-
-
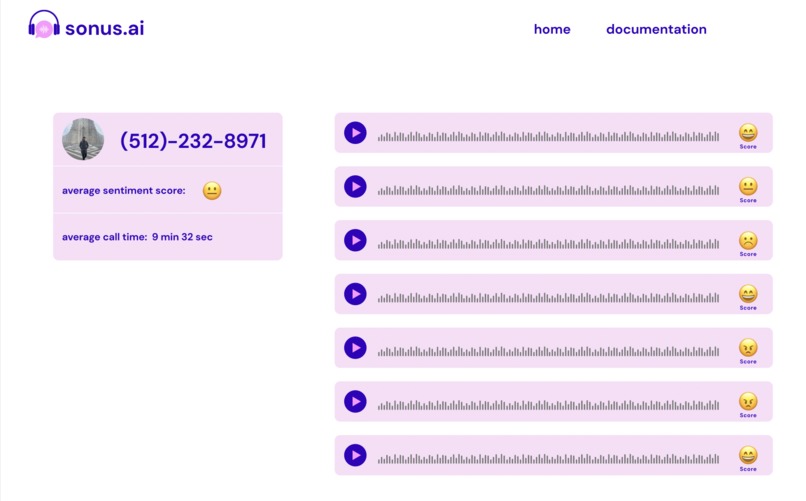
sonus Web App
-
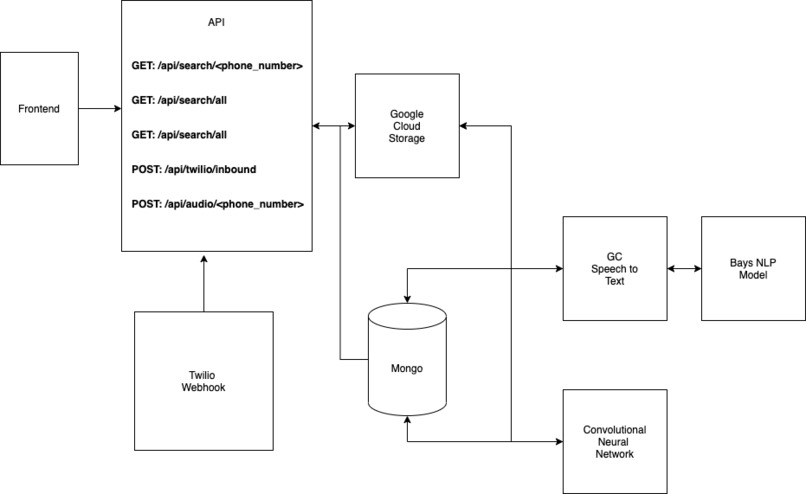
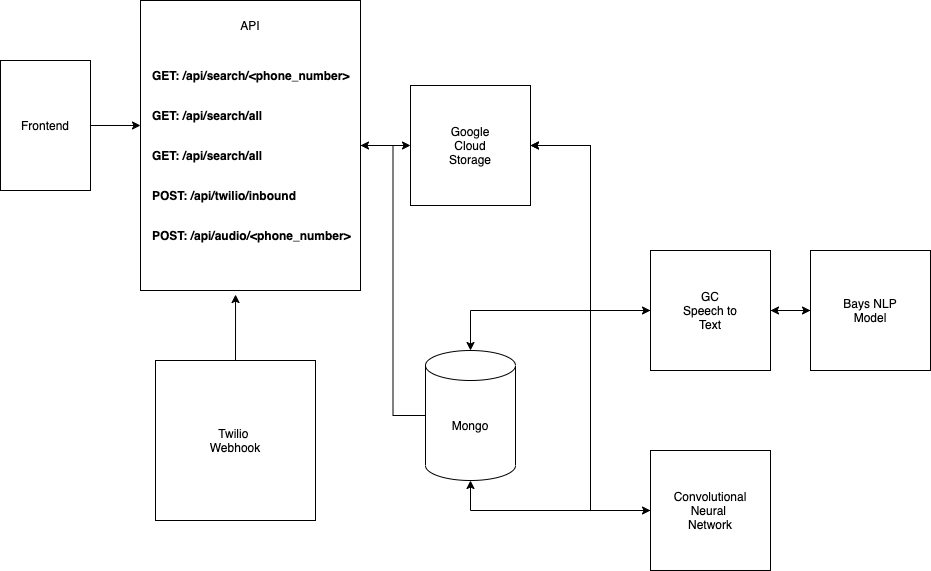
sonus Architecture
-
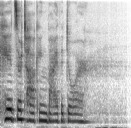
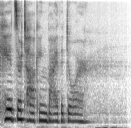
Spectrogram
sonus.ai
Inspiration
We were inspired to create Sonus.ai after realizing that an organization shouldn't have their highest level of support occupied with already content customers. Rather, their best agents should attend to customers who feel angry, dejected, or discontent. By being able to determine a customer’s emotion, the organization's customer service becomes more efficient and fulfills the service’s primary goal with minimum effort from both sides. Furthermore, Sonus has a wide-range of applicability owing to the fact that it can be used by hotlines that seek to provide crisis counseling and mental health referrals. With Sonus, hotline call centers can resolve difficulties faster by using a patient’s emotions as a navigating tool.
What it does
Sonus is a customer success management tool that is designed to be used in conjuction with IVR (voice chatbot) systems. It analyzes human emotion in real time and can route angry & agitated customers to human representatives while allowing fulfilled & happy customers to continue to interface with the IVR system.
How we built it
Architecture
 Sonus is built using a React frontend and a Python backend. We use MongoDB to store data and Google Cloud Storage to store audio & transcript data. We also trained several machine learning models using white papers and data we found online.
Sonus is built using a React frontend and a Python backend. We use MongoDB to store data and Google Cloud Storage to store audio & transcript data. We also trained several machine learning models using white papers and data we found online.
Workflow
Twilio Webhook
- A client will call our phone number and Twilio will post a webhook to our server. After the call ends, we are able to stream the outputs of the call into Google Cloud Storage where it will then be sent to our various models for classification.
Speech to Text Transcription
- We use Google's Speech to Text API to convert the audio stream into text. We then save this information into MongoDB for further analysis
Text Based Sentiment Analysis
- We implemented a naive bayes classification algorithm that was trained on text data from customer reviews. The model achieved an 86% accuracy rate in classifying whether or not the customer dialogue was positive or negative.
Audio Convolutional Neural Network
- We created our CNN based off a whitepaper we read online
- We converted our training audio into spectrograms, which are image based representations of audio files based on frequency and time
Challenges we ran into
We had trouble running our model since most people in our group had M1 Macbooks with inadequate tensorflow support. We also had trouble with docker dependencies and modules not installing properly.
Accomplishments that we're proud of
This was everyone in our group’s first time dealing with Machine Learning, and we were extremely happy that we were able to come together and tackle this challenge head on!
What we learned
We learned about how to train a model on a large scale dataset and how to accurately render components using React!
What's next for sonus.ai
We hope to focus more on further improving the accuracy of our model and putting it through other datasets we come across!
Built With
- google-cloud
- python
- react
- tensorflow
- twilio






Log in or sign up for Devpost to join the conversation.