-
-
Landing Page
-
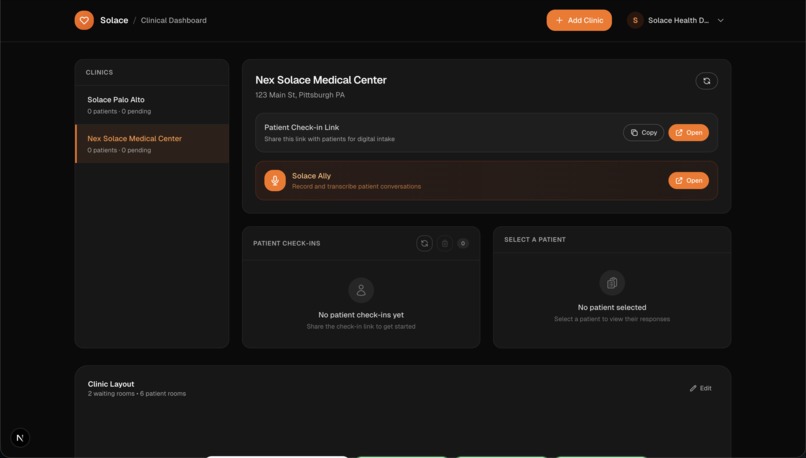
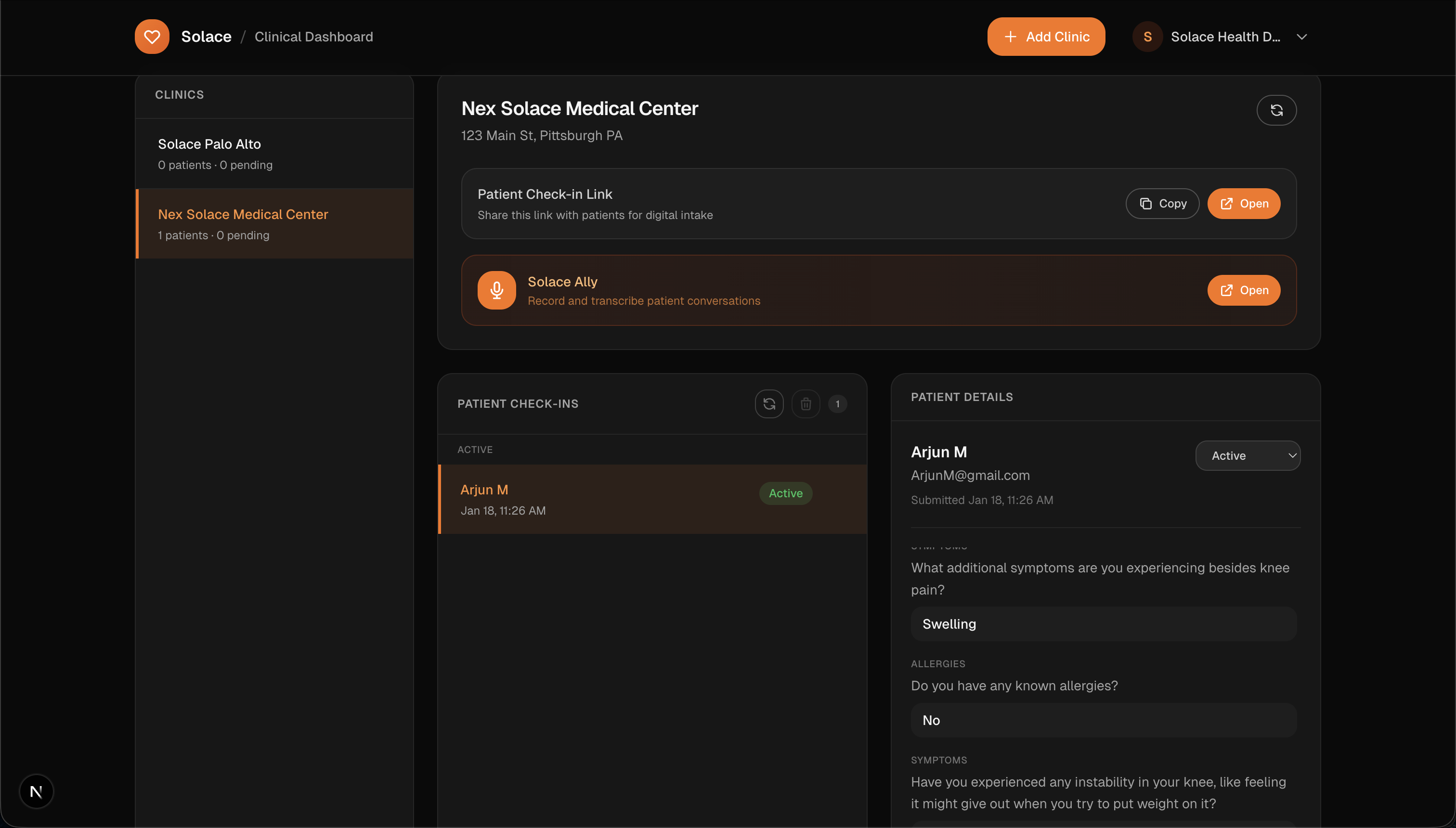
Clinic Dashboard
-
Patient Login
-
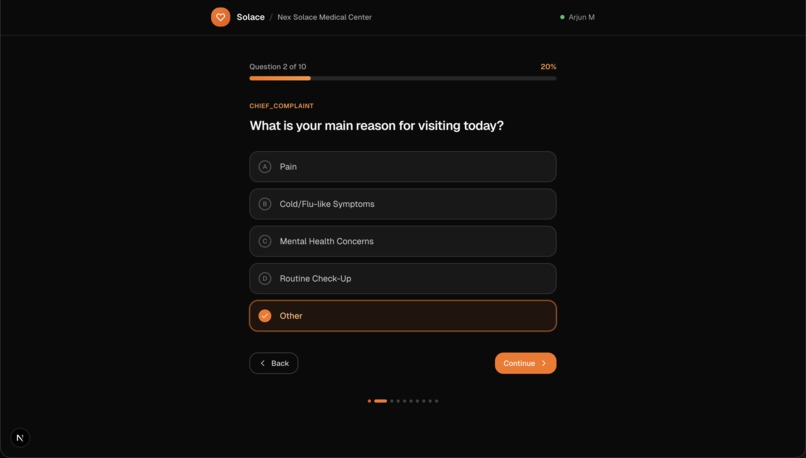
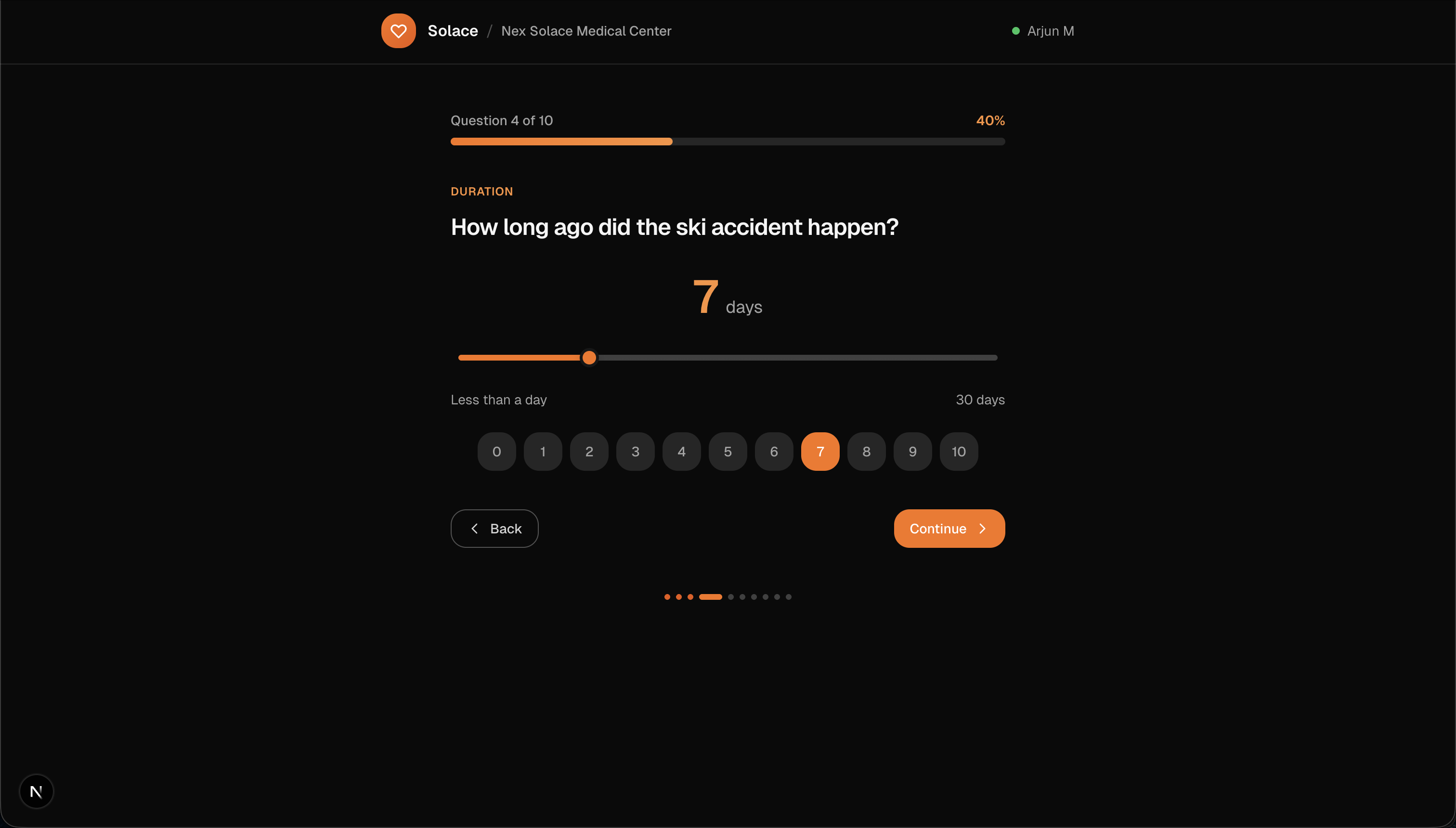
Patient Questionarre (Ex. 1)
-
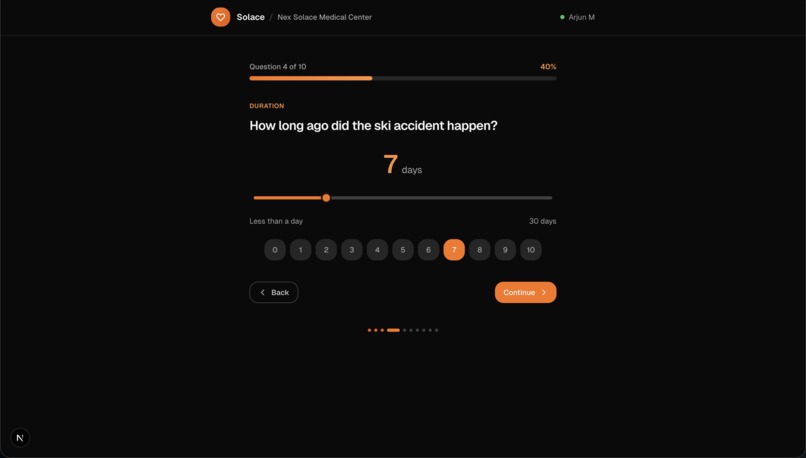
Patient Questionaire (Ex. 2)
-
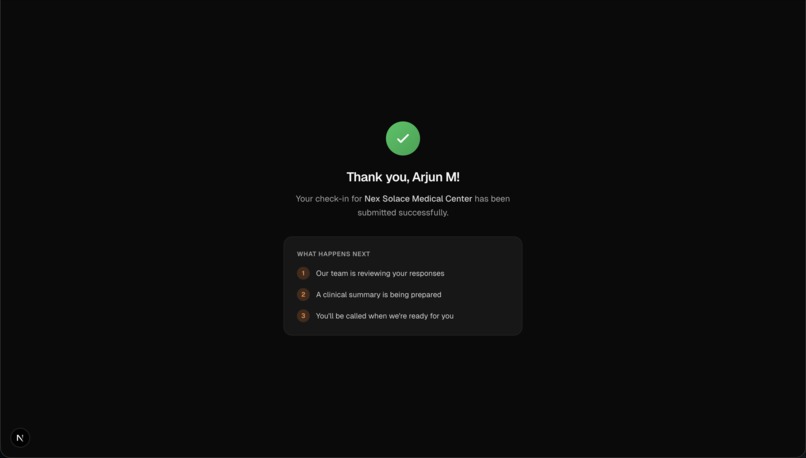
Patient Questionairre (Final Page)
-
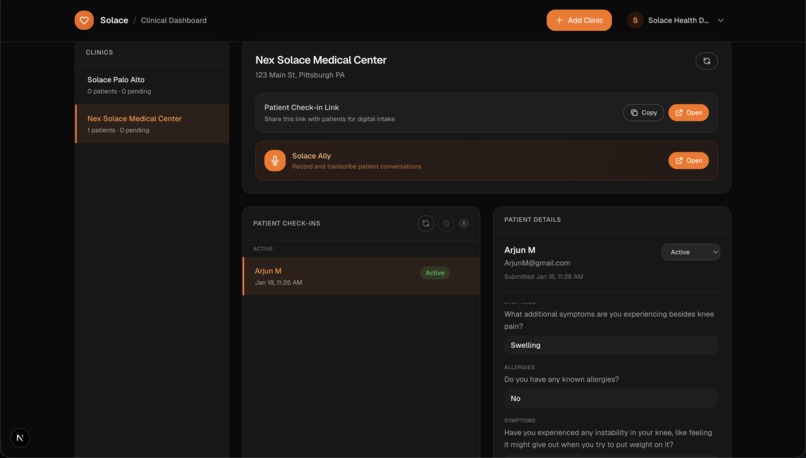
Patient with information initialized in dashboard
-
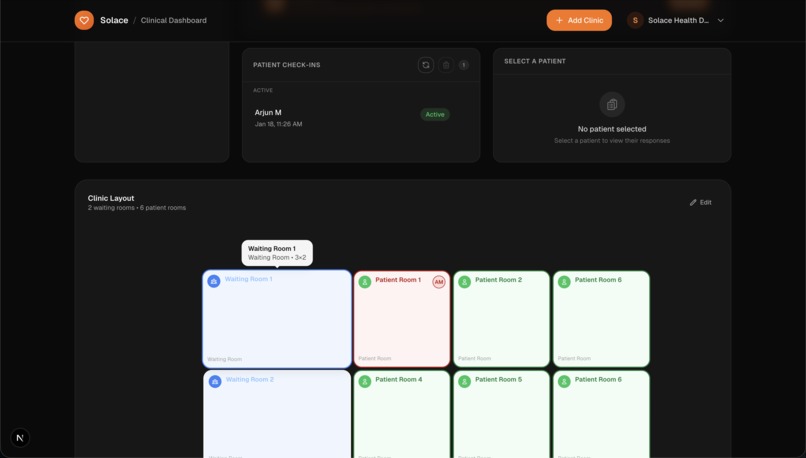
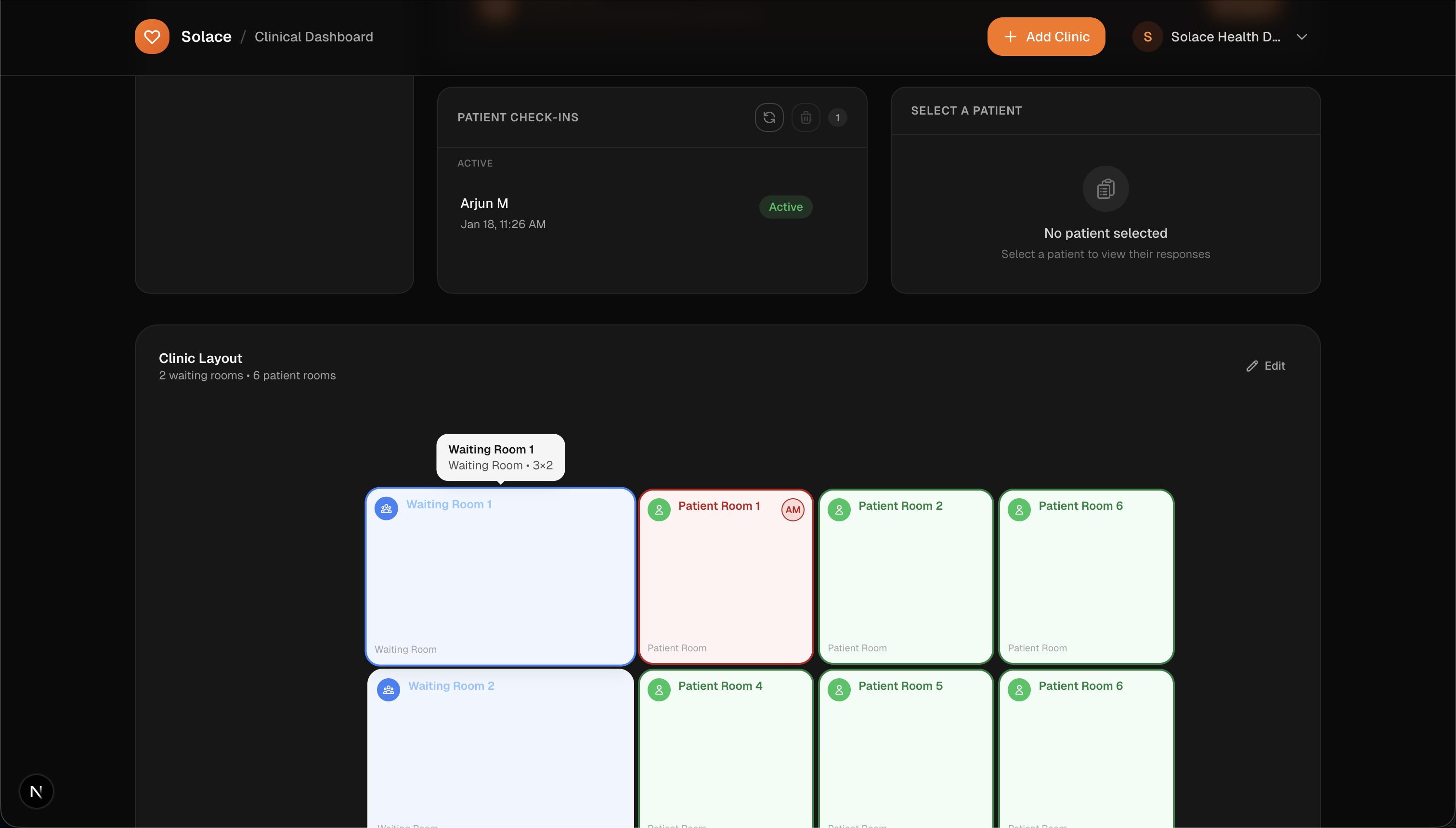
Patient sorted into room via map
-
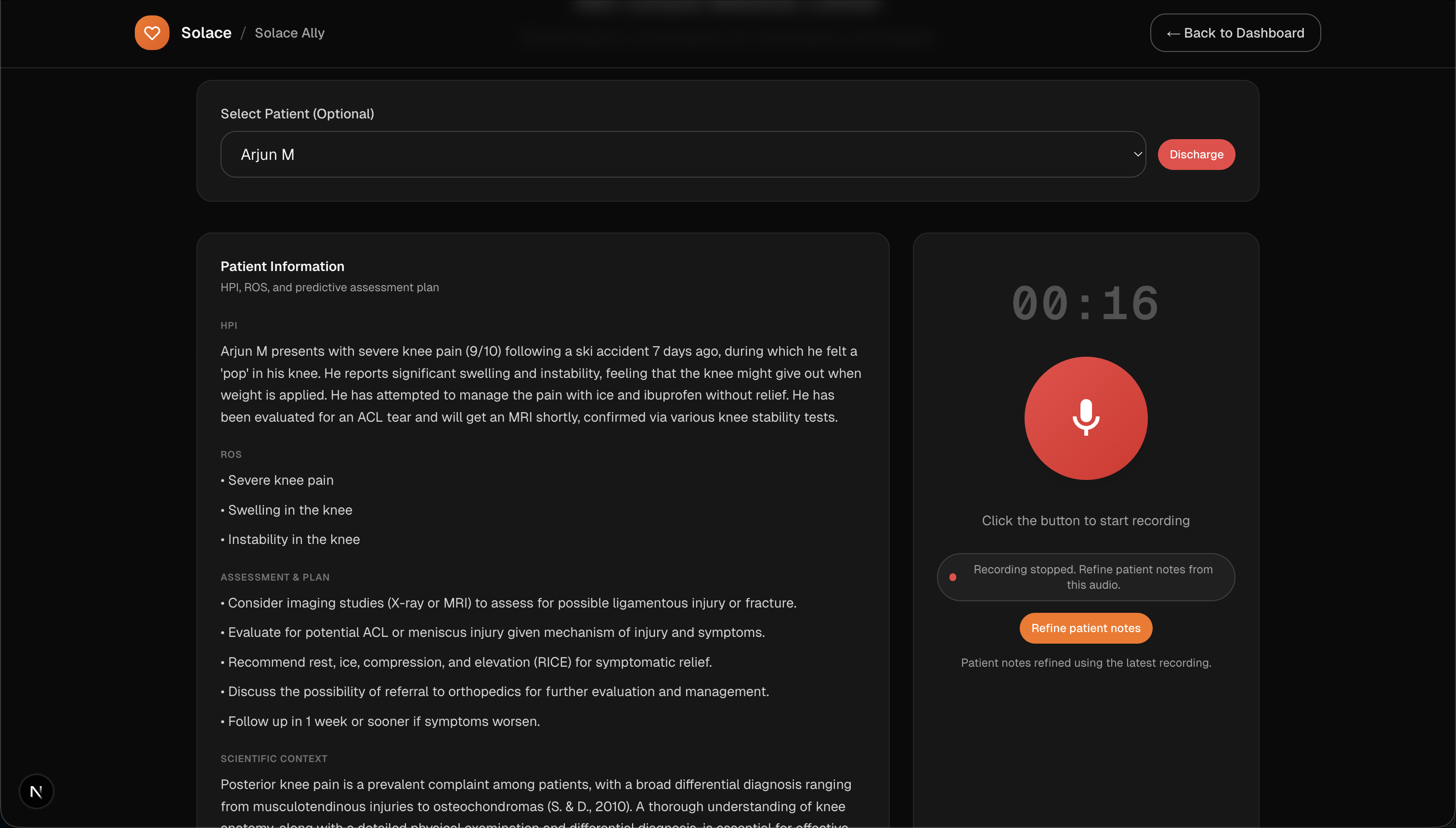
