-
-

landing page
-

-
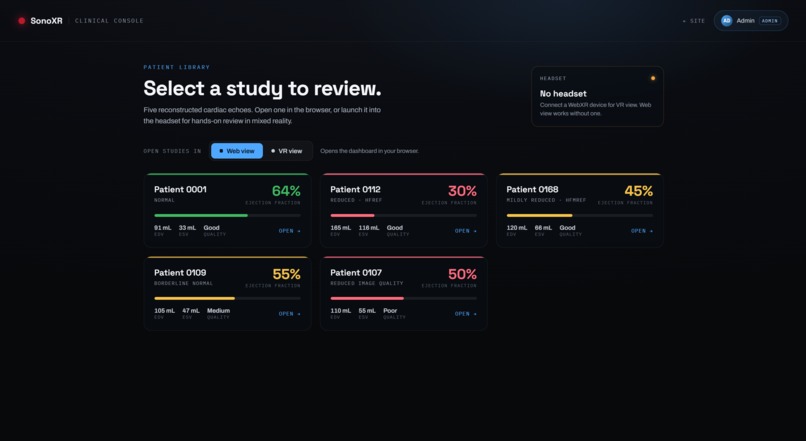
dashboard
-
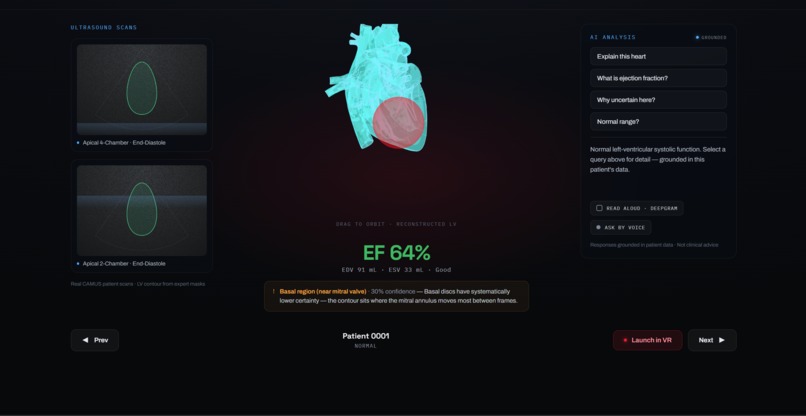
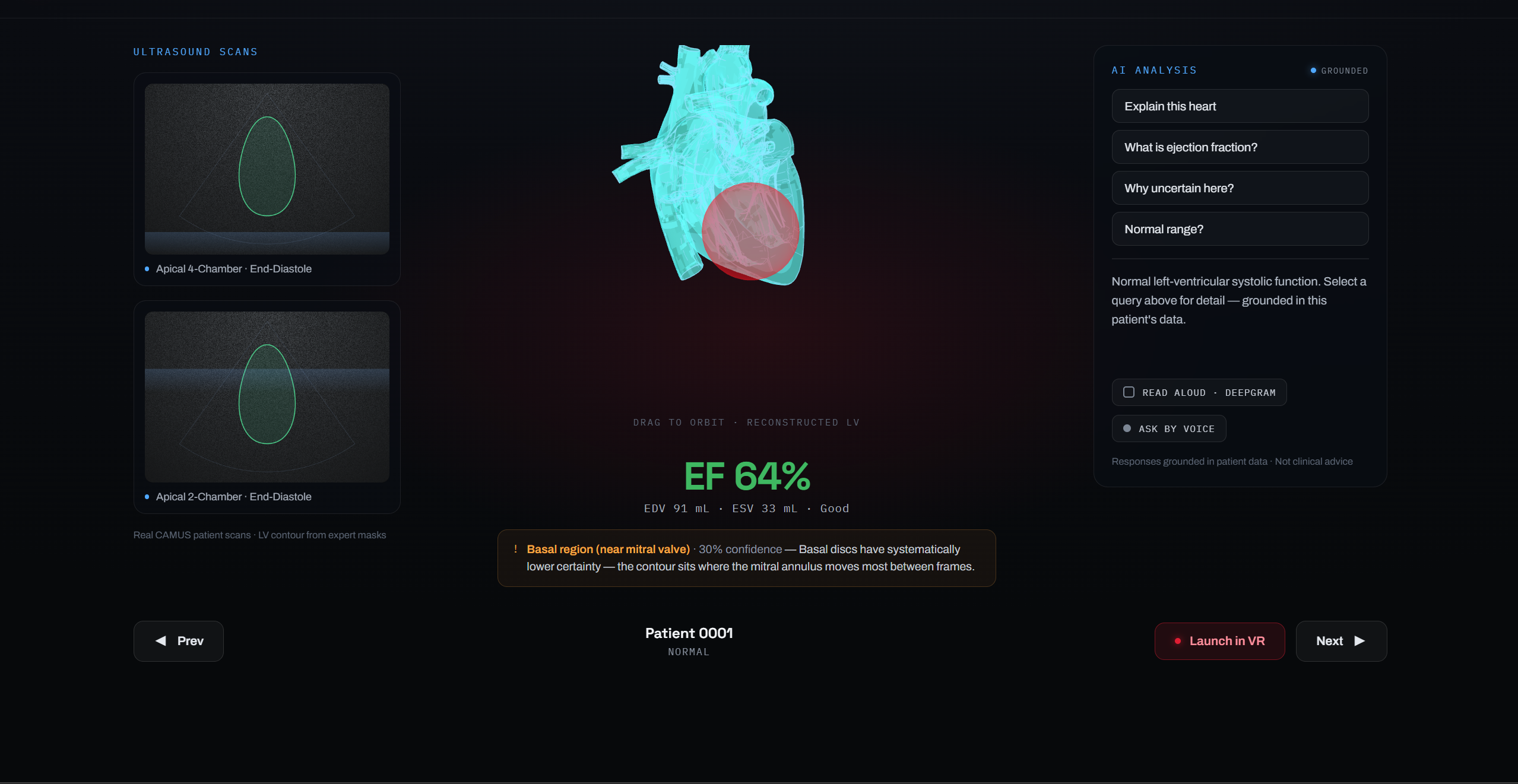
Patient profile
-
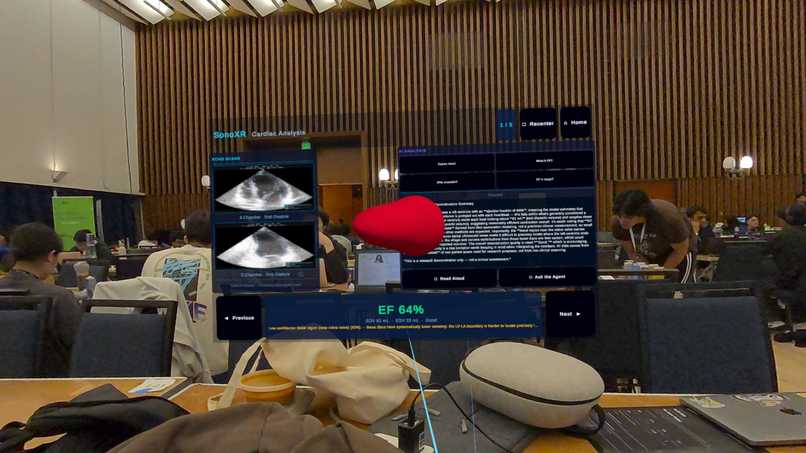
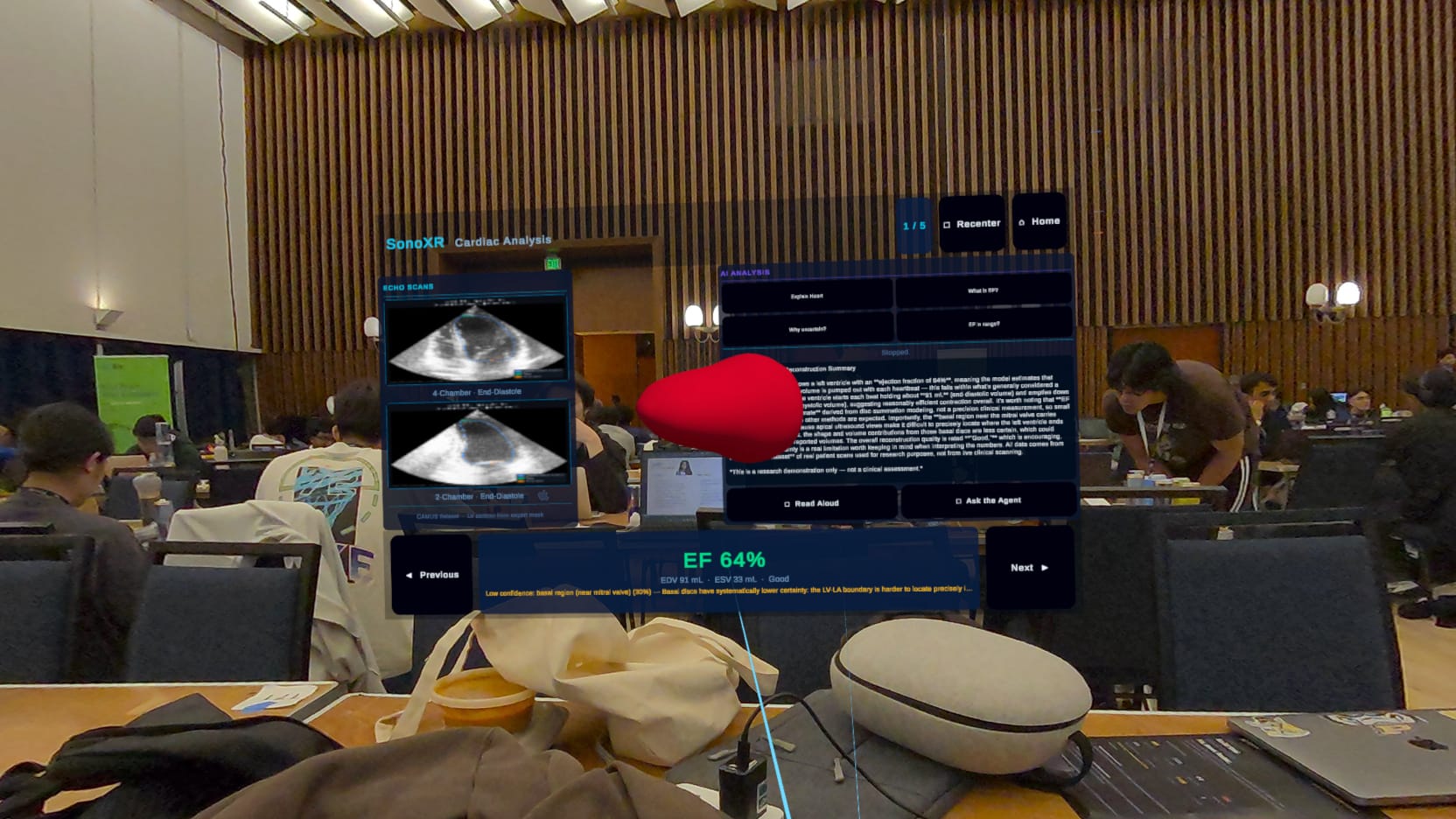
AR view


Inspiration
Echocardiography is the front line of cardiac diagnosis — cheap, radiation-free, real-time. But its output is a stack of blurry 2D greyscale slices, and extracting clinical meaning from them still depends heavily on the clinician's spatial imagination. We kept asking: what if the reconstruction that a cardiologist runs mentally could be made literal — a physical object you reach out and examine?
At the same time, we were looking at Fetch.ai's agent architecture and noticing a mismatch in most medical-AI demos: the "AI" is a monolith sitting in a cloud VM, not