🪞 Socratic Mirror Agent
🌟 Inspiration
The best teachers don’t give answers — they ask questions.
For centuries, the Socratic method has helped people truly understand concepts by guiding them with questions instead of explanations. But modern learning is mostly passive: videos, notes, and one-way instruction.
We noticed a clear gap:
- Students consume content but don’t internalize it
- Interview candidates know material but fail under pressure
- Learners lack a real-time, adaptive human presence
So we asked:
What if AI didn’t just answer questions — but helped you think?
That idea became Socratic Mirror Agent — an AI that reflects your understanding back at you and helps you improve in real time.
🎯 Live Agents Track (Real-Time Interaction)
Socratic Mirror Agent is built specifically as a real-time, interruptible AI agent using Gemini Live API and deployed on Google Cloud.
- 🗣️ Natural voice conversations with streaming audio (not delayed responses)
- ✋ Barge-in support — users can interrupt the AI mid-sentence, and it adapts instantly
- ⚡ Low-latency streaming pipeline (50ms audio chunks via WebSockets)
- 🔄 Bidirectional interaction — continuous listening and responding
Unlike traditional chatbots, our system maintains a live conversational loop, making the interaction feel fluid, human, and responsive.
🚀 What it does
Socratic Mirror Agent is a multimodal AI coaching system with three modes:
🧠 Socratic Tutoring