AI research + recording
-
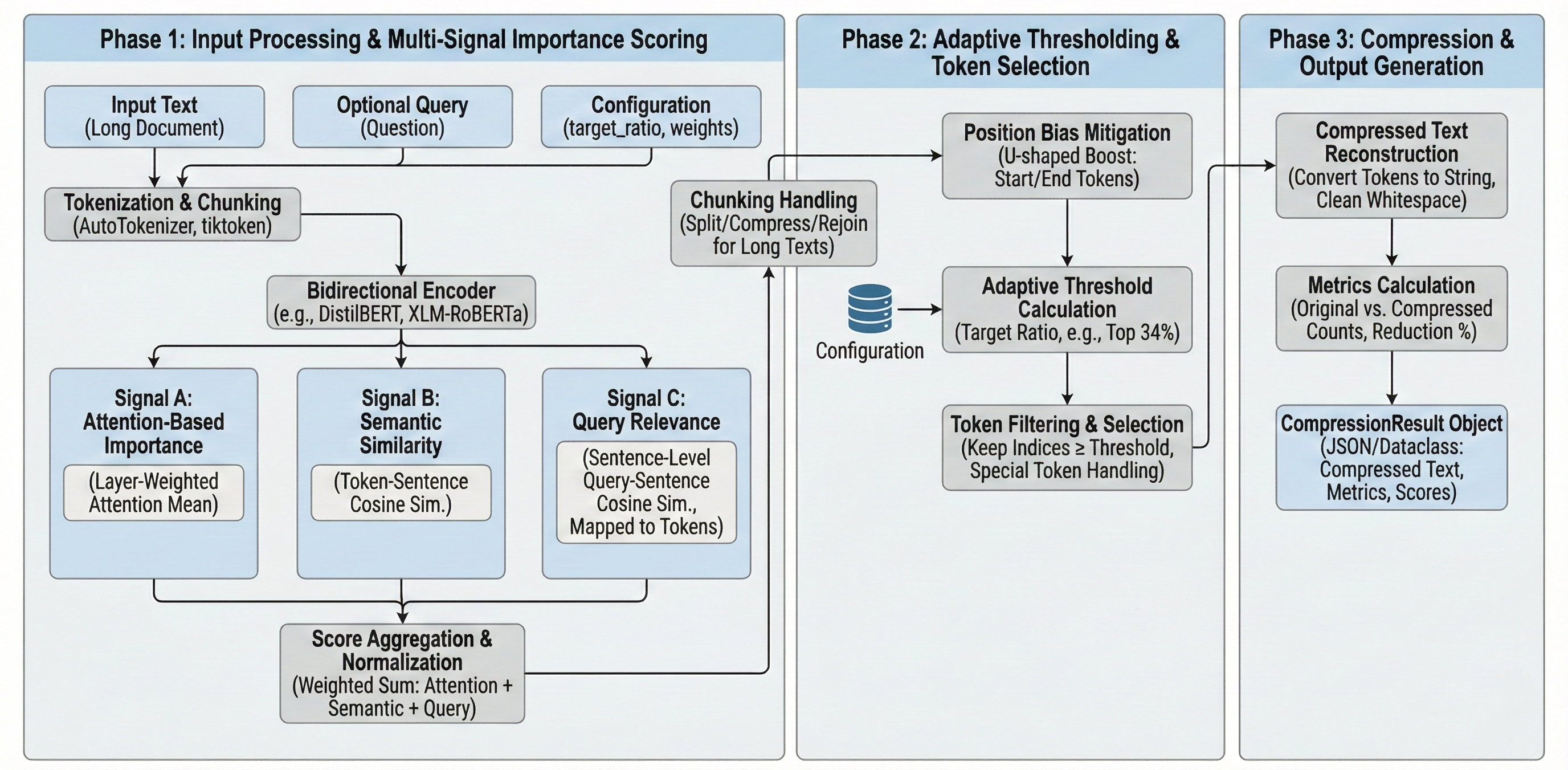
Visual Abstract of our Compression Algorithm Scratch-1
-
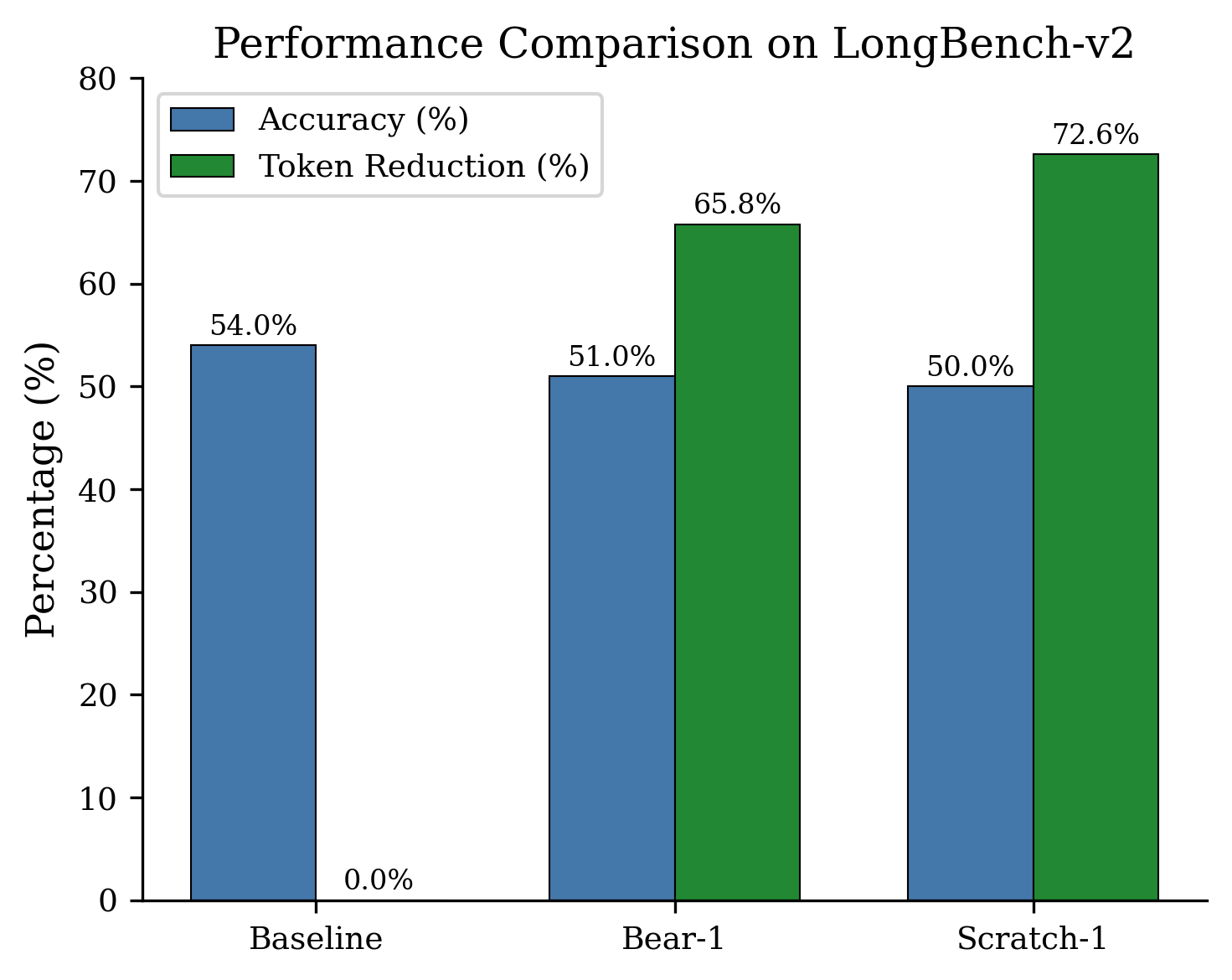
Scratch-1 Performance Comparison on LongBench-v2
-
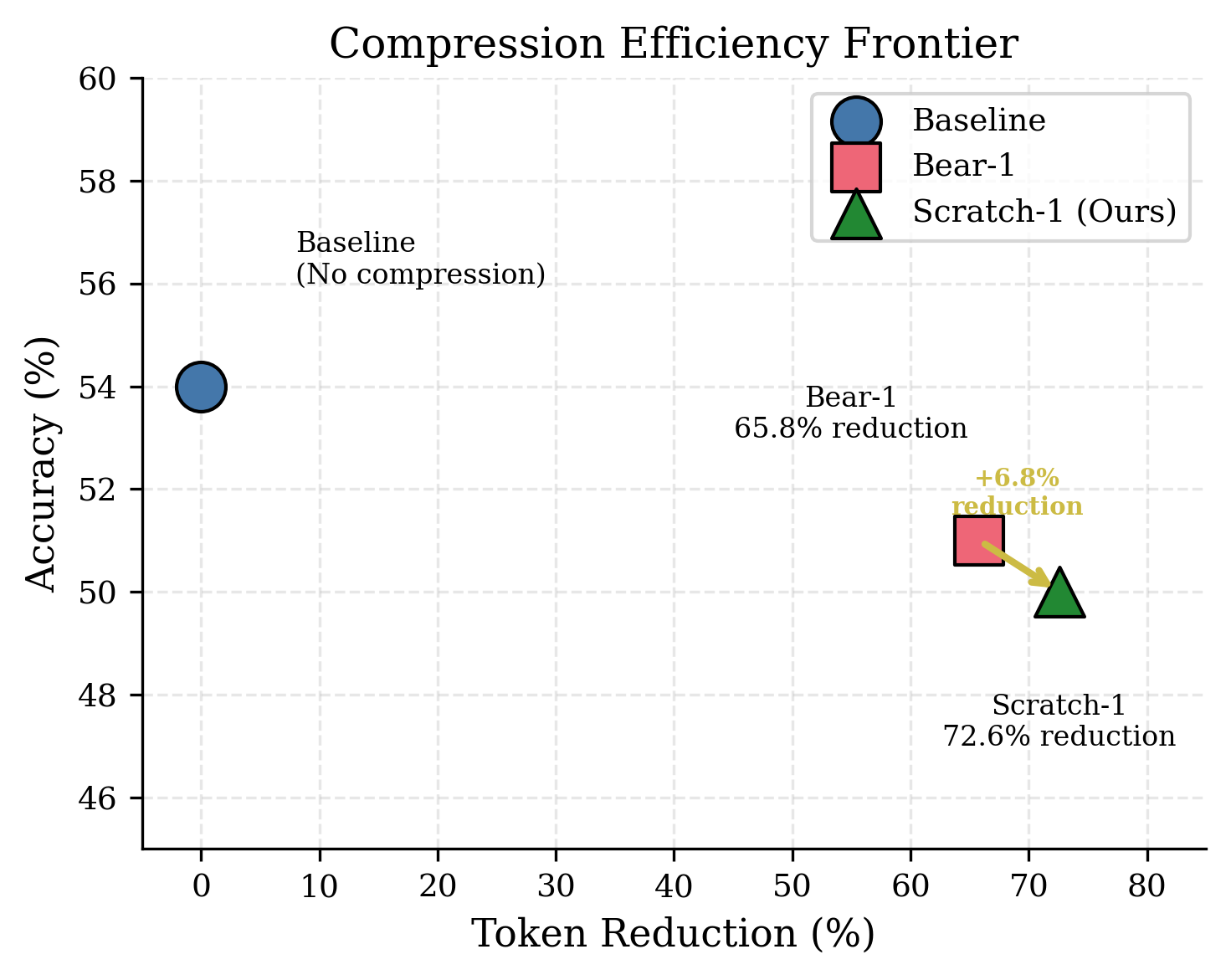
Scratch-1 Compression Efficiency compared to TheTokenCompany
Solace: A Compression-Enhanced Agentic AI Platform for End-to-End Clinical Care
Inspiration
Healthcare teams spend too much time sifting through scattered intake forms, long patient histories, organizing patients into rooms, and taking clinical notes. We wanted to build a clinic workflow that starts with smarter