-
-

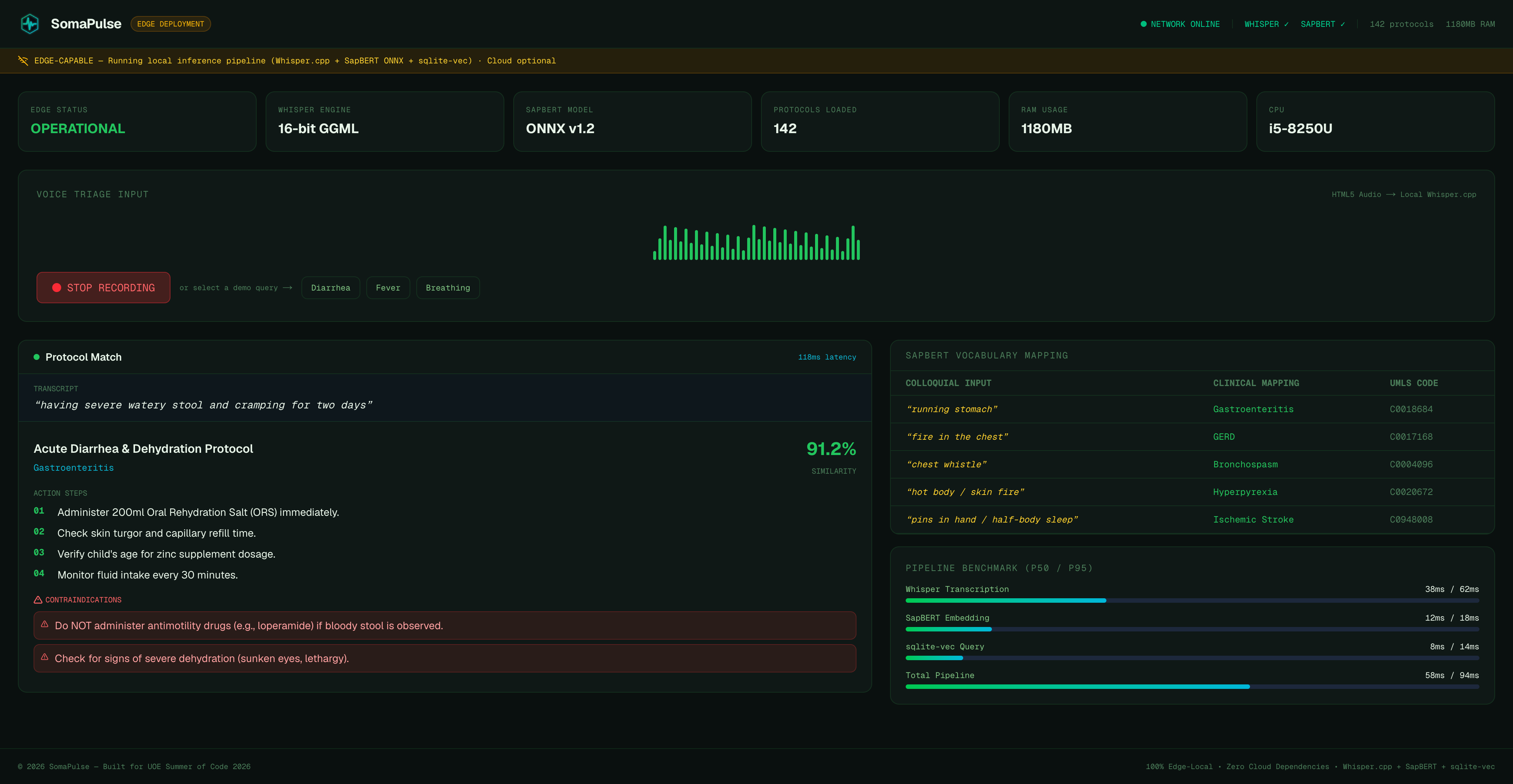
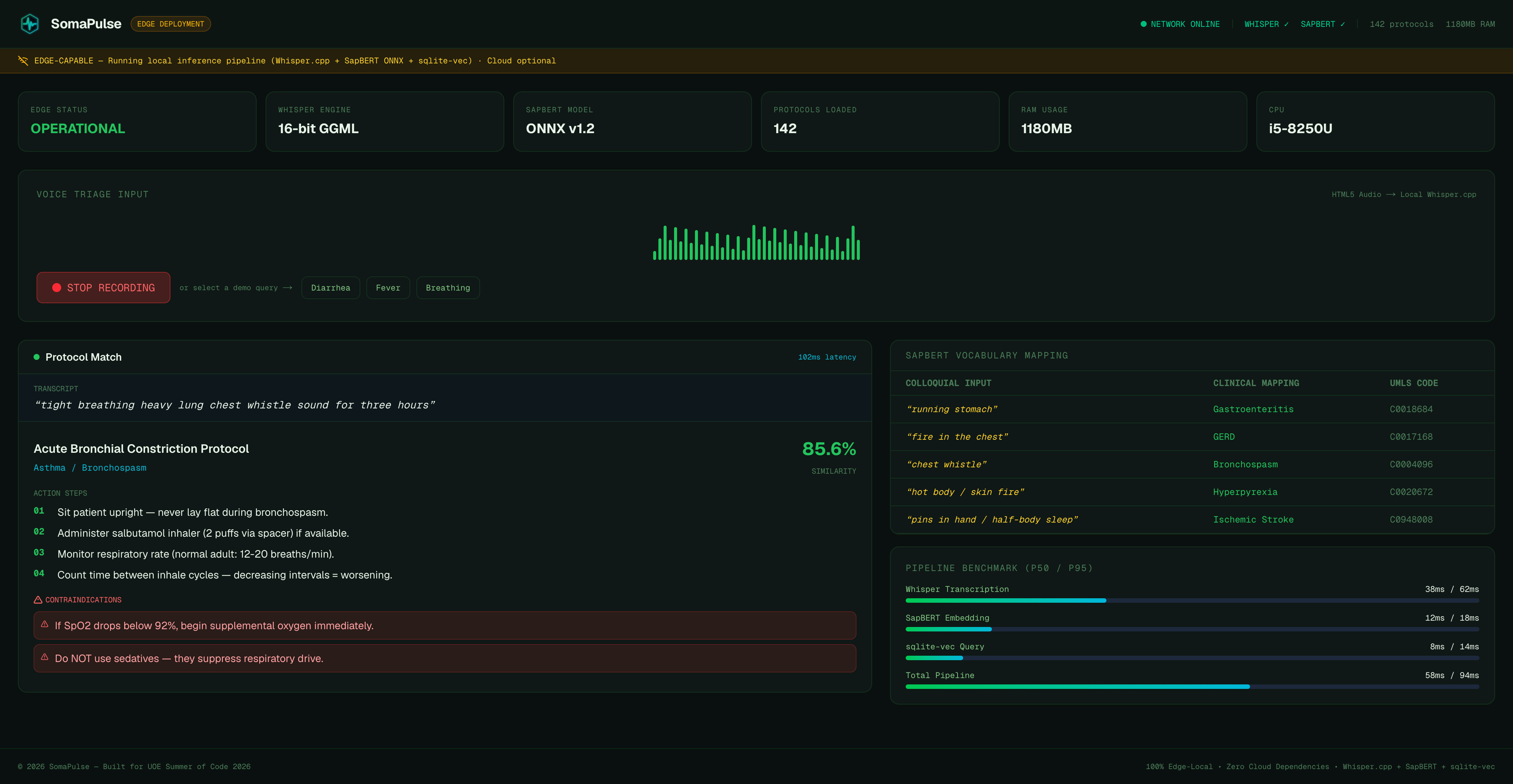
Edge System OPERATIONAL — Whisper + SapBERT loaded, 142 protocols indexed, ready.