- Teaches using guided questions only (no direct answers)
- Adapts to confusion in real time
- Generates live visual aids (steps, equations, diagrams)
- Reinforces learning through continuous checks
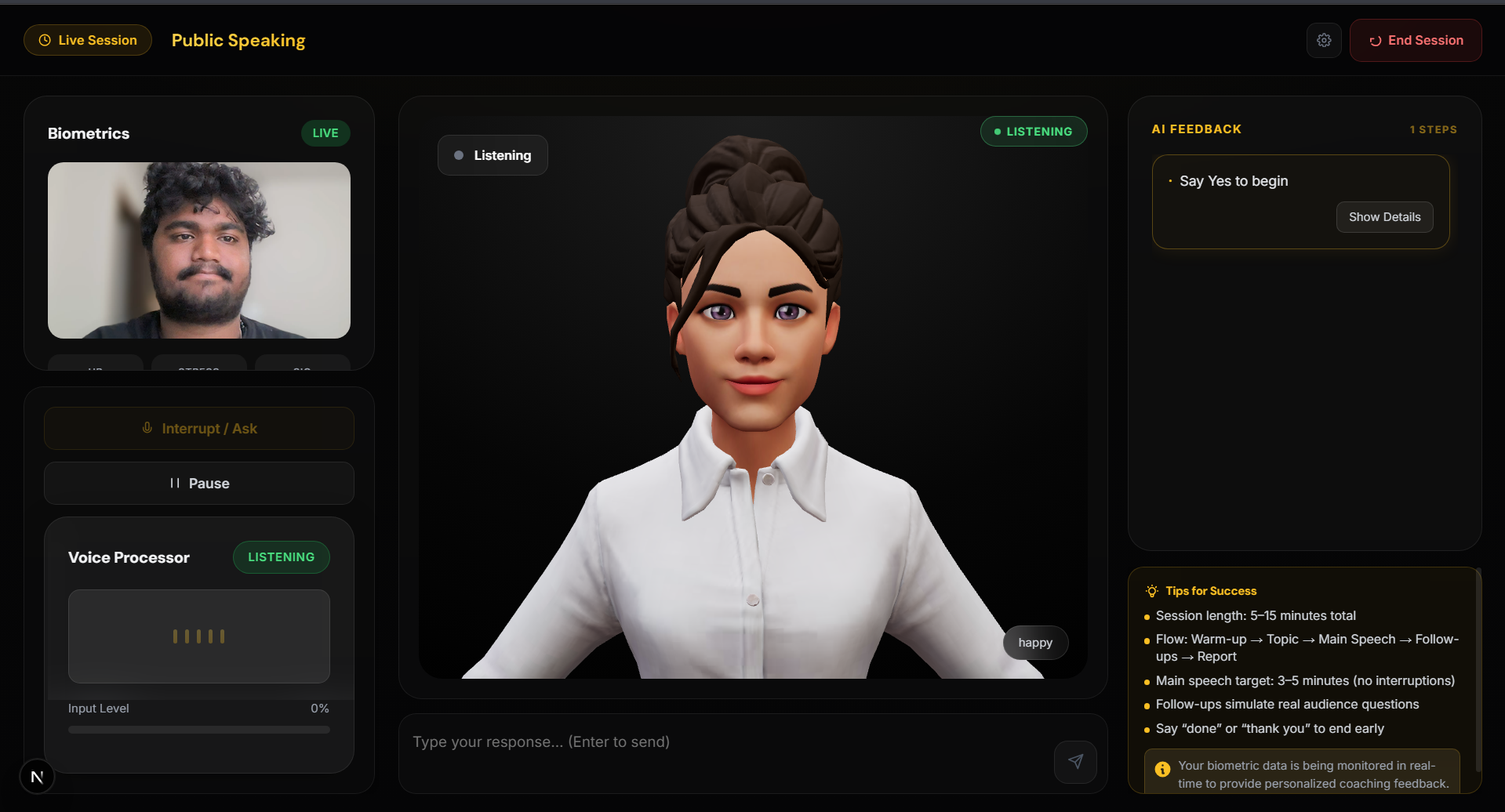
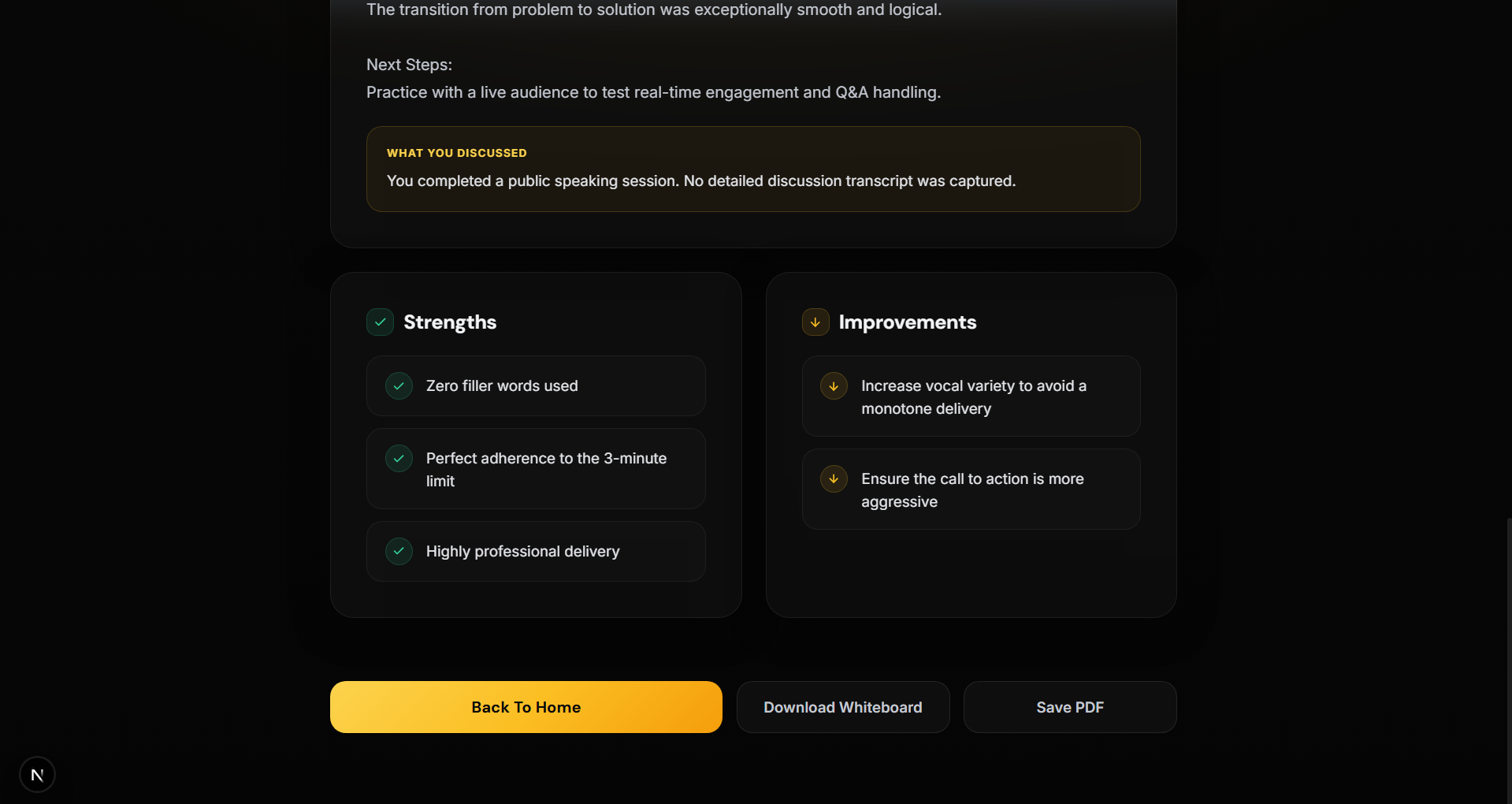
🎤 Public Speaking Coach
Real-time feedback on:
- filler words
- pacing
- delivery
Timestamped improvement suggestions
💼 Interview Prep
- AI interviewer that adapts based on your answers
Covers:
- behavioral
- technical
- follow-up questions
Uses job description + resume context
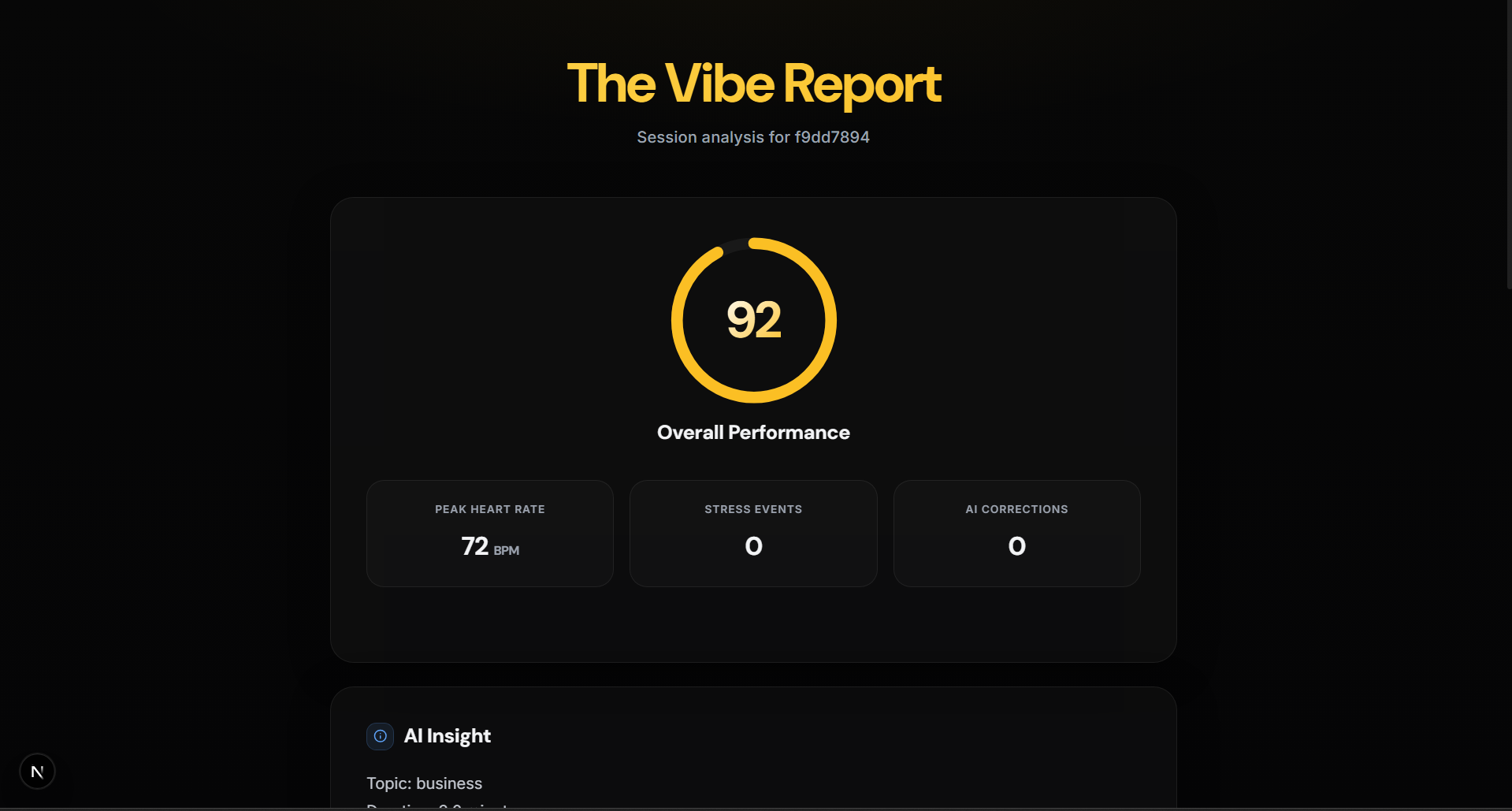
📊 Vibe Report
After each session:
- Performance score
- Strengths & weaknesses
- Actionable improvements
🛠️ How we built it
⚙️ Architecture Overview
Frontend
- Next.js + React + React Three Fiber
- 3D avatar (Ready Player Me) with real-time lip sync
Backend
- FastAPI deployed on Google Cloud
- Gemini 2.0 Flash + Gemini Live API
- WebSocket-based streaming system
🔴 Real-Time Audio Pipeline (Core to Track)
User Voice → AudioWorklet → WebSocket → Gemini Live API
→ Streaming AI Response → Viseme Timeline → Avatar Lip Sync
- Audio is streamed in small chunks (~50ms) for low latency
- Gemini Live enables continuous bidirectional streaming
- Playback + animation are synchronized in real time
🧩 Agentic Tutoring Engine (Core Innovation)
We built a state-driven decision engine that tracks:
- Confusion signals
- Correct answer streaks
- Progress depth