something the broader ecosystem can query or compose. That combination — spatial computing meets agentic medical compute — became the thesis for SonoXR.
What We Built
SonoXR is a mixed-reality cardiac tool on Meta Quest 3. It ingests real 2D echocardiograms from the CAMUS dataset, reconstructs the left ventricle as an animated 3D mesh, and renders it floating in your physical space with clinical measurements overlaid in AR.
The reconstruction uses Simpson's biplane method — the same algorithm used in clinical practice. The left-ventricular volume at any frame is approximated by summing $N$ elliptical disc slices along the long axis:
$$V = \frac{\pi}{4} \cdot \frac{L}{N} \sum_{i=1}^{N} a_i \cdot b_i$$
where $L$ is the long-axis length, and $a_i$, $b_i$ are the orthogonal diameters of the $i$-th disc measured from the 4-chamber and 2-chamber apical views respectively. Ejection fraction follows directly:
$$\text{EF} = \frac{\text{EDV} - \text{ESV}}{\text{EDV}} \times 100\%$$
The architecture is split across two Fetch.ai agents:
- Data-provider agent — runs alongside the CAMUS dataset. Handles all medical-image I/O: SimpleITK reads the volumetric
.mhdscans, runs the Simpson reconstruction, and bakes a.glbheart mesh. The Quest 3 never touches raw DICOM or volumetric data; it receives a render-ready asset. - Chat agent (Agentverse) — implements ASI:One's Chat Protocol and publishes its manifest. It is live right now with ASI Available status. Any agent or user on the network can ask in plain English — "What is patient 0001's ejection fraction?" — and receive back EDV, ESV, EF, image quality grade, and citation, all derived from real reconstructed patient data.