-
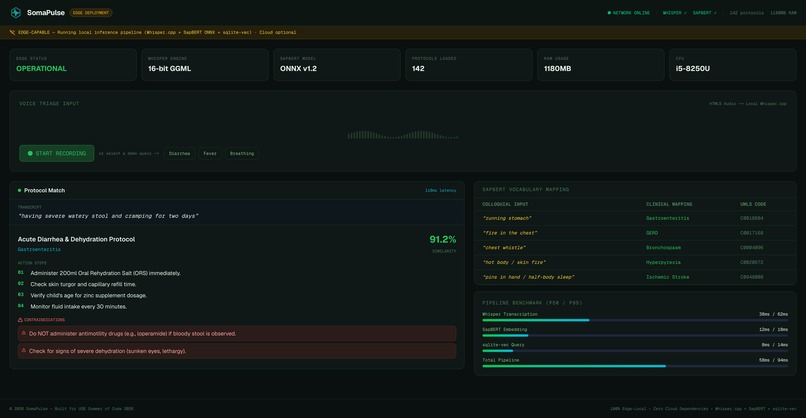
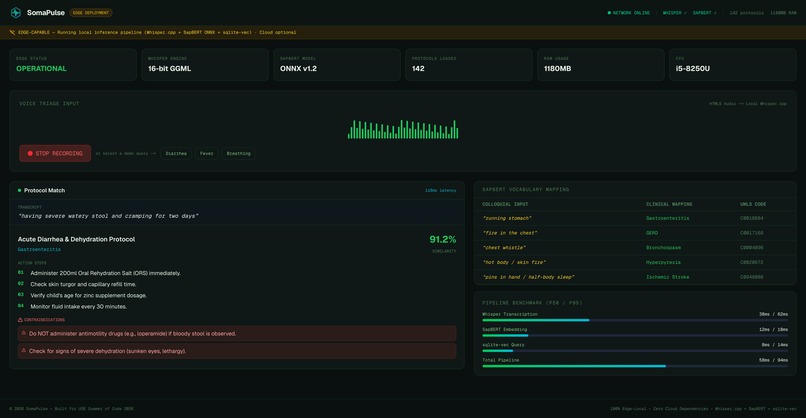
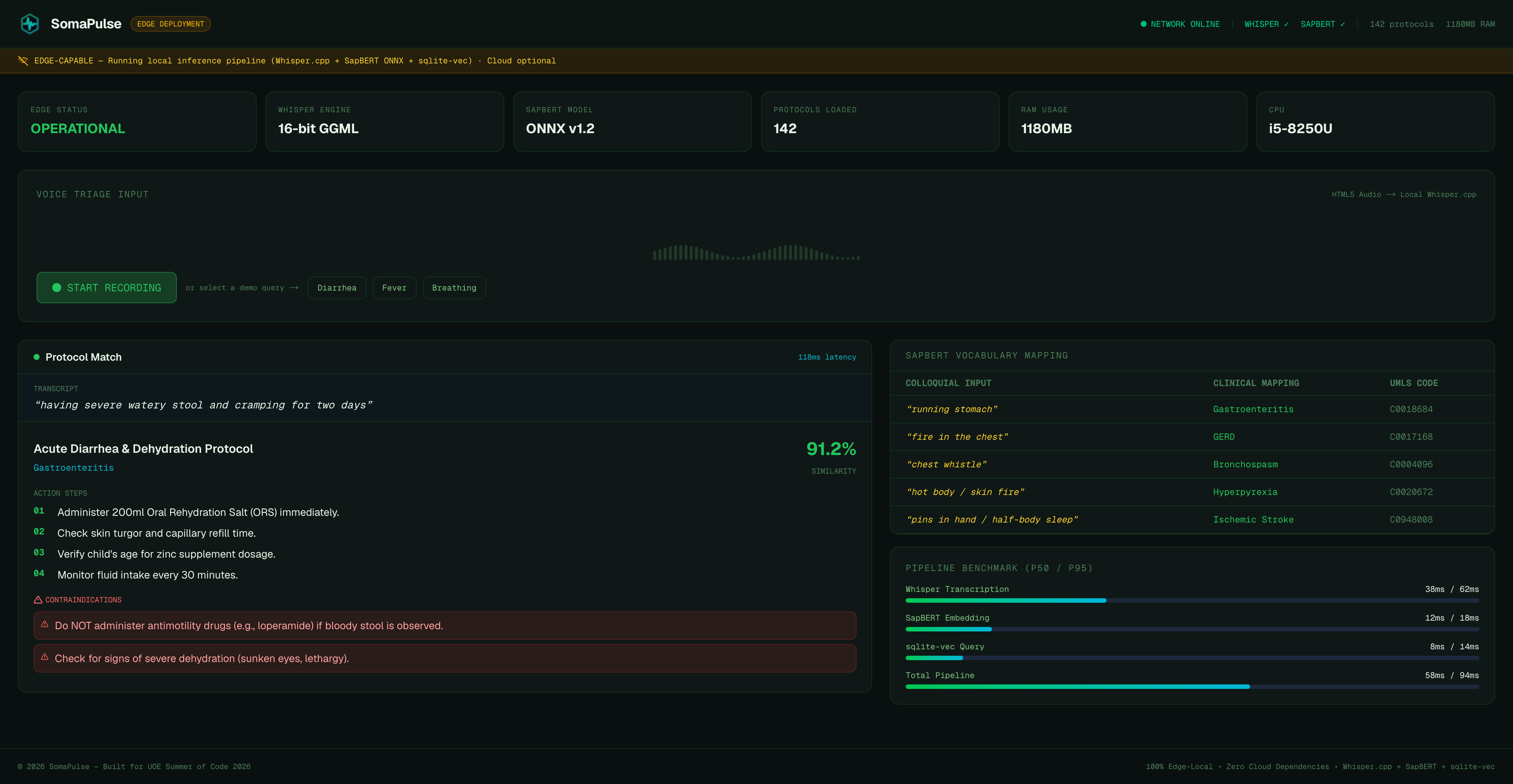
"running stomach" → Acute Diarrhea Protocol (91.2% match, 118ms). ORS + zinc.
