
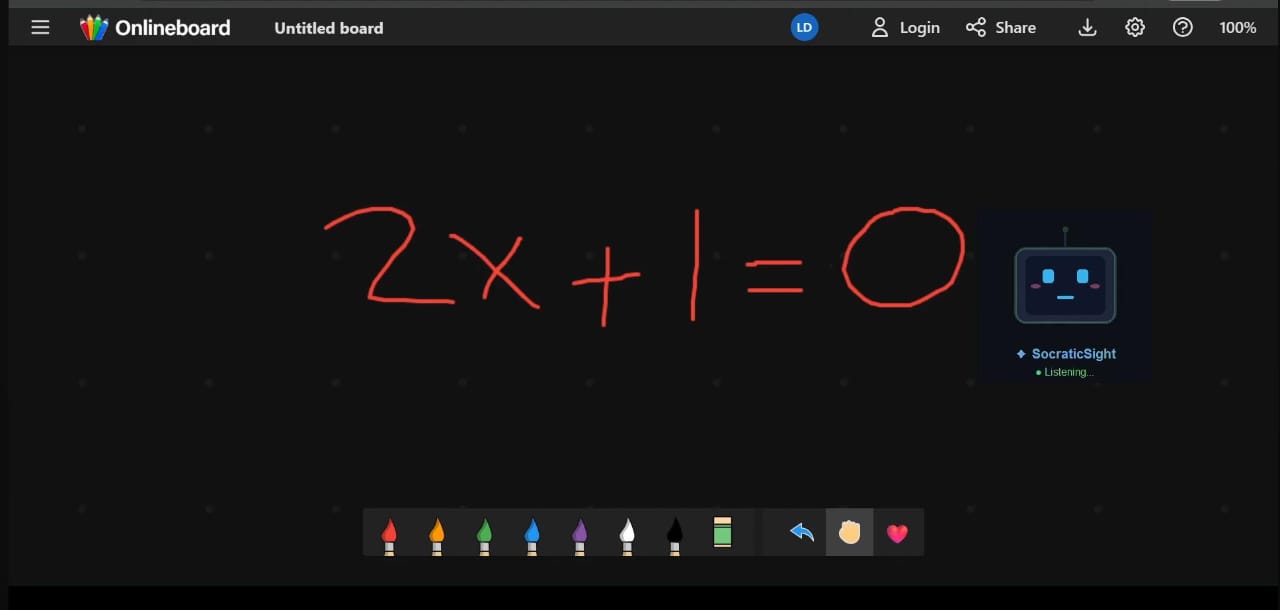
Inspiration
The traditional "text-box" AI disrupts how students actually learn. When you are analyzing a complex diagram or a dense research paper, stopping to take screenshots and type context into a browser completely shatters your focus. I built SocraticSight to make studying frictionless. By eliminating the browser tab, it emulates a human tutor sitting right next to you. It looks directly at your screen, listens to your questions, and responds in real-time with spoken explanations and generated visual aids bringing your study materials to life without ever breaking your workflow.
What it does
SocraticSight is an Edge-to-Cloud desktop tutoring agent. It runs as a lightweight, always-on-top avatar that monitors your workspace.
- Conversational AI: It utilizes the Gemini Live API for full-duplex audio streaming, allowing for natural, interruptible voice conversations.
- Workspace Vision: On command, it captures your active desktop and uses Gemini's multimodal vision capabilities to provide context-aware guidance on what you are looking at.
- Dual-Window Whiteboard: It dynamically spawns separate floating windows: one for text and math, and another for rendering high-fidelity educational diagrams generated via Vertex AI.
- Cloud Persistence: When the session ends, it automatically summarizes the interaction and securely uploads the transcripts and generated diagrams to Google Cloud Storage for future review.
Development Process
I utilized a decoupled Edge-to-Cloud architecture to maximize responsiveness while fully leveraging Google's enterprise AI and cloud infrastructure. The core intelligence is powered by the new Google GenAI SDK, connecting directly to the Gemini 2.5 Flash Live API via WebSockets. This handles the ultra-low latency, native audio-to-audio interaction and real-time screen understanding. For the visual generation and data persistence backend, I integrated Google Cloud Platform (GCP). The application routes visual prompts directly to Vertex AI (using the Imagen 3 model) and securely archives all session artifacts to Google Cloud Storage (GCS).
Challenges
The main challenge was orchestrating the real-time, multimodal data streams required by the Gemini Live API. Managing continuous audio input/output alongside live screen captures in a single WebSockets session required careful synchronization to maintain the "live" feel without latency or connection drops. Additionally, smoothly bridging the edge client with the GCP backend—specifically ensuring that prompts were properly routed to Vertex AI for image generation while the Gemini Live session was actively running—required robust state management and seamless integration of multiple Google Cloud services.
Accomplishments
I am incredibly proud to have successfully broken the conventional chat interface paradigm by building a fully spatial, voice-first desktop assistant. Designing a system that seamlessly hands off tasks between Gemini 2.5 Flash (for live reasoning and audio) and Vertex AI (for high-fidelity diagram generation) feels like a massive leap forward in user experience. Above all, achieving a near-instantaneous, natural conversational flow using the Gemini Live API makes the agent feel genuinely intelligent and present in the workspace.
Key Learnings
I significantly deepened my understanding of building Edge-to-Cloud architectures using Google Cloud Platform. Working with the Google GenAI SDK taught me how to manage complex multimodal payloads combining audio, text, and image byte streams in a continuous, real-time session. From an educational perspective, I learned that providing Gemini with direct visual access to the student's screen drastically reduces prompt engineering friction and eliminates hallucinations, leading to vastly superior and highly contextual tutoring outcomes.
Built With
- gemini-live-api
- google-cloud
- google-genai-sdk
- imagen-3
- pillow
- pyaudio
- python
- tkinter
- vertex-ai


Log in or sign up for Devpost to join the conversation.