patient pre-screening and ends with a clear, research-informed summary in the physician's hands. By reducing door-to-door time for patients and optimizing clinical operations, we're working towards a mutually beneficial future where clinicians can focus on what really matters and patients save time. Along the way, in developing a research agent we realized the inefficiency of running LLMs on long scientific manuscripts, so we built and benchmarked a novel compression method to make the system fast and affordable.
What it does
End-to-end platform. Solace connects every step of clinic flow:
- Solace Ask (patient intake). Patients receive a clinic-specific check-in link and are guided through a dynamic, LLM-generated questionnaire with a strict 10-question cap. The intake adapts to answers, avoids repetitive prompts, and captures HPI-ready details.
- Clinical summaries. Submissions are transformed into structured HPI, ROS, and Assessment & Plan, stored alongside the patient record.
- Scientific context. We query CORE API v3 for relevant literature, compress the abstracts, and generate a clinician-friendly, citation-backed two-paragraph research context.
- Clinic operations. A drag-and-drop layout builder defines patient room capacity, and an automated queue assigns patients to open rooms. Discharge updates the queue in real time.
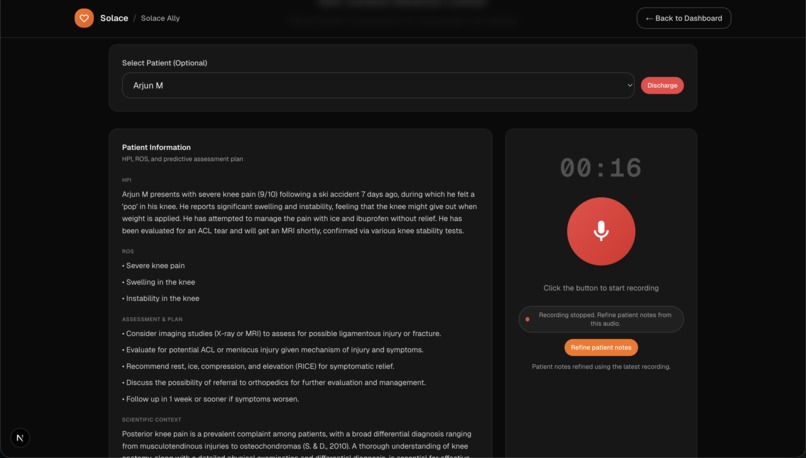
- Solace Ally (recording). Clinicians can record visits, transcribe audio, and optionally refine patient notes with transcript-aware updates.
Compression. Scratch-1 is a novel algorithm that reduces AI costs on long documents by 72.6% while preserving the information that matters most. Unlike methods that blindly remove words, it understands sentence boundaries and prioritizes content relevant to the user's question.
How we built it
Solace Platform
- Frontend: Next.js App Router with a clinic dashboard, layout editor, intake UI, and the Solace Ally recording interface.