Instead of relying on prompting alone, we inject hidden behavioral hints into the model:
| Hint | Trigger | Result |
|---|---|---|
| re_explain | Confusion detected | New explanation style |
| provide_example | No example yet | Adds concrete example |
| ask_socratic | High confidence | Deeper probing |
| suggest_path | Topic drift | Guided exploration |
👉 This makes the AI feel like a real adaptive tutor, not a chatbot.
🎯 Real-Time Multimodal Inputs
- Voice (speech + tone)
- Optional biometric signals (stress, engagement)
- Future-ready for facial expression analysis
⚡ Challenges we ran into
🚨 Performance Issues
- CSS blur effects caused full CPU repaints
- Fixed by shifting to GPU-friendly transforms
- Result: stable 60 FPS UI
👄 Lip-Sync Drift
- Audio and visemes were misaligned
- Fixed by syncing timeline to actual audio playback start
- Result: frame-accurate lip sync
✋ Real-Time Interruption (Barge-In)
Interrupting AI mid-response required:
- cancelling active audio streams
- resetting state safely
- resuming conversation seamlessly
This was critical to achieving natural conversation flow
🎙️ Voice System Limitations
- No gender metadata in Web Speech API
- Solved using cross-platform voice name mapping
🔇 Noise Handling
- Background sounds interfered with AI input
Added:
- RMS-based filtering
- Intent detection
🏆 Accomplishments that we’re proud of
- Built a true real-time AI agent (not just a chatbot)
- Seamless interruptible voice interaction (barge-in)