The Quest 3 app itself is built in Unity 6 with GLTFast 6.x for runtime GLB loading, a world-space Canvas UI with rounded-panel design, Claude AI for in-headset cardiac explanation, and Deepgram for voice interaction.
How We Built It
Medical reconstruction pipeline (Python) SimpleITK loads the 4-chamber and 2-chamber apical sequences. We segment the LV contours per frame, sample $N = 20$ disc slices along the detected long axis, and apply the biplane volume formula. End-diastolic and end-systolic frames are identified by peak and minimum volume. The mesh is generated with marching-cubes on a voxel mask and exported as GLB with per-vertex colour encoding reconstruction confidence.
Fetch.ai agent layer
The data-provider agent exposes an HTTP endpoint that the Quest app calls on patient selection. The chat agent wraps the same reconstruction data behind uagents_core's ChatMessage / ChatResponse protocol, registers on Agentverse, and publishes a manifest so ASI:One's LLM can route natural-language cardiac queries to it automatically.
Quest 3 mixed-reality app (Unity 6) Passthrough MR via OVR SDK. The heart mesh loads at runtime via GLTFast, anchored 15 cm in front of a world-space Canvas so it always renders in front of the UI panels. Right thumbstick rotates the model; right index trigger grabs and moves it freely in 3D space — position-delta tracking so every axis of hand movement transfers directly to the heart. The left panel shows real ultrasound frames; the right panel is a Claude AI assistant that explains the reconstruction in plain language. Left thumbstick scrolls the AI response text.
Challenges
Coordinate systems at every boundary. SimpleITK uses RAS (right-anterior-superior) orientation; GLB uses Y-up right-handed; Unity uses Y-up left-handed. A mesh that looks correct in Python looks inside-out in Unity unless you flip triangle winding and negate one axis. We spent an embarrassing amount of time staring at a heart that rendered as a hollow shell from the outside.
Layout in world-space VR. Unity's HorizontalLayoutGroup respects LayoutElement.preferredWidth as a hint, not a hard cap — child content can push panels wider than intended, causing the 3D heart to overlap the UI panels. We had to replace the flexible-box layout with absolute RectTransform anchors (anchorMin/anchorMax/offsetMin/offsetMax) to guarantee the panels were exactly 200 px from each canvas edge regardless of content size.
ScrollRect in VR. Pointer-drag scrolling is unreliable with OVR's ray-casting input model (the pointer fires click events, not continuous drag events). We replaced it with joystick-driven scrolling: left thumbstick Y nudges verticalNormalizedPosition each frame, with a ContentSizeFitter auto-expanding the content height to fit the full Claude response.
Keeping API keys off the device. The Anthropic key must never be compiled into the APK (extractable via apktool). We load it at runtime from StreamingAssets/sonoxr_config.json, which is excluded from version control and sideloaded separately before each build.
ASI:One discoverability. Getting the chat agent to appear as ASI Available required the manifest to be well-formed and the agent address to be reachable at query time. Early runs returned agent not found from ASI:One's router because the manifest was missing the capabilities field.
What We Learned
The most transferable insight: the right unit of agent autonomy is the expensive, reusable computation — not the full application. Offloading medical-image I/O to an agent that owns the dataset makes the reconstruction independently queryable, citable, and composable. The Quest app is a consumer of that agent, and so is ASI:One. The same data serves two completely different interfaces without duplicating any medical logic.
On the spatial computing side: world-space UI in mixed reality demands a different mental model than screen-space UI. Depth matters — an object 15 cm in front of a canvas plane will always occlude it regardless of draw order. Layout groups that work perfectly on a 2D screen can produce wildly wrong results in VR because the layout system doesn't know about physical viewing angles or stereo parallax.
And practically: Simpson's biplane is simple enough to implement from the paper in an afternoon, but getting the numerical result to match clinical software took careful attention to the long-axis detection step — the formula is sensitive to where you place $L$.


Log in or sign up for Devpost to join the conversation.