- Backend: Supabase for auth and storage (clinics, submissions, profiles, layouts). API routes handle intake, summaries, queue management, transcription, and note refinement.
- LLM workflow:
- Intake questions are generated one-at-a-time with guardrails to cap at 10 questions.
- A medical scribe prompt converts intake Q&A into HPI, ROS, and predictive A&P.
- A research pipeline builds a CORE query, extracts abstracts, and returns a citation-backed scientific context.
- Clinic ops: Layouts define room capacity; a queue manager promotes patients into rooms and supports discharge and reset flows.
Novel Compression
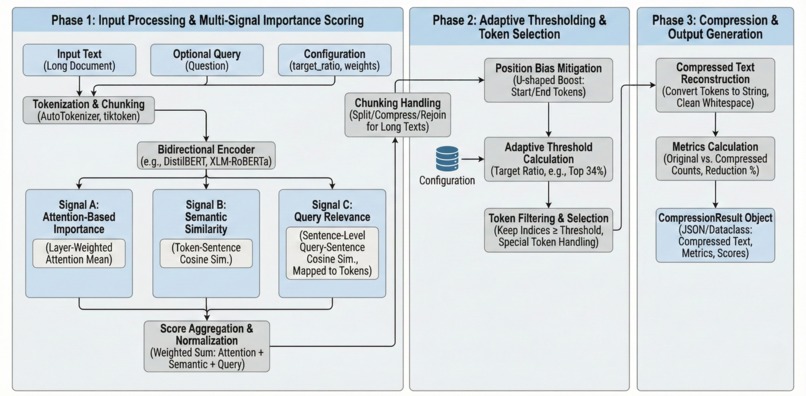
We built Scratch-1 as a three-stage pipeline:
- Semantic Segmentation -- Split documents at sentence boundaries to preserve coherent text
- Multi-Signal Ranking -- Score tokens using attention, semantic similarity, and query relevance
- Position Bias Mitigation -- Boost content at document start/end to counter the "Lost-in-the-Middle" effect
$$\text{Score}_i = 0.4 \cdot A_i + 0.3 \cdot S_i + 0.3 \cdot Q_i$$
Scratch-1 runs directly inside the pipeline before LLM calls (e.g., research abstract summarization), reducing tokens while preserving medically relevant details.