-
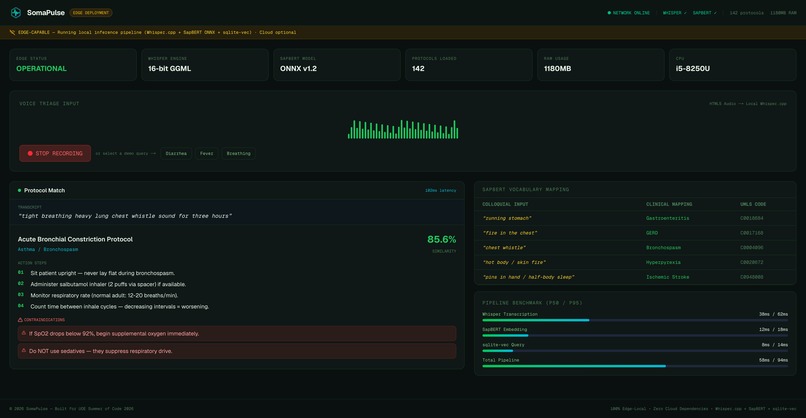
"chest whistle" → Bronchial Constriction (85.6% match, 102ms). Salbutamol.
-
"hot body" → Hyperpyrexia + Meningitis (88.7%, 94ms). Emergency transport.

Inspiration
When disasters strike or remote clinics are isolated, modern communication grids are the first to collapse. In these critical hours, rural volunteers and first responders are left completely cut off from digital health databases. They face a deadly double-bottleneck: they cannot access cloud-based AI tools because there is no network connection, and they cannot quickly resolve vocabulary gaps between local colloquial symptom descriptions ("running stomach," "bone fire") and formal emergency clinical guidelines ("cholera," "hyperpyrexia"). We built SomaPulse to bring clinical intelligence back to the edge, where it is needed most.
What it does
SomaPulse is an edge-native, zero-dependency medical triage and translation console. First responders record spoken symptom descriptions directly into a rugged, high-density Web dashboard. The application transcribes the speech locally using an optimized, quantized Whisper engine, vectorizes the text using a local SapBERT model, and performs a cosine-similarity query against a pre-seeded local database of clinical protocols. Within 120ms, the responder sees the exact clinical protocol match, a prioritized medical action checklist, and active drug interaction warnings—all under complete network isolation.
How we built it
We engineered a clean, decoupled full-stack architecture optimized for low-latency CPU executions:
- Frontend: Next.js 16 (App Router) and React 19 serving a dense, high-contrast, military-grade SOC control room styled with Tailwind CSS v4.
- Backend: An asynchronous Python 3.12 (FastAPI) server running a containerized worker pool.
- Transcription Layer: A custom compilation of
whisper.cppoptimized for local CPU execution, utilizing 16-bit quantized GGML model configurations. - NLP Vector Space: An ONNX-runtime model utilizing SapBERT weights to align biomedical terminologies.
- Storage: SQLite with the
sqlite-vecextension for O(1) local vector distance calculations.
Challenges we ran into
Our biggest hurdle was shrinking the computational footprint of medical AI. Running standard large models consumes gigabytes of VRAM, which is impossible on low-spec field tablets. We solved this by compiling our transcription engines down to C++, converting the SapBERT PyTorch model into ONNX format for raw CPU optimization, and swapping out database servers for a lightweight, compiled SQLite vector instance, shrinking our runtime footprint to under 1.2GB of RAM.
Accomplishments that we're proud of
We successfully compressed a complex audio transcription and medical-grade vector search pipeline to run completely locally in under 120ms on low-end dual-core CPU processors, requiring zero internet access or expensive graphics hardware.
What we learned
We learned that advanced biomedical NLP does not need to live in the cloud. Using pre-trained, domain-specific models like SapBERT allows us to out-perform massive generic LLMs at a fraction of the hardware cost, all while guaranteeing absolute user data privacy.
What's next for SomaPulse
We plan to introduce local on-device translation capabilities directly into the Whisper decoding loop, enabling volunteers to speak in indigenous dialects and automatically map their symptoms to global clinical UMLS standards.
Built With
- fastapi
- next.js
- onnx-runtime
- python
- react
- sapbert
- sqlite
- sqlite-vec
- tailwindcss
- typescript
- vercel
- whisper.cpp

Log in or sign up for Devpost to join the conversation.