




Assembly-AI-hackathon-repo
Repo for hosting both server and client apps built by me for the Assemby AI hackathon
First of all, I was enjoying in this hackathon, barely slept, but managed to beat my limits and goals and managed to build a really cool app.
SongQ
SongQ is the app for cloning your voice into voices of your favorite actors.
Motivation
The Company I founded last year is called DeepQ, as I'm just a regular audio&NLP ML dev, not an enterpreneur, I never planned to build anything special around the brand. But, on the persuasion of my friends, I created a website which looks kinda cool and presents my Audio engineering skills and deepfake funny creations. https://deepq.io (website is still in the making), also, just for fun, I uploaded one of the fakes on TikTok featuring Croatian president singing a popular song which went viral in Balkan states. Many people asked me to send them "the app" which I was using. My inspiration for this hackathon project idea and names are derived from the idea that the app would be cool to exist and the name of my freelance company DeepQ. SongQ now exists, thanks to this hackathon since otherwise I would be too lazy and wouldn't have enough motive to code React Native which was long time abandoned by me in student days.
Rest is the useful content of this repo, I hope you will like it!
DEMO
on IOS, donwload Expo GO application from the AppStore, after that, return here and click on this url
exp://u.expo.dev/update/37309f29-8653-43ad-a435-2e1140e6444f
or, scan this QR Code:

API is accessible during hackathon duration on
https://backend-assembly-hackathon.deepq.io/docs
please keep in mind its hosted from my PC, RTX 3080ti so in case of possible failure please contact me
Table of Contents
- usage
Click on a voice you want and hold the button while speaking, on release, your voice will be cloned

- usage
- Apps description
- CLIENT
- SERVER
Model
- Model description
- Data
- Training
Thanks to
Video
Usage
Apps description

Client
App is being built with react native and expo toolkit, it utilises share functionality, audio recording, filesystem API, and is deployable on both iOS and Android
Server
DOCS: https://backend-assembly-hackathon.deepq.io/docs
Server app is simple FastAPI API which has 2 endpoints:
/inference/{voice_name}- POST request where you upload audio file (form data)
- response is JSON in which you receive URL file to your Audio data which is staticaly hosted
/transcript/{file-URL}- GET request where file-URL is the URL file statically hosted
- response is JSON with transcripts form Assembly AI API
## MODEL
### DESCRIPTION
Model arhitecture is inspired by Tacotron2 and this AWESOME paper: https://ieeexplore.ieee.org/abstract/document/9746484 by Benjamin van Niekerk.
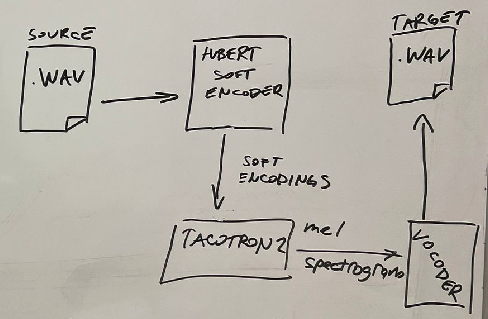
- I use classic 2 part arhitecture for voice synthesis, mel generator which decodes text input to spectrogram in mel scale, and a vocoder, which transforms mel spectrogram (inverse Z) back to a wave file.
- Instead of using text as an input to encoder, I pass soft units from hubert model. Hubert soft units give so much more information than simple text pairs and thats why Im able to train voice cloning with just 20 minutes of audio (morpheous voice), while training for less than a day (per voice).

