About SodaAgent
Inspiration
I built SodaAgent because most in-car assistants still feel too reactive. They wait for a wake word, answer one question, and stop there. But driving is exactly the kind of environment where help should be proactive, timely, and hands-free.
I wanted to build an assistant that feels more like a co-driver than a voice command interface: something that can talk naturally, use tools in real time, remember context across turns, and reach out before the user misses something important.
What I Built
SodaAgent is an AI-powered car voice assistant built with a Flutter mobile app, a FastAPI backend, Google ADK, and the Gemini Live API.
It can:
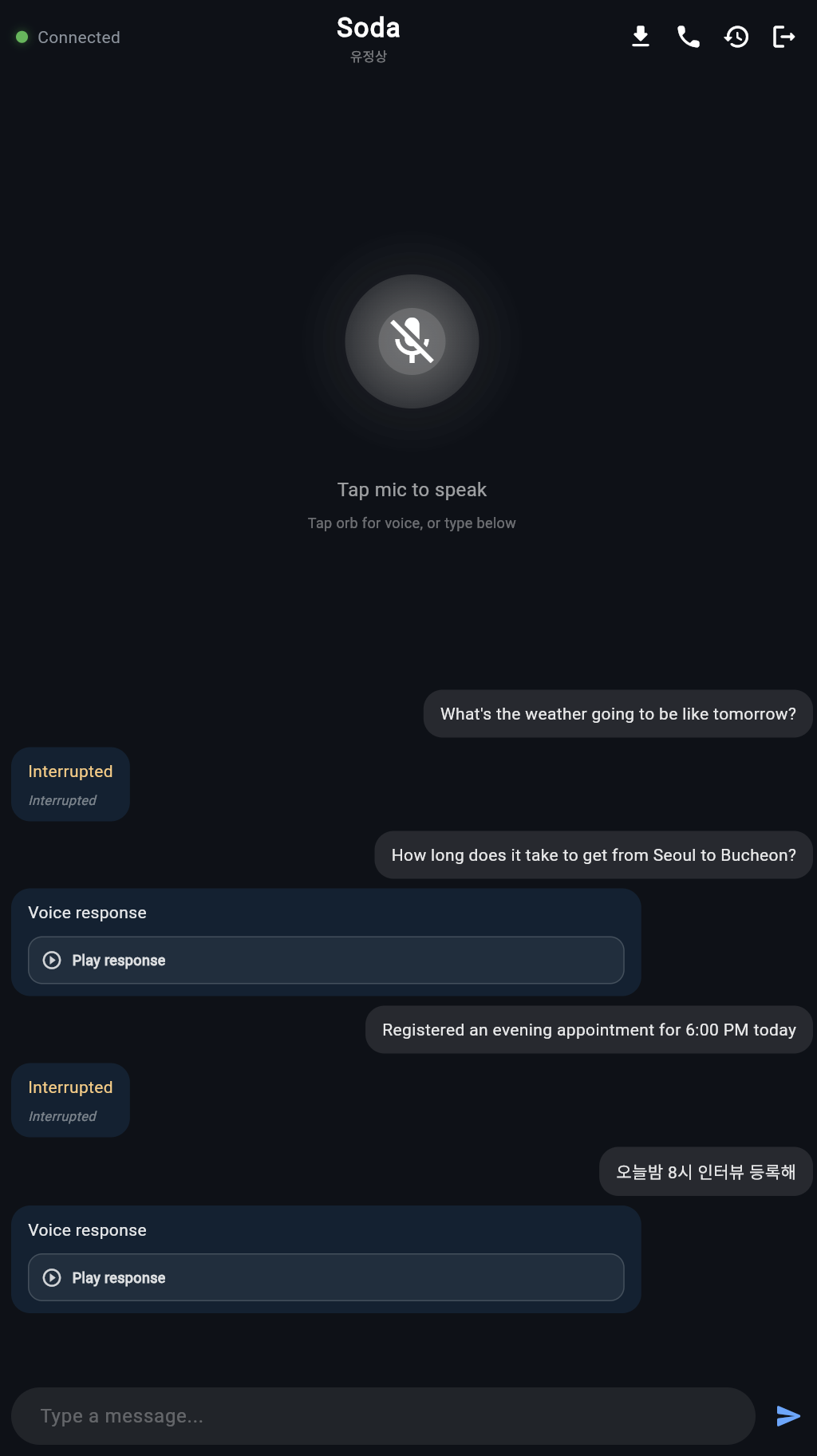
- hold real-time voice conversations through bidirectional audio streaming
- use tools for navigation, weather, calendar, reminders, todos, messaging, and vehicle status
- maintain turn-based conversation history and transcript state
- proactively deliver scheduled reminders into an active live session
- fall back to a Twilio phone call when the user is offline
What I really built was not just a voice chatbot. I built a real-time assistant system that has to coordinate live audio, tools, memory, scheduling, and delivery across multiple channels.