- Integrated Gemini Live API + Google Cloud deployment
- Real-time bidirectional voice + animation pipeline
- Sub-frame accurate avatar lip sync
- Smooth UI performance even on low-end devices
📚 What we learned
LLMs default to explaining — not guiding → Requires explicit behavioral control systems
Prompting alone isn’t enough → State + logic + prompts = real intelligence
Real-time AI requires:
- streaming architectures
- latency optimization
- synchronization handling
Browser performance is often about rendering layers, not code
🔮 What’s next
- 👁️ Facial expression–based confusion detection
- 🧠 Persistent learning profiles
- 👥 Multi-user collaborative learning mode
- 📖 Auto-generated learning curricula
- 🏫 LMS integrations (Canvas, Moodle, Google Classroom)
💡 Why it matters
Socratic Mirror Agent shifts AI from:
❌ Answer machine → ✅ Thinking partner
Instead of replacing learning, it amplifies how humans learn best — through questioning, reflection, and discovery.
🧑💻 Built With
- Gemini Live API
- Google Cloud
- Next.js
- React
- Three.js / React Three Fiber
- FastAPI
- WebSockets
- Web Audio API
Built With
- asyncio
- audioworklet-api
- css-modules
- fastapi
- gemini-2.0-flash
- gemini-live-api
- google-cloud-text-to-speech-api
- google-gemini-api
- next.js
- python
- react
- react-three-fiber
- ready-player-me
- tailwind-css
- three.js
- typescript
- web-speech-api
- webgl
- websockets



Log in or sign up for Devpost to join the conversation.