Data
- I extracted interviews of both Cillian Murphy (Tom Shelby in Peaky Blinders) and Laurence Fishburne (Morpheous in Matrix) gathering total of 20 minutes for Laurence and 40 minutes for Cilian.
- I used resemblyzer library for targeting speaker and cut these long interviews on long silences with SOX CLI utility.
- Afterward, I tried using deezer/spleeter tool to remove background noise but not successful. I used Izotope software to clean audio and extract vocal as best as possible (pretty good results)
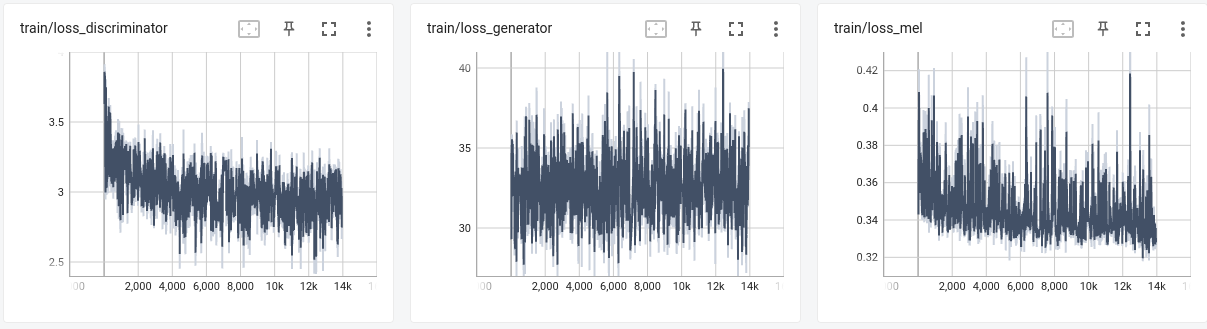
TRAINING
- I trained 4 separate models: 2x mel generators for morpheous and shelby, 2x vocoder (hifigan) for morpheous and shelby
I avoided training unique vocoder for both speakers as datasets are small and didnt want them to generalize since there is not enough data for both speakers and from previous experience that would perform worse than 2 separate vocoders.
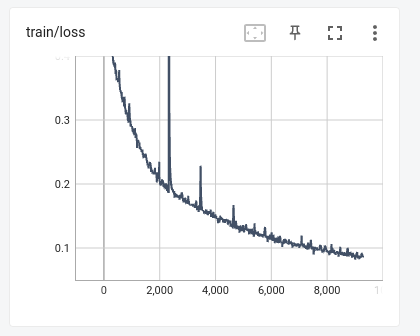
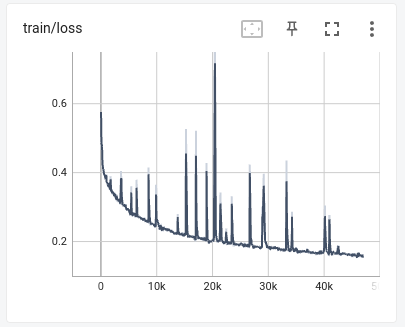
- MEL GENERATORS:
- * SHELBY

- * MORPHEOUS

- HIFIGAN VOCODERS
- * SHELBY

- * MORPHEOUS

- Validation metrics are not that relevant on this kinds of models since datasets are too small, also, hackathon :P
Final words
- Many thanks to Assembly AI for this great opprortunity, it was very fun and enjoyable. I enjoy hackathons and this is my first one after 3 years. 3 years ago, I was regular hackathon attendant and I love it like a sport.
- Many thanks to Patrick Loeber who answered all of my questions regarding the contest, I hope I wasn't too demanding :D
- Many thanks to these 2 guys, without you I would fall asleep in first 12 hours!
- Many thanks to Patrick Loeber who answered all of my questions regarding the contest, I hope I wasn't too demanding :D


- Many thanks to my friends and family for support and bringing me food during the competition.
- Many thanks to my friend Matko who was the person behind the camera while recording pitch video.
- Many thanks to our Football team making great results on World Cup --- no joke, these guys were one of my motivators to give my best on this competition :)
- I am Blaz Jurisic, ML audio&NLP dev from small but beautiful country of Croatia, I work with US clients such as DMS (Digital Media Solutions) in R&D implementing, building and scaling telephony models. In my free time I like nature, sports and making funny deepfake videos.
Built With
- cloudflared
- fastapi
- linux
- python
- react-native
- torch
- uvicorn




Log in or sign up for Devpost to join the conversation.