and this could introduce potential sources of bias that could skew the accuracy of the model toward predicting other sounds as they simply are more common.
Bias could exist depending on in what environment the model will eventually be used to classify sounds. If used in a non-urban setting, the model would be biased towards common urban sounds (e.g. gun violence, construction). Perhaps there are other hazardous sounds that are more applicable to different areas, for example suburban or rural hazardous sounds, which this model may not perform as well on. As such, this dataset will mostly be applicable in the urban setting.
Who are the major “stakeholders” in this problem, and what are the consequences of mistakes made by your algorithm?
Major stakeholders in this problem are people who are deaf/hard-of-hearing, seniors or their caretakers, or those who make products that use sound detection. Another example of possible usage is through at-home security devices, which could alert you if there is a hazardous sound heard, or messaging services like Discord which use sound filtering. As shown in the 2018 Suh, Seo, Kim paper "Deep Learning-Based Hazardous Sound Classification for the Hard of Hearing and Deaf," the paper had a real-life hardware application by using Raspberry Pi and a USB microphone and driver that could give individuals a binary classification of hazardous vs. non-hazardous sound.
Division of labor:
Preprocessing: Yasmin, Mary
Architecture/model building: Everyone
Testing/Hyperparameter Tuning/Comments: Mel, Leila










Log in or sign up for Devpost to join the conversation.