Architecture
I designed SodaAgent as a layered real-time architecture.
On the client side, I built a Flutter app with a voice-first interface. The app captures microphone audio, streams it to the backend over WebSocket, renders live transcripts, shows tool activity, stores session history, and lets the user replay previous assistant audio. I used Riverpod to manage the live voice session state, including connection state, active user and assistant turns, transcript updates, playback, and interruption behavior.
On the server side, I built a FastAPI backend as the authoritative source of truth for conversation state. Instead of letting the mobile client guess what is happening, the backend controls turn ownership, transcript commits, tool execution, and cancellation of interrupted assistant responses. This became essential for keeping live interactions coherent when audio, transcripts, and tool results all arrive asynchronously.
For the AI layer, I used Google ADK with the Gemini Live API for bidirectional voice interaction. One important technical constraint shaped the whole design: the live audio path does not support the same sub-agent transfer pattern I would normally use in a text-first multi-agent system. To handle that, I split the architecture into two modes:
- a live voice agent with a flat tool architecture optimized for low-latency real-time interaction
- a text-mode root agent with sub-agents for richer delegation outside the live path
That was one of the hardest and most important design decisions in the project. I could not just reuse a standard multi-agent pattern. I had to redesign the live path around the realities of streaming audio.
I also built a persistence and trigger layer for scheduled todos and reminders. That lets SodaAgent evaluate due tasks, deliver them directly into an active live session, and fall back to a Twilio phone call if the user is disconnected. In other words, the assistant is not only reactive inside the app; it can also act proactively outside the current session.
The Hard Problems I Solved
1. Making live voice feel natural
The hardest part was not getting a model to speak. It was making the interaction feel natural in real time. In a live assistant, even small delays or state mistakes are obvious. If the assistant keeps talking after the user cuts in, the experience immediately feels broken.
To solve that, I built the backend around turn-scoped conversation state. The server tracks the active user turn, the active assistant turn, and whether a response should still be allowed to continue. That gave me a reliable way to handle interruption, barge-in, and stale output.
2. Handling interruption without replaying stale audio
A real voice assistant needs to respond instantly when the user interrupts. I implemented interruption handling so the app can detect user speech, duck playback, and the backend can cancel the current assistant turn. Just as importantly, I made sure stale audio chunks from the cancelled response do not get replayed later. That sounds like a small detail, but it is one of the biggest differences between a demo that works and one that feels polished.
3. Separating live captions from real conversation history
Streaming speech produces partial transcripts constantly, but those should not be treated as final dialogue. I separated partial transcript updates from final committed turns so the UI can stay responsive while the stored conversation history stays clean and readable. This was important both for the user experience and for preserving meaningful session history.
4. Making tool use reliable in live mode
Live tool calling is harder than text-based tool calling. A tool may run correctly, but the model may not always continue with a clean spoken follow-up. I built backend fallback logic that can summarize tool results when needed, while also protecting state-changing tools from being executed twice. That let me make the system more reliable without introducing duplicate side effects.
5. Designing around platform constraints
One of the most interesting parts of the project was designing around the constraints of live agent orchestration. Since the live streaming path could not use the delegation flow I would normally prefer, I had to create a dedicated flat live agent with direct tool access. That tradeoff was not just an implementation detail; it shaped the final architecture of the whole system.
6. Extending the assistant beyond the current session
I did not want SodaAgent to be useful only while the user was actively in the app. I built a scheduled trigger pipeline so the assistant can evaluate due reminders and deliver them through the best available channel: the live session if the user is connected, or a Twilio call if not. That turned the project from a voice interface into a more proactive agent system.
What I Learned
I learned that building a voice agent is as much a systems design problem as it is an AI problem. Prompting matters, but so do event ordering, buffering, transcript commit rules, cancellation logic, and tool orchestration.
I also learned that proactive AI is not just about generating better answers. It requires memory, scheduling, delivery infrastructure, and careful decisions about when the assistant should act first. The most valuable thing I built in this project was not a single feature, but an architecture that lets those pieces work together in a way that feels calm, useful, and reliable for drivers.
Built With
- cloud
- dart
- fastapi
- firebase-authentication
- flutter
- gemini-2.5-pro
- gemini-live-api
- google-adk
- google-cloud-run
- google-maps
- python
- riverpod
- twilio
- websockets


Log in or sign up for Devpost to join the conversation.