Inspiration
We're undergrad ML researchers from Cornell who have been training diffusion models capable of generating long-form pop. This weekend we decided take a break from the PyTorch to see how far we could push publicly available audio LMs like MusicGen.
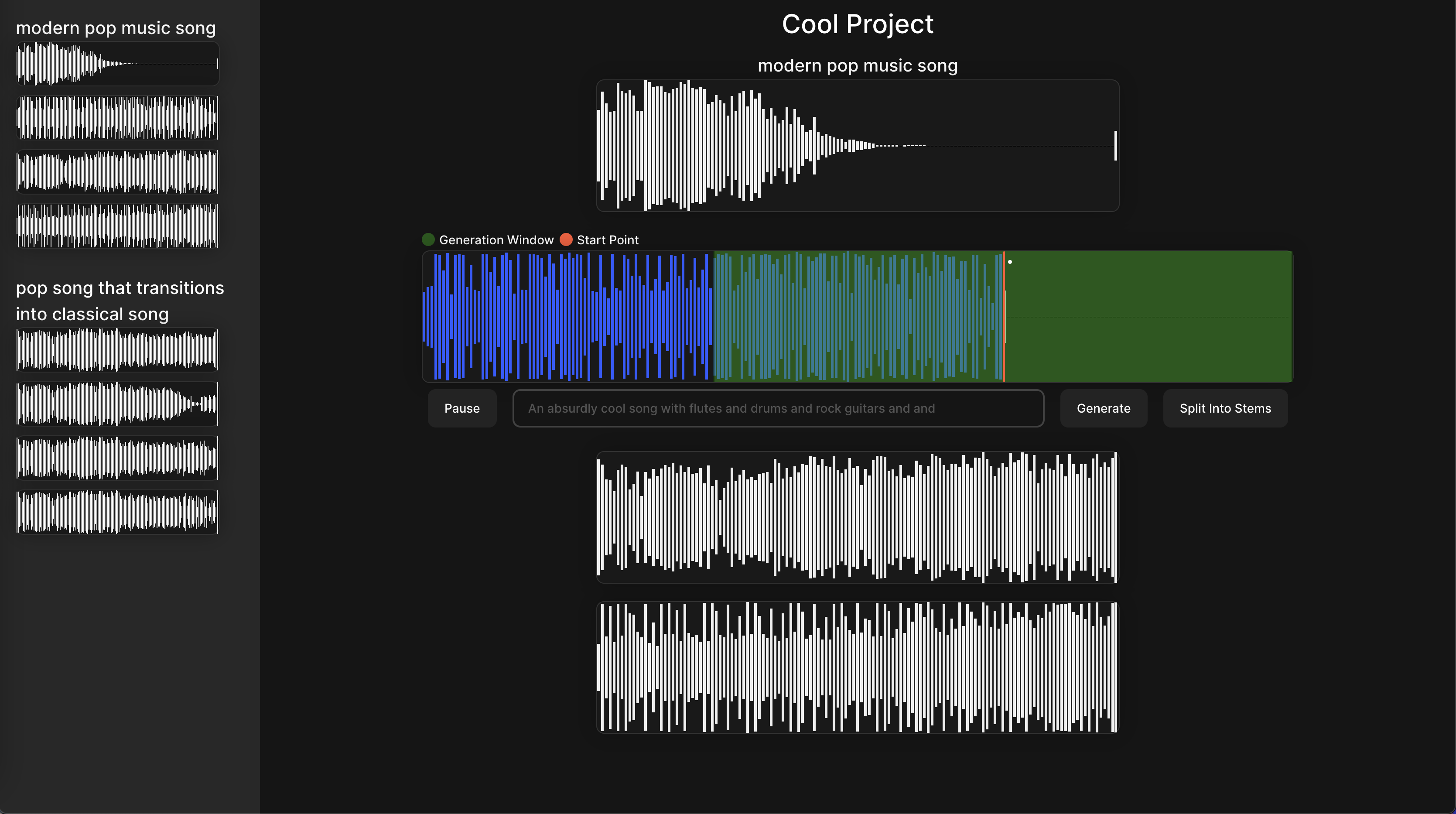
What it does
The Sonauto Editor makes generative music models easy and fun to use so anyone jump into music production making remixes and new songs.
How we built it
With our computers!
Challenges we ran into
MusicGen's inference function is currently heavily CPU bound which means all generations with even small models and batch sizes take a minute and a half regardless of GPU type. https://github.com/facebookresearch/audiocraft/issues/192
Accomplishments that we're proud of
- All actual audio editing takes place directly in the latent space with no quality deterioration. All other known apps that use MusicGen convert back and forth between waveform and Encodec tokens which can ruin a song after a few edits.
- A completely custom backend streams live progress updates and will soon stream MusicGen audio as it’s being generated. Hayden wrote his own queuing system in Python to make this work!
What's next for Sonauto Editor
We think generative models can democratize musicianship, bringing new people with new perspectives into music and causing an explosion of new styles. We plan to continue developing the editor and a sharing platform to help bring about a new musical golden age.




Log in or sign up for Devpost to join the conversation.