Challenges we ran into
Building the Solace platform required careful orchestration of state, queues, and LLM outputs. We had to prevent LLM intake loops, ensure per-clinic layouts were isolated, and align room capacity with queue promotion. Integrating the CORE API also required robust error handling and fallback logic when abstracts were missing or the API returned non-standard responses. We also had to normalize audio formats so transcription worked reliably.
In building Scratch-1, we had many hurdles optimizing the parameters and tradeoffs between our models to determine the best compression settings.
Accomplishments that we're proud of
- Built a full clinical intake-to-care pipeline, from patient check-in through AI summaries, layout-based rooming, and discharge.
- Designed Solace Ally so clinicians can record visits and refine the patient summary with transcript-aware updates.
- Delivered citation-backed scientific context powered by CORE, summarized into two paragraphs for quick clinician review.
Created an interactive clinic layout builder that drives queue capacity and visual room occupancy.
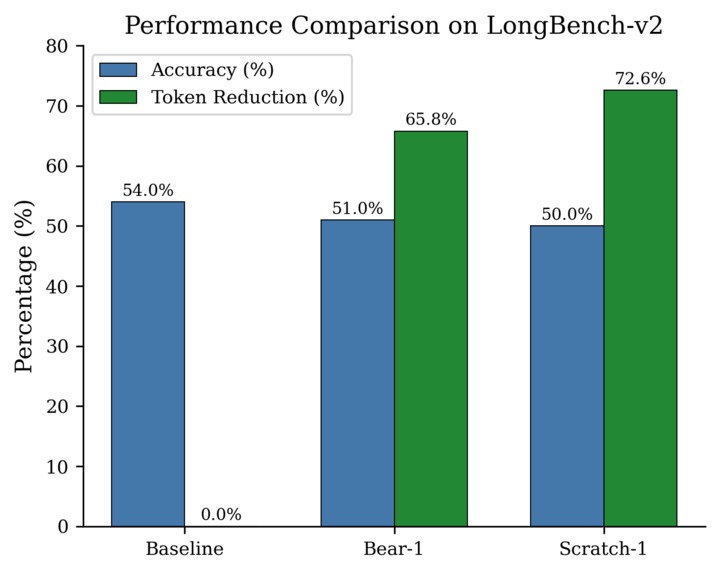
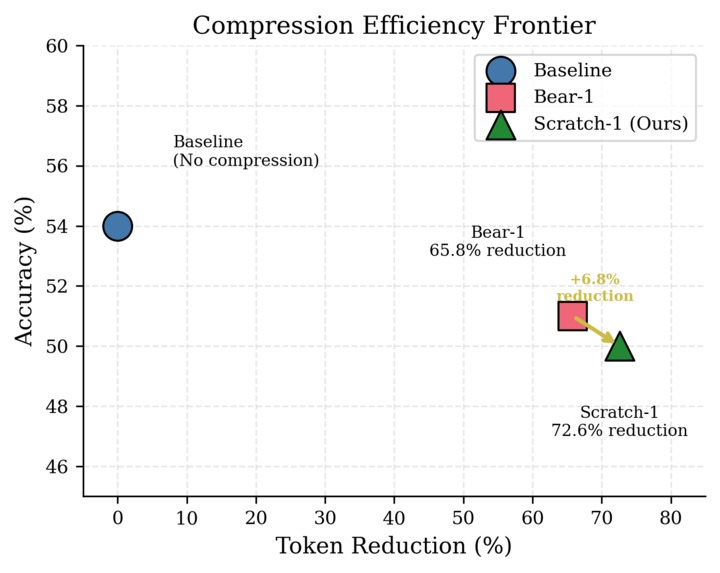
Achieved 72.6% token reduction -- 6.8 percentage points higher than Bear-1's 65.8%.
Query-aware scoring improved accuracy by 3.3 percentage points over task-agnostic compression.
Proved that respecting sentence boundaries leads to smarter compression than brute-force pruning.
What we learned
- Building reliable healthcare workflows requires guardrails at every step: question caps, deterministic JSON outputs, and explicit queue policies.
- LLM prompts are only half the battle; data normalization, error handling, and UI feedback loops are just as important.
- Integrating multiple external APIs (transcription, research, compression) demands careful fallbacks and observability.
- Compression is about understanding which tokens matter for a specific task, not just removing the most.
- Where information appears in a document matters as much as what it says (Lost-in-the-Middle effect).
- Production AI requires balancing model complexity, latency, and accuracy.
What's next for Solace: An Agentic AI Platform for End-to-End Clinical Care
We hope to have Solace adopted by clinics worldwide to streamline patient care. Next steps include model distillation for faster inference, named entity preservation for medical terms, and dynamic compression ratios that adapt to document density.
Built With
- bear-1
- core-api
- javascript
- next.js
- openai-api
- postgresql
- python
- pytorch
- react
- supabase
- tailwindcss
- thetokencompany
- typescript


Log in or sign up for Devpost to join